Schema Evolution and Data Quality Management in the Medallion Model

You get new problems when your data sources change and grow in a modern data lakehouse. Schema drift happens a lot. This makes it hard to keep your data neat and trustworthy. Recent surveys say that organizations see schema changes about every 3 days. This means you must always pay attention.
Organizations see schema changes about every 3 days.
Schema drift problems happen a lot in modern data lakehouses.
The Medallion Model helps you deal with these changes. You need strong rules and good habits, especially in the Silver layer. This keeps Data Quality Management working well as your data changes.
Key Takeaways
Schema drift happens a lot. Organizations see changes every 3 days. Watch closely to keep data quality high.
The Medallion Model has Bronze, Silver, and Gold layers. Each layer helps manage data quality. Use them well to keep data clean and reliable.
Set up strong schema evolution rules. This helps handle changes without breaking your data pipeline. It keeps your data safe and easy to use.
Check data quality at each layer. Finding problems early stops big mistakes. It also helps make sure reports are correct.
Use new tools like Delta Lake and Apache Iceberg. These tools help manage schema changes well. They also keep data correct and fast.
Medallion Model Layers and Data Quality
Bronze, Silver, Gold Overview
The Medallion Model works in steps to help with data. Each layer has a different job to do. The table below explains what each layer is for:
Layer | Main Functions and Responsibilities |
|---|---|
Bronze | - Stores raw, unaltered data from various sources. |
Silver | - Cleanses and filters raw data for usability. |
Gold | - Contains highly refined and aggregated data for business use. |
First, you use the Bronze layer. This is where you keep all your raw data safe. You do not change anything here. Next, you move to the Silver layer. Here, you clean up the data and check for mistakes. You make sure the data is ready to use. Last, you reach the Gold layer. This layer has the best data for business. It is ready for reports and making choices.
Layered Approach to Data Quality
You need a good plan for Data Quality Management at every step. Each layer checks and improves data in its own way. Here are some ways the Medallion Model helps with data quality:
Watching your data all the time makes it more reliable. This helps lower risks and stops bad decisions.
Bronze, Silver, and Gold layers need their own ways to watch data.
Using best practices helps you find and fix problems fast.
In the Bronze layer, you make sure data is complete and correct. The Silver layer checks if changes to data work right. The Gold layer makes sure data fits what the business needs. This step-by-step way helps you find problems early. It keeps your data trustworthy. Data Quality Management is easier because you fix things at each step, not just at the end.
Tip: The Medallion Model also helps you see where your data comes from. This makes it easier to track changes and keep your data safe.
Schema Evolution in the Medallion Model

What Is Schema Evolution?
Sometimes, your data changes how it looks or acts. Schema evolution means you can change a table’s setup for new data. This helps keep your data useful and safe. In a data lakehouse, schema evolution lets you update tables without stopping the data flow. You can add columns or change data types as sources grow. You do not lose old data when you do this. Backward compatibility is important because you want all your data to stay together.
Note: Schema evolution helps you handle changes in data structures. You keep your data pipelines working even when sources change.
Here are some main ideas about schema evolution:
You can change tables to fit new data sources.
You keep your data pipelines running without stopping.
You protect old data from being lost.
You make sure new data matches what you already have.
Impact of Schema Drift
Schema drift happens when your data sources change over time. You might see new columns, different data types, or small changes in data. These changes can cause problems if you do not manage them well.
Common reasons for schema drift are:
New columns added to your data sources.
Changes in data types, like numbers turning into text.
Different sources using slightly different schemas.
Handling new columns without breaking your data flow.
Keeping metadata tables matching your real data.
Weak data governance causes lots of changes.
You also get problems when raw data does not follow a plan before you process it. If you do not fix problems early, your data pipelines can break. This can cost you more money and time. Poor communication with business owners can make schema drift worse.
Schema drift can hurt your data quality. You might see:
Data that does not match across tables.
Broken reports and analytics.
More technical debt, which makes your data harder to manage.
Tip: Watch for schema drift and fix problems early. This keeps your data clean and your reports correct.
Silver Layer’s Role in Schema Changes
The Silver layer helps you handle schema changes safely. You do not make random changes here. You use a controlled pipeline to handle updates. This keeps your data steady and trustworthy.
The Silver layer does these things:
It checks and enforces schema changes.
It stops random changes that could break your data.
It keeps your data governance strong.
It lets you change and improve data in a planned way.
You see fewer errors when you use schema versioning in your Silver layer. For example, a big telecom company cut schema errors by 70% during a migration project. Many groups use schema registries to track changes. This cuts data integration problems by half. Technologies like Apache Parquet help you work with new columns and keep queries fast. Schema-on-read lets you store raw data and use schemas only when needed.
Callout: The Silver layer is your main tool for Data Quality Management. You keep your data clean and ready for business by handling schema changes here.
Here is a table showing how the Silver layer helps with schema changes:
Silver Layer Feature | Benefit |
|---|---|
Controlled pipeline | Stops random changes and keeps data safe |
Schema enforcement | Keeps data consistent |
Schema versioning | Tracks changes and reduces errors |
Schema registry | Cuts integration issues |
Support for new columns | Keeps queries fast and flexible |
You lower risks when you manage schema evolution well. If you do not enforce schemas, you might see many different schemas in your files. This can confuse your data readers and cause problems. Without a strong governance layer, you cannot trust your data.
Reminder: Use the Silver layer to control schema changes. This keeps your data reliable and your analytics strong.
Managing Schema Changes Across Layers
Common Schema Modifications
You will notice different schema changes as data moves. Some changes happen a lot and can cause trouble if not managed. The table below lists the most common schema modifications:
Schema Modification Type | Description |
|---|---|
New Field | A new field might show up in Bronze. This can cause problems later on. |
Type Mismatch | Wrong data types can make Spark jobs fail. This hurts data quality. |
Column Rename | Changing column names can break Silver and Gold layer steps. |
You should look for these changes often. If you find them early, you can stop mistakes before they reach reports.
Schema Evolution Policies
You need clear rules to handle schema changes. Good rules help keep your data safe and correct. Here are some important policies to follow:
Policy Type | Description |
|---|---|
Schema Management | Use Apache Iceberg to manage schema changes. This keeps your data correct. |
Data Integration | Follow best practices for data integration. This helps schema changes work well in all layers. |
Use tools like Git to track schema changes.
Keep a record of changes to tables like 'ProductSales'.
Tip: Strong schema rules help you avoid sudden problems. They also help Data Quality Management by keeping data the same everywhere.
Handling Changes in Bronze, Silver, and Gold
Each Medallion layer needs its own way to manage schema changes. You must treat each layer differently to keep your data pipeline strong.
Layer | |
|---|---|
Bronze | Schema evolution without impacting downstream consumers. |
Silver | Schema evolution managed; contracts with sources. |
Gold | Schema-by-contract tied to metrics layer/semantic model. |
Bronze: Use schema-on-read. This layer can handle drift and accepts all data. Let tools like Auto Loader evolve schemas and flag changes for review.
Silver: Manage schema changes with clear contracts. Do not allow random changes. Define and enforce strict data rules.
Gold: Use schema-by-contract. Tie schemas to business metrics and keep them stable for reporting.
Note: Good schema change management keeps your data pipeline reliable. If you do not control changes, you risk breaking important reports, especially during busy times like month-end.
You can improve Data Quality Management by setting up strong governance. Use a federated governance model to balance central rules with team flexibility. This helps everyone share data safely and keeps your data high quality.
Data Quality Management Strategies
Data Quality Challenges by Layer
Each Medallion Model layer has its own data quality problems. You will see different risks in each layer. If you know what to watch for, you can fix problems early.
Here is a table that lists common data quality problems in each layer:
Layer | Common Data Quality Challenges |
|---|---|
Bronze | Data ingestion issues: not enough rows, delays, schema changes, and structure problems. |
Silver | Missing or incomplete records that hurt merging and deduplication. |
Gold | Late data that causes old insights and wrong time-based numbers. |
Silver | Transformation problems that bring new issues like data type mismatches and bad joins. |
The Bronze layer often has trouble with raw data. Sometimes, data comes late or is missing parts. The Silver layer has missing records and mistakes from cleaning data. The Gold layer can give wrong business answers if data is late or numbers do not match.
You can also look at these problems by how they show up in your data:
Layer | Description | Data Quality Issues Manifestation |
|---|---|---|
Bronze | Raw data comes in without any changes. | Data might be missing or not match because there is no checking. |
Silver | Data gets cleaned and changed, with schema checks and deduplication. | Problems can come from wrong changes or schema mismatches. |
Gold | Data is grouped and ready for business use and BI tools. | Bad grouping can give wrong answers for business. |
You need to check for these problems at every step. If you find them early, your data pipeline stays healthy.
Monitoring and Validation Best Practices
You can keep your data clean by using good monitoring and validation. Each Medallion layer needs its own checks and tools. Do not wait until the end to check your data. Test your data early and often.
Here are some good ways to check and watch your data quality:
Bronze Layer:
Make sure the data matches the schema you expect.
Keep bad records away from the rest of your data.
Watch for big changes in how much data you get.
Check timestamps to see if data is fresh.
Look for missing records and find duplicates.
Make sure the data source is right.
Silver Layer:
Run checks to find missing values.
Remove duplicate records.
Check that data types are what you want.
Make sure joins and changes do not make new mistakes.
Check that numbers are in the right range.
Keep links between tables correct.
Gold Layer:
Make sure all business rules are followed, like revenue being positive.
Compare your final data to trusted sources.
Run checks to see if reports match the data.
Check that grouped numbers and metrics are right.
Tip: Use last-stage checks to make sure your data is complete and organized before sharing.
You should set up alerts to catch problems fast. For example, use alerts for late data updates. If data is late, you get a message right away. Tools like Lightup use AI to find strange data and send alerts. These tools help you fix problems quickly.
Alert Mechanism | Description |
|---|---|
Set up alerts to tell you when data is late or old. |
Tool | Features |
|---|---|
Lightup | Uses AI to find strange data, send alerts, and help fix problems in your system. |
Modern data engineering uses two main testing ideas. Shift Left testing means you check your data early in the pipeline. You find problems before they move forward. Shift Down testing means you check the whole data path, from start to finish. This makes sure your system works well all the way through.
You can follow these steps for strong Data Quality Management:
Test new features and changes before they go live.
Check data quality while your pipeline is running.
Use both Shift Left and Shift Down testing to find problems early and late.
Watch how your pipeline is working to find slow spots.
Set up ways to handle errors and try again if something fails.
Remember: Always watch your data and use fast alerts. This keeps your data pipeline strong and protects your business from bad data.
Tools and Implementation Guidance
Technologies for Schema Evolution
There are many tools that help with schema evolution in a data lakehouse. These tools let you change how your data looks without breaking your pipeline. You do not lose old data when you use them. Here are some popular technologies:
Apache Iceberg
Snowflake
Parquet and ORC formats
Delta Lake and Apache Iceberg are special because you can update your schema without changing all your data files. You can add new columns or change data types. Your queries will still work after these changes. Glue Catalog helps you keep track of changes and manage metadata as your data grows.
Tip: Delta Lake with Apache Iceberg is great for big datasets. You can handle schema changes and keep your queries working well.
The table below shows how Delta Lake and Apache Iceberg help with schema evolution and data quality:
Tool | Schema Evolution | Data Quality Management |
|---|---|---|
Delta Lake | Lets you change schema without rewriting data files. | Makes sure schema rules keep data quality high. |
Apache Iceberg | Lets you update metadata without changing data files. | Gives you more ways to manage data quality. |
Implementing Data Quality Controls
You can use these tools to set up strong checks for data quality at every layer. Delta Lake and Apache Iceberg work for both batch and real-time data. This means your pipeline keeps running even when your data sources change.
Let’s look at an example. Imagine you work for a retail company. You want to add new fields like "average time spent per session" and "preferred device" to customer profiles. You need old reports to keep working. You do not want ETL jobs to break. You also want dashboards to show the right numbers after the change. Modern tools help you make these changes and keep your data quality high.
You can follow these steps to use schema evolution and data quality management in your pipeline:
Use Delta Lake or Apache Iceberg to track schema changes.
Update ETL jobs so they handle new fields.
Set up checks to make sure new data fits your rules.
Test dashboards and reports to see if they still work.
Use Glue Catalog to manage metadata and keep everything in sync.
Remember: Good tools and careful planning help you keep your data pipeline healthy and your business decisions correct.
You are important for keeping your data pipeline strong. Schema evolution stops you from losing data without knowing. It also helps prevent broken transformations and confusion for people who use data. Modern tools help you change things fast and keep your data safe.
Automated schema detection helps your ETL work well.
Backward and forward compatibility keeps your reports safe.
Flexible frameworks like Parquet and Avro help you handle changes.
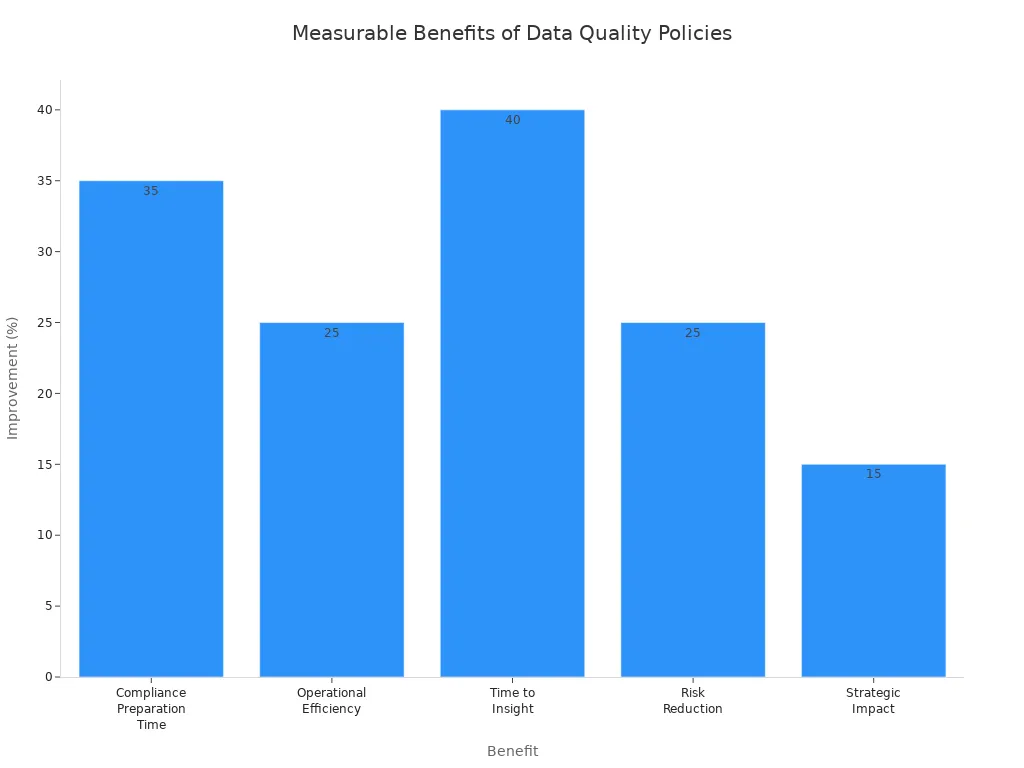
When you use strong rules and good tools, you get real results:
Benefit | Measurable Impact |
|---|---|
Compliance Preparation Time | Reduces by 35% |
Operational Efficiency | 20–30% fewer manual support hours annually |
Time to Insight | up to 40% faster from event to action |
Risk Reduction | 25% fewer costly outages |
Strategic Impact | up to 15% better planning and budgeting |
Follow these best practices to build a strong and high-quality data pipeline. This will help your business reach its goals.
FAQ
What is schema drift, and why should you care?
Schema drift happens when your data changes shape over time. You might see new columns or different data types. If you ignore schema drift, your reports can break and your data can become unreliable.
How does the Medallion Model help you manage data quality?
You use the Medallion Model to check and clean your data at each layer. Bronze keeps raw data safe. Silver fixes errors and enforces rules. Gold prepares data for business use. This step-by-step process helps you catch problems early.
Can you add new columns without breaking your pipeline?
Yes! Tools like Delta Lake and Apache Iceberg let you add columns safely. You keep your old data and your reports keep working. Always test changes before you share data with others.
What should you do if you find bad data in the Silver layer?
You should fix errors right away. Remove duplicates, fill missing values, and check data types. Set up alerts to catch problems early. This keeps your data clean for business use.
See Also
Emerging Trends in Decentralized Metadata Management for 2025
Strategic Methods for Effective Data Migration and Implementation
Comprehending the Fundamentals of Cloud Data Architecture
