Traditional Open-Source Spark Challenges
Low Efficiency, High Resource Consumption
Built on JVM, complex query optimization suffers, leading to low resource utilization and inadequate performance.
High Complexity, Inconsistent Results
Relies on multi-component ecosystem, resulting in high integration complexity, long development cycles, and poor data consistency.
High Technical Barrier & Heavy Maintenance
Requires expert tuning, upgrades, issue fixes—especially for large-scale data, small‑file compaction, and high‑concurrency low‑latency demands.
High Additional Dev Investment
Organizations must build custom scheduling, data lineage, and governance systems on top of open‑source Spark.
Why Singdata Lakehouse Stands Out
A next‑generation, cloud‑native data platform with a unified, fully managed engine—designed for zero‑ops
Leverages compute‑storage separation and serverless elastic resources for:
10x performance improvement
3x cost reduction
Supports all scenarios:batch, stream, ad‑hoc query, real‑time analytics, and log search—with a single engine and built-in tooling
Auto-scaling, pay‑per‑use, auto‑start/stop
Native vectorized engine with incremental compute
Auto-managed storage, data modeling optimization (AutoMV)
Turnkey integration, unified metadata, SDK supports extensibility
Seamless Roadmap: From Spark to Next-Gen Lakehouse
Option A: In-Place Acceleration
Start with a plug-in acceleration layer. Non-invasive, low-cost, and immediate performance uplift—perfect for customers who want quick wins without disruption.
Seamless Integration
Non-invasive, plug-and-play architecture that integrates smoothly with your existing platform.
Performance Gains
Delivers dramatic query acceleration with a cost-efficient implementation model.
Immediate Value
Preserves current architecture while providing speed and efficiency improvements right away.

Option B: Full Modernization
When you’re ready, move to a unified Lakehouse (Kappa) architecture. Migrate metadata, jobs, and streaming workloads into a single-engine powered by incremental-compute for long-term ROI.
Unified Metadata Management
Easily import metadata via Hive Metastore or Unified Catalog connectors.
Flexible Data Integration
Quickly ingest data using external schema/table support.
Comprehensive Task Conversion
Supports Spark‑3 syntax and enhancements; includes tools like ZettaPark to convert DataFrame logic to SQL using SQLGlot, and migrate Spark Streaming into incremental real-time processing.

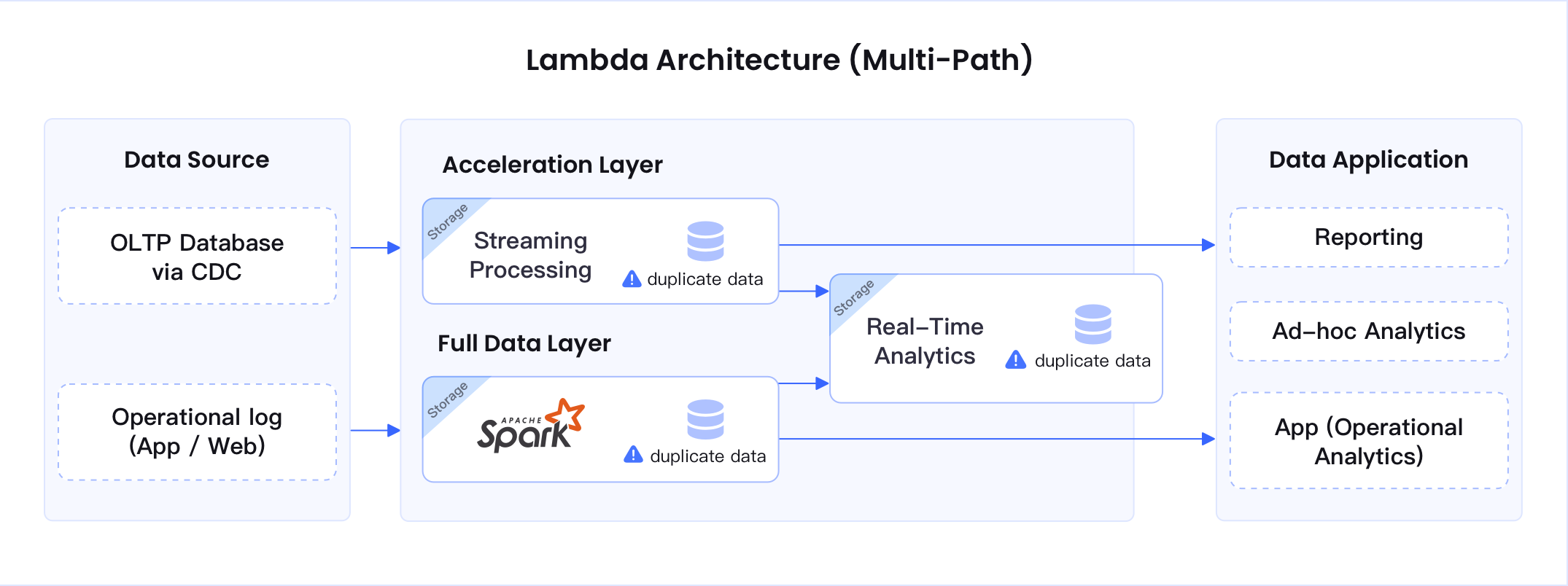

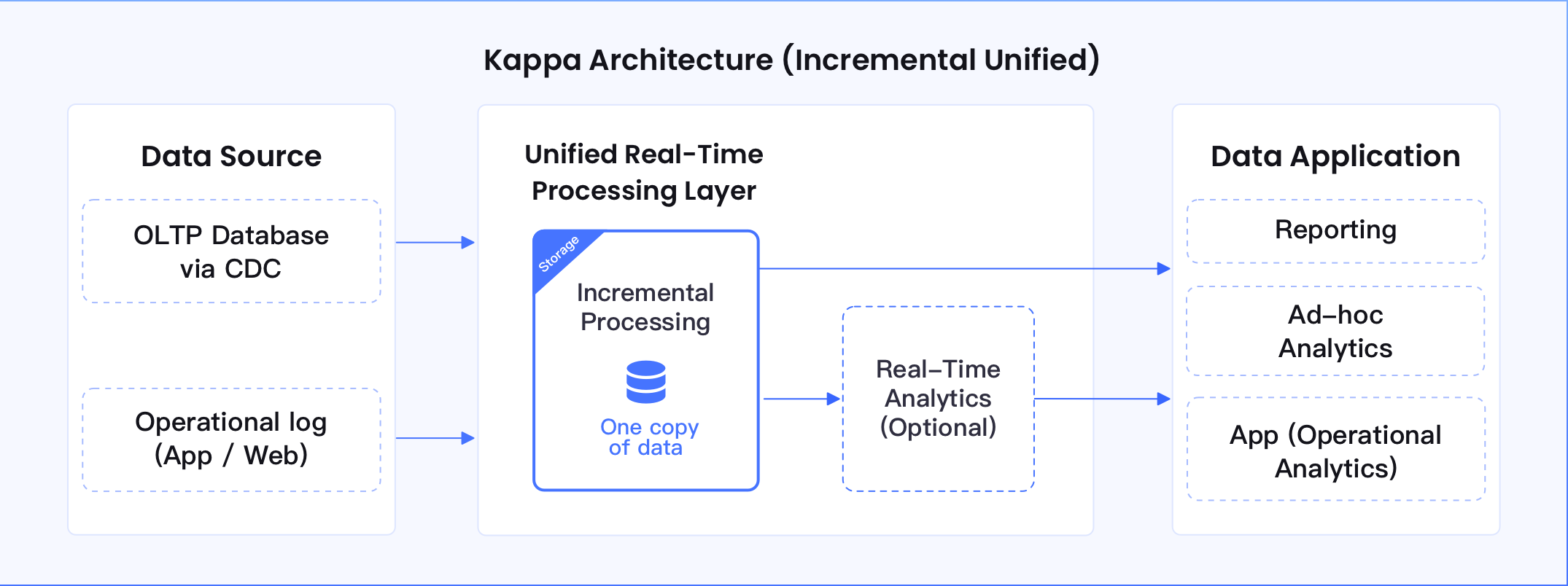
Use Cases
Enterprise-Grade Upgrade
Replace complex self-built Spark environments with a fully managed platform.
Lightweight In‑Site Acceleration
Boost existing data stack performance without major rebuilds.
Multi‑Scenario Support
Batch, ad‑hoc, real-time analytics, streaming, and search—all on one engine.
Spark API Compatibility
Minimize migration effort and accelerate ROI.
Business Impact
Cut TCO by over 50%, boost query speed, improve data freshness, and reduce operational burden.
Customer Stories


Chang’an Automobile
‘’ Built a unified, intelligent connected data platform—leading the industry transformation.‘’

Ready to Transform Your Data Platform ?
Let Singdata’s data experts guide you to an intelligent, efficient, and cost‑effective modernization of your Big Data architecture. Share your scenario with us, and we’ll connect you with pre‑sales engineers for a personalized migration plan.