How to Integrate Machine Learning Workloads into the Medallion Architecture

When you integrate machine learning into the Medallion Architecture, you unlock several advantages for your data workflows. This approach improves data quality and reliability, so you always work with clean and trustworthy information. You avoid data silos and duplicate copies, which keeps your systems streamlined. The architecture supports strong data governance and security through features like ACID transactions. You gain faster access to insights, which helps you make better decisions quickly. You can also support both business intelligence and advanced analytics in a single environment.
Key Takeaways
Integrating machine learning into the Medallion Architecture enhances data quality and reliability, leading to better decision-making.
The Bronze, Silver, and Gold layers each play a crucial role in organizing and preparing data for machine learning tasks.
Automating data workflows with orchestration tools like Apache Airflow improves efficiency and reduces errors in the data pipeline.
Regular monitoring and retraining of machine learning models ensure they remain accurate and effective over time.
Implementing strong security measures and data governance protects sensitive information and maintains compliance.
Medallion Architecture Layers for ML

Bronze, Silver, Gold Overview
You can think of the Medallion Architecture as a three-layer cake. Each layer has a special job that helps you organize and prepare your data for machine learning. The Bronze layer stores raw data just as it arrives. The Silver layer cleans and structures this data. The Gold layer gives you business-ready data that is easy to use for analytics and reporting.
Here is a table that shows the main characteristics of each layer:
Layer | Characteristics |
|---|---|
Bronze | - Schema-on-read: Data stored in original form without predefined schema. |
Silver | - Schema enforcement: Data follows a structured schema. |
Gold | - Aggregated and summarised data: Pre-calculated metrics and reports. |
Data Quality and Layer Purposes
When you Integrate Machine Learning into the Medallion Architecture, you rely on each layer to improve data quality step by step. The Bronze layer collects raw, unprocessed data. This layer focuses on data completeness and structural integrity. The Silver layer transforms and enriches the data. Here, you check for errors, remove duplicates, and make sure the data is accurate. The Gold layer prepares the data for business use. You summarize, aggregate, and validate the data for compliance and accuracy.
The following table shows how each layer supports data quality and readiness for machine learning:
Layer | Description | Key Functions |
|---|---|---|
Bronze | Raw, unprocessed data | Data Ingestion, Data Storage, Data Cleansing |
Silver | Cleansed and structured | Data Transformation, Data Enrichment, Data Validation |
Gold | Business-ready data | Data Aggregation, Data Summarization, Data Accessibility |
You can see how data quality checks change at each layer. The Bronze and Silver layers have more tests to catch problems early. The Gold layer focuses on final checks before the data reaches business users.
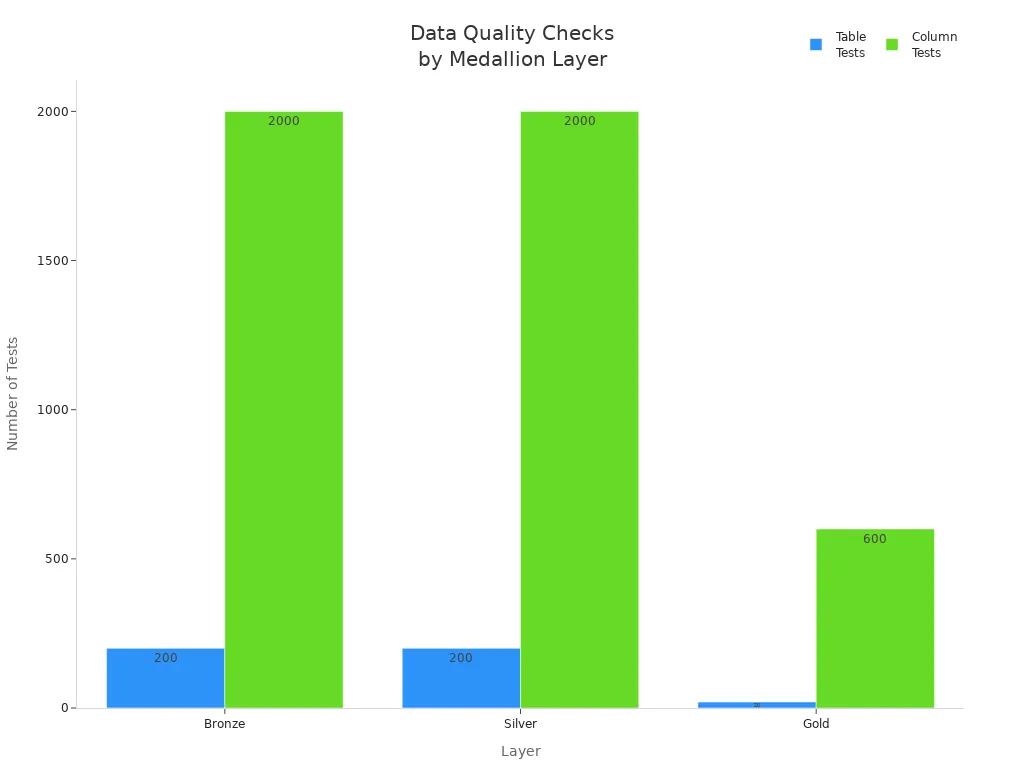
Tip: By following this layered approach, you make sure your data is always improving in quality. This helps your machine learning models perform better and gives you more reliable results.
Integrate Machine Learning with Medallion Layers

When you integrate machine learning into the Medallion Architecture, you create a clear path for your data. Each layer has a special role in preparing your data for machine learning tasks. You can map the main steps of the machine learning process—data ingestion, feature engineering, model training, and inference—to the Bronze, Silver, and Gold layers.
ML Data Ingestion in Bronze
The Bronze layer is where you collect raw data. You bring in information from many sources, such as databases, APIs, IoT devices, and transactional systems. This layer keeps the data in its original form, so you always have a complete record. You store the data in an immutable way, using interval partitioned tables. This helps you keep the full history of each dataset.
Tip: Always encrypt data in transit using TLS. You should apply access controls and authentication to limit who can send data to your Bronze layer. Mask or tokenize sensitive information at the edge to protect privacy. Audit logging helps you track where your data comes from and who accesses it.
Here are some best practices for handling data in the Bronze layer:
Store data in its original, unvalidated state.
Use efficient storage formats to keep data history.
Restrict access so only trusted sources can publish data.
Track data provenance with audit logs.
You may face challenges in this layer, such as disorganization, data overload, and inefficiency. If you do not organize your data, you can end up with inconsistent and redundant records. Too much raw data can slow down your reporting cycles. Processing large amounts of raw data may require more computational resources.
Feature Engineering in Silver
The Silver layer helps you clean and transform your data. You remove duplicates, handle missing values, and standardize formats. You break complex transformations into smaller steps, which makes your work easier to manage. You also keep track of where your data comes from and how it changes, so you can always see the full story.
Note: You should optimize data storage and access by using partitioning and indexing. This makes your queries faster and more efficient.
Here are some effective feature engineering techniques in the Silver layer:
Understand what your data consumers need for analysis.
Clean and standardize your data to remove errors.
Use modular transformations for better control.
Maintain data lineage and auditability.
Optimize storage and access for quick queries.
Validate data quality and monitor key metrics.
Enrich your data with business context and reference data.
Plan for scalability and keep good documentation.
The Silver layer processes include deduplication, cleansing, conforming, and typecasting. You refine your dataset by handling missing data, detecting outliers, and standardizing values. These steps make your data more structured and ready for machine learning.
Model Training and Inference in Gold
The Gold layer gives you curated, high-quality data. You use this data for model training and inference. The Gold layer contains refined and aggregated information tailored for your business needs. This makes your analytics and machine learning more reliable.
When you use the Gold layer, you work with polished datasets. These datasets improve the quality of your business intelligence and decision-making. The Gold layer ensures high data quality and integrity, so you can trust your results.
Tip: The Gold layer stores aggregate data, which helps you prepare and train machine learning models faster. You spend less time cleaning and profiling data.
Gold data is highly refined and optimized. You get rapid access to essential information, which makes your machine learning models more reliable. The Gold layer simplifies your workflow and reduces the time needed for data preparation.
ML Process | Bronze Layer | Silver Layer | Gold Layer |
|---|---|---|---|
Data Ingestion | Raw, unprocessed data | - | - |
Feature Engineering | - | Cleansing, transformation, enrichment | - |
Model Training | - | - | Curated, high-quality data |
Inference | - | - | Business-ready, reliable results |
When you integrate machine learning with the Medallion Architecture, you use each layer to improve your data step by step. You start with raw data in Bronze, clean and transform it in Silver, and use curated data in Gold for advanced machine learning applications.
MLOps and Automation in the Medallion Architecture
Pipeline Orchestration
You need strong orchestration to move data smoothly through the Medallion Architecture. Orchestration tools help you schedule, monitor, and manage each step in your machine learning pipeline. Common tools include:
Azure Data Factory
These tools let you automate tasks like data ingestion, transformation, and model deployment. Automation improves efficiency by moving data across Bronze, Silver, and Gold layers without manual steps. For example, Delta Live Tables can automate data processing, which reduces errors and increases reliability.
Tip: Automate data cleansing in the Silver layer to keep your data quality high. Use efficient file formats like Parquet or Delta to optimize storage and speed.
You can follow best practices to orchestrate your end-to-end workflows:
Use Synapse Data Engineering for tasks like deduplication and type casting.
Apply Data Flow tasks for data quality checks.
Enforce compliance rules, such as GDPR, early in your pipeline.
Track data lineage to understand how your data changes.
Design pipelines for parallel processing to reduce wait times.
A well-orchestrated pipeline helps you Integrate Machine Learning into your data lakehouse. You can move from raw data to model deployment with fewer errors and faster results.
Model Monitoring and Retraining
After you deploy a model, you must monitor its performance. You want to catch problems like model drift or data quality issues early. MLOps gives you tools to track and manage your models. Key components include:
Data exploration with notebooks in the Bronze, Silver, and Gold layers
Continuous Integration (CI) for code versioning and traceability
Feature engineering and a feature store for consistent features
Model training and evaluation with experiment tracking
Model registration and versioning in a central registry
Model and feature serving through REST APIs
You should use tools like MLflow Tracking to store and version your experiments. This helps you trace every change and understand how your models evolve. Schedule regular retraining jobs to keep your models accurate as new data arrives. Use monitoring dashboards to track metrics and set alerts for unusual patterns.
Note: Automation in monitoring and retraining reduces manual work and helps you respond quickly to changes in your data or business needs.
Practical Use Cases
Predictive Maintenance
You can use the Medallion Architecture to build a predictive maintenance solution. Start by collecting sensor data from machines in the Bronze layer. This raw data includes temperature, vibration, and usage hours. In the Silver layer, clean and standardize the data. Remove errors and fill in missing values. Add context, such as machine type or maintenance history. In the Gold layer, create features like average temperature over time or sudden spikes in vibration. Use these features to train a machine learning model that predicts when a machine might fail. This helps you schedule repairs before breakdowns happen, saving time and money.
Churn Prediction
A strong data pipeline helps you predict customer churn. You begin by extracting raw customer activity data into the Bronze layer. This includes age, recent activity, and login frequency. In the Silver layer, you clean and standardize the data. You make sure the data is consistent and ready for analysis. The Gold layer creates optimized datasets for your churn prediction model. You use these datasets to identify patterns and predict which customers might leave.
Layer | Purpose |
|---|---|
Bronze | Maintains raw data for reprocessing and quality checks. |
Silver | Standardizes data without business logic, ensuring generic operations. |
Gold | Creates optimized datasets for specific analytical purposes. |
Tip: Use the Gold layer to quickly update your churn models as new data arrives.
Fraud Detection
You can Integrate Machine Learning into fraud detection by following a clear process:
Define your business goals and what you want to measure.
Collect and prepare transaction and account data in the Bronze layer.
Engineer features and select the most important ones in the Silver layer.
Train and select your fraud detection model in the Gold layer.
Deploy the model and use it to score transactions in real time.
Monitor the model and update it as needed.
The Bronze layer captures all transaction data and external fraud reports. The Silver layer normalizes and enriches this data with customer history. The Gold layer runs real-time anomaly detection models. This setup lets you update risk scores every minute, improving accuracy and response times. Financial institutions use this approach to get faster insights and stop fraud quickly.
Challenges and Best Practices
Ensuring Data Consistency
You need to keep your data consistent as it moves through the Bronze, Silver, and Gold layers. Problems can appear at any stage and affect your machine learning results. For example, if you have data quality issues or ingestion failures in the Bronze layer, your entire pipeline can break. Late data arrival can cause your Gold layer to show old or incorrect insights. When you transform data in the Silver layer, you might create new problems, like mismatched keys, that can change your final reports.
Here is a table that shows common challenges you might face:
Challenge Type | Description |
|---|---|
Data Quality Issues | Problems with data accuracy or completeness can hurt analytics and customer satisfaction. |
Loading failures in Bronze can stop the pipeline and lead to wrong reports. | |
Late Data Arrival | Delays in Bronze make Gold data stale and less useful for quick decisions. |
Detailed Data Quality Issues | Silver layer changes can create new errors that affect Gold layer analytics. |
Tip: Set up regular data quality checks and monitor each layer to catch problems early.
Managing Model Drift
Your machine learning models can lose accuracy over time. This happens when the data changes, a problem called model drift. You can manage drift by using several smart strategies. A schema registry helps you track and manage changes to your data structure. If you make changes, use backward-compatible updates so your pipeline keeps working. Automated data profiling and monitoring let you spot changes in your data before they hurt your models.
Here are some best practices for managing model drift:
Set up automated data profiling and monitoring.
Use statistical tests to find changes in data patterns.
Keep baseline profiles to compare new data.
Get alerts when data shifts away from what you expect.
Strategy | Description |
|---|---|
Schema Registry | Central place to manage and track schema changes. |
Backward-Compatible Schema Changes | Make updates that do not break existing processes. |
Automated Data Profiling | Monitor data to catch drift and keep quality high. |
Note: Regular monitoring helps you keep your models accurate and reliable.
Security and Governance
You must protect your data and models at every layer. Good security and governance keep your data safe and help you follow rules. Unity Catalog is a tool that helps you manage who can see and use your data. Data contracts set clear rules for sharing data between teams. Strong access management makes sure only the right people can reach sensitive information.
Measure | Description |
|---|---|
Unity Catalog | Manages data access and helps with compliance. |
Data Contracts | Sets rules for safe and efficient data sharing. |
Data Security and Access Management | Controls who can access data and keeps your platform secure. |
Tip: Review your security settings often and update access controls as your team grows.
You can Integrate Machine Learning into the Medallion Architecture by following a clear, layered approach. Start with raw data in Bronze, transform and enrich it in Silver, and use curated Gold data for model training and inference. Focus on data quality, automation, and MLOps to ensure reliable results.
Step | Action |
|---|---|
Choose high-value decisions and set metrics | |
Bronze → Silver Build-Out | Ingest data and create structured areas |
Gold & Semantic Layer | Design schemas and certify measures |
Hardening & Scale Readiness | Enable incremental processing and runbooks |
This structure helps you scale, adapt, and support advanced analytics across industries.
FAQ
What is the main benefit of using the Medallion Architecture for machine learning?
You get cleaner, more reliable data at every step. This layered approach helps you build better machine learning models. You can trust your results because each layer improves data quality.
How do you keep your machine learning models up to date?
You set up automated monitoring and retraining. This lets you spot changes in your data. You can retrain your models when needed to keep them accurate.
Can you use real-time data with the Medallion Architecture?
Yes, you can process real-time data. You collect streaming data in the Bronze layer. You clean and enrich it in Silver. You use the Gold layer for fast analytics and machine learning.
What tools help you automate ML pipelines in this architecture?
You can use tools like Apache Airflow, Azure Data Factory, and MLflow. These tools help you schedule, monitor, and manage your data and machine learning workflows.
See Also
Navigating the Complexities of Dual Pipelines in Lambda Design
Structured Framework for AI-Driven International Supply Chains
Exploring the Essential Elements of Big Data Architecture
