Data Import Overview
There are various methods to load data into Lakehouse, depending on the data source, data format, loading method, and whether it is batch, streaming, or data transfer. Lakehouse provides multiple import methods, categorized by import method including: supporting user SDK import, supporting SQL command import, supporting client upload data, supporting third-party open-source tools, and supporting Lakehouse Studio visual interface import.
Import Methods Overview
Categorized by Scenario
| Data Source | Specific Case | Applicable Scenario |
|---|---|---|
| Quick Upload of Local Files | Use the put command to upload to the internal Volume, then use the COPY command to import. | Suitable for source file upload and requires SQL for conversion. It is recommended to use SQL for conversion or handling abnormal data during the upload process. |
| Use the visual upload interface of Lakehouse Studio | 1. Suitable for users who need to upload small data files, especially when the files are stored locally. 2. User-friendly interface simplifies the upload process. 3. Supports multiple file formats, including CSV, PARQUET, AVRO, to meet different data format needs. | |
| Use Jdbc client In versions after JDBC 2.0.0, the local COPY command has been deprecated. We recommend using the PUT method to upload data to the volume, and then use the server-side COPY command to import. | 1. Small data volume without a visual interface, suitable for technical users, especially those familiar with command line operations and need to batch process small data volumes. 2. Quickly process CSV files, suitable for scripting and automation operations. | |
| Batch Import Data from Object Storage | Use Volume to batch load data from object storage | 1. Suitable for data stored in object storage, needing to leverage SQL performance advantages to quickly read large amounts of data. 2. Efficiently handle large-scale datasets. 3. Supports direct SQL data conversion, simplifying the data import process. 4. Supports multiple file formats, including CSV, PARQUET, ORC |
| Import using Copy command | 1. Has the advantages of Volume, with the difference being that the Copy command provides more fault tolerance parameters and data export support. It also supports exporting to object storage data. | |
| Use JavaSDK to read Kafka and write to Lakehouse in real-time | Import data using Java SDK | 1. Suitable for business scenarios requiring real-time data stream processing, especially for developers familiar with Java. 2. Real-time data reading and writing ensure the immediate availability of data. 3. Suitable for custom data import, providing high flexibility. |
| Use custom SDK to read files and write to Lakehouse | Import data using Java SDK | 1. Suitable for one-time bulk data import with low data frequency (time interval greater than five minutes). 2. Supports custom data sources, providing flexibility in data import. |
| Import data using Python SDK | 1. Suitable for developers familiar with Python who need custom data import, especially when the data is not in object storage or the integration does not support the data source. | |
| Users needing fully managed services and visual operations, especially for synchronizing third-party data sources | Use Lakehouse Studio data integration | 1. Supports a wide range of data sources and various import methods. 2. Provides real-time synchronization, CDC mirroring synchronization, and offline periodic scheduling synchronization. 3. Visual monitoring improves data management transparency. |
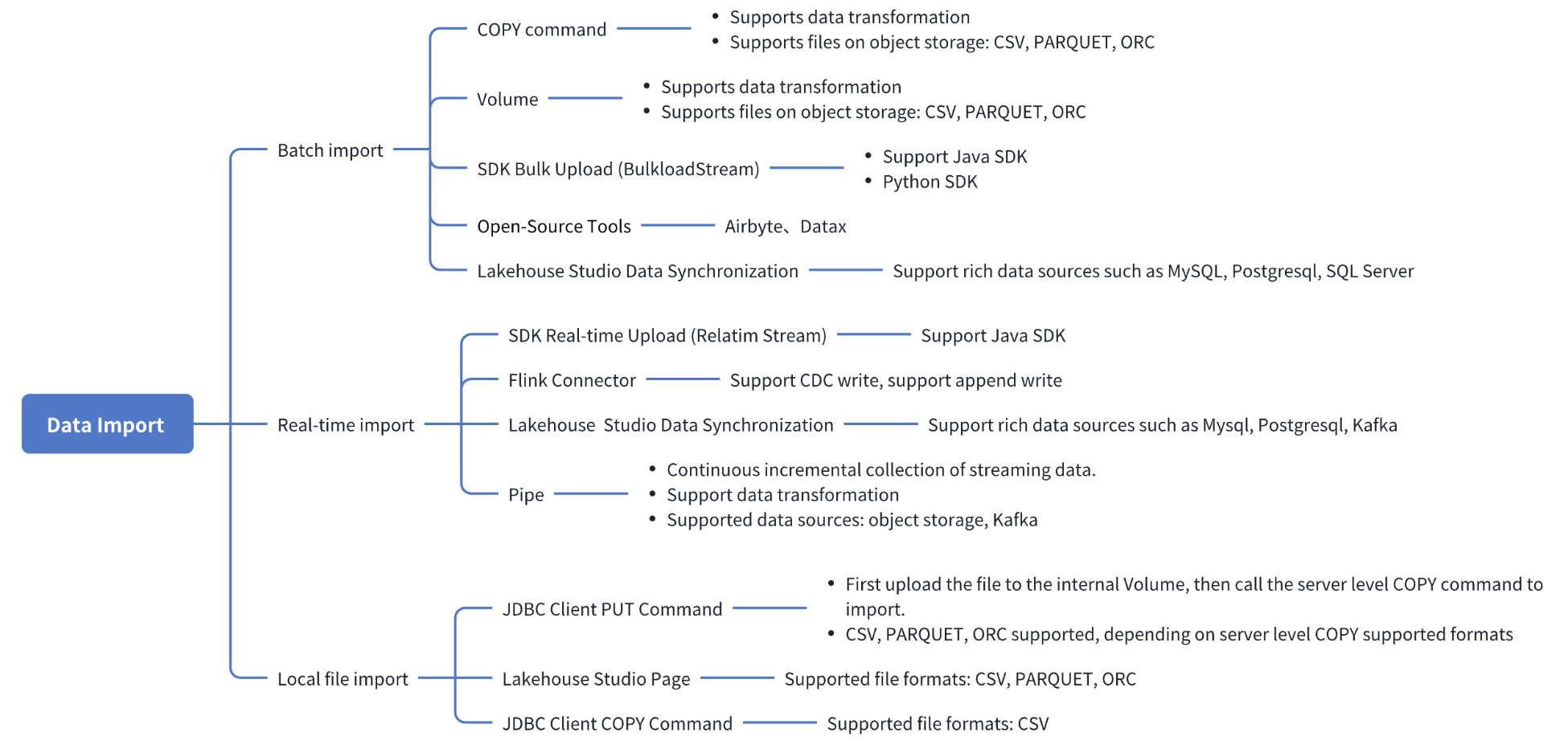
By Import Method
| Import Method Name | Usage | Usage Notes |
|---|---|---|
| COPY Command | COPY INTO Command | 1. Currently supported object storage locations are Tencent Cloud COS and Alibaba Cloud OSS. 2. Cross-cloud vendor import is not supported (will be supported later). For example, your Lakehouse is hosted on Alibaba Cloud but the object storage is on Tencent Cloud. |
| Volume | Use ISNERT INTO... SELECT FORM VOLUME to import | 1. Currently supported object storage locations are Tencent Cloud COS and Alibaba Cloud OSS. 2. Cross-cloud vendor import is not supported (will be supported later). For example, your Lakehouse is hosted on Alibaba Cloud but the object storage is on Tencent Cloud. |
| Data Integration | Use Data Integration to import | 1. Supports a wide range of data sources, performance is slightly worse than COPY command and Volume. |
| SDK Realtime Data Stream (RealtimeStream) | Upload data in real-time | 1. Data written in real-time can be queried in seconds. 2. When changing the table structure, you need to stop the real-time writing task first, then restart the task after a period of time (about 90 minutes) after the table structure change. 3. Table stream, materialized view, and dynamic table can only display committed data. Data written by real-time tasks needs to wait 1 minute to be confirmed, so table stream also needs to wait 1 minute to see it. |
| SDK Batch Upload (BulkloadStream) | Batch upload data Java SDK、Batch upload data Python SDK | |
| Use Open Source Tools to Import Data | AIRBYTE、DATAX FLINK CONNECTOR |
Import Instructions
Lakehouse fundamentally provides two main methods for data ingestion to accommodate different data processing needs and performance considerations.
Direct Pull by SQL Engine
The SQL engine of Lakehouse can directly pull data from object storage, which is particularly suitable for scenarios where the data source is already located in object storage. In the future, Lakehouse plans to expand support for more types of data sources to further enhance data ingestion flexibility.
- Advantages: The SQL engine directly pulls data, leveraging its performance advantages to efficiently process data stored in object storage. Using the COPY command and Volume support for data transformation during import.
- Compute Resources: Executing SQL queries consumes compute resources (VirtualCluster), but this consumption is worthwhile as it provides powerful data processing capabilities.
- File Formats: Currently supported file formats include CSV, PARQUET, and ORC, which are commonly used formats in data analysis and processing.
- Import Methods: Supports various data import methods, such as the COPY command, Volume, offline data integration import, and SDK bulk upload (BulkloadStream).
Push Data to Ingestion Service
The Ingestion Service of Lakehouse provides a solution for scenarios requiring real-time data ingestion. Clients push data to the server, which is received and committed to the table by the Ingestion Service, including SDK real-time data streams (RealtimeStream) and CDC real-time writes.
- Advantages: The advantage of this method is that it improves the timeliness of data ingestion, achieving real-time writes and real-time readability.
- Resource Consumption: Currently, the Ingestion Service is in preview and using this service is temporarily free of charge. However, please note that charges will be applied in the future.
- Applicable Scenarios: Suitable for business scenarios requiring real-time data stream processing, such as real-time analysis and instant data updates.
Batch Loading Recommendations
Batch ingestion involves loading large bounded datasets that do not require real-time processing. They are typically ingested at specific rule-based frequencies, and not all data arrives immediately. For batch loading, it is recommended to use object storage to store incoming data. Lakehouse supports multiple file formats, including CSV, PARQUET, and ORC file formats.