Implementing Slowly Changing Dimensions (SCD) on Lakehouse with Streams, Pipelines, and SQL Tasks
About SCD
Slowly Changing Dimensions (SCD) is a key concept in data warehouse design, used to manage changes in dimension table data over time. Dimension tables contain descriptive data, such as customer information, product information, etc., which may change over time. SCD provides a method to handle and record these changes so that both historical and current data in the data warehouse remain consistent and accurate.
SCD is typically divided into several types:
SCD Type 1
SCD Type 1 handles changes by overwriting old data. This means that when dimension data changes, the old data is overwritten by the new data, so no historical record is kept. This method is simple and fast but loses historical data.
Example: Suppose a customer's address changes, SCD Type 1 will directly update the customer address field, and the old address information will be overwritten by the new address.
SCD Type 2
SCD Type 2 handles changes by creating new rows to retain historical records. This method adds a new record to the dimension table and updates it with the new data while retaining the old data row, possibly using effective date columns or version columns to track different versions of the data.
Example: When a customer's address changes, SCD Type 2 will insert a new record in the dimension table containing the new address and may add an effective date range to indicate the validity period of that address.
SCD Type 3
SCD Type 3 handles changes by adding extra columns to the table to retain limited historical records. This method adds a new column to the dimension table to store the old data, and when a change occurs, the old data is moved to the new column, and the new data overwrites the original position.
Example: If a customer's address changes, SCD Type 3 will add an "old address" column to the table, store the old address in that column, and store the new address in the original column.
Requirements
- Singdata Lakehouse account
- Github repository for this guide
- AK information to access Alibaba Cloud OSS
Introduction to Implementing SCD on Lakehouse
Modern methods for implementing Slowly Changing Dimensions (SCD) in Lakehouse leverage automated data pipelines and native Lakehouse features to achieve efficient change tracking and historical data management.
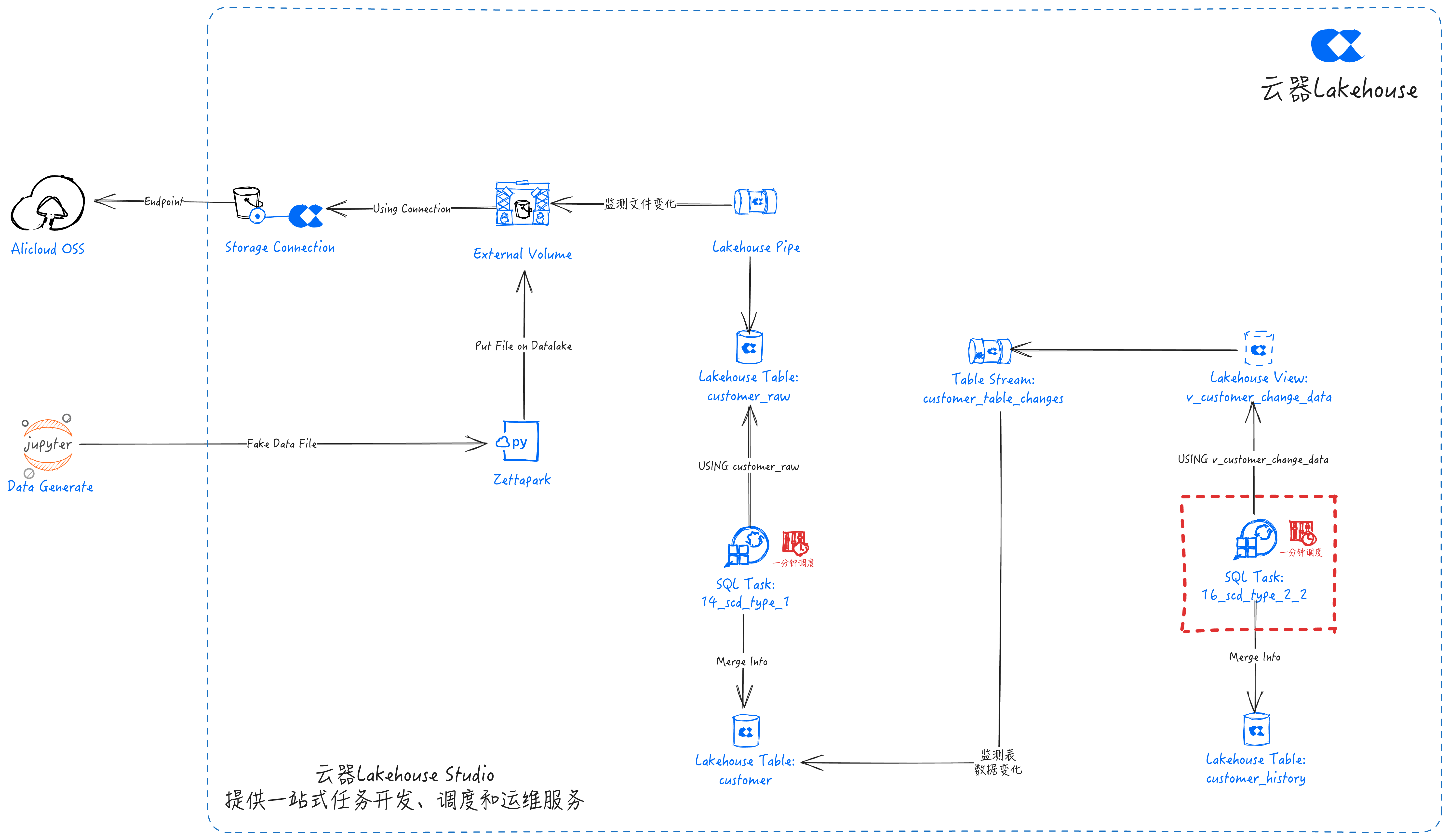
Pipeline Overview
An end-to-end data pipeline that automatically captures and processes data changes:
-
Data Source (Jupyter calls Fake to generate test data) → Use Python to create data to simulate real-world events.
-
Zettapark PUT→ Use Zettapark to pull and load data into the data lake Volume.
-
Data Lake Volume → Data lake storage based on Alibaba Cloud OSS.
-
Lakehouse Pipe captures data lake file changes → Lakehouse Pipe efficiently streams data from the data lake Volume to the Lakehouse.
-
Lakehouse Table Stream captures Table data changes → Captures changes in the base table for incremental consumption.
-
SQL Tasks for SCD processing → Develop SQL tasks to implement SCD processing logic and schedule tasks through Singdata Lakehouse Studio.
-
Lakehouse Data Management, Lakehouse manages data through three tables:
customer_raw: Stores raw ingested data.customer: Reflects the latest updates from the stream pipeline.customer_history: Retains all updated records for analysis and audit of change history.
Key Components
Data Generation
- Tools Used: Python
- Python scripts dynamically generate simulated customer data to mimic real-time data sources.
Data Ingestion Layer
-
Data Lake Volume: Storage area for source files, Lakehouse's data lake storage, using Alibaba Cloud OSS in this case. Unified management of Volume and Table by creating an external Volume.
-
Zettapark: PUT the generated simulated data to the data lake Volume.
-
Pipe: Lakehouse's built-in real-time data extraction service, using Pipe for real-time streaming.
- Automatically detects new files in the data lake Volume.
- Loads data into the temporary table
customer_rawwithout manual intervention.
Change Detection Layer
-
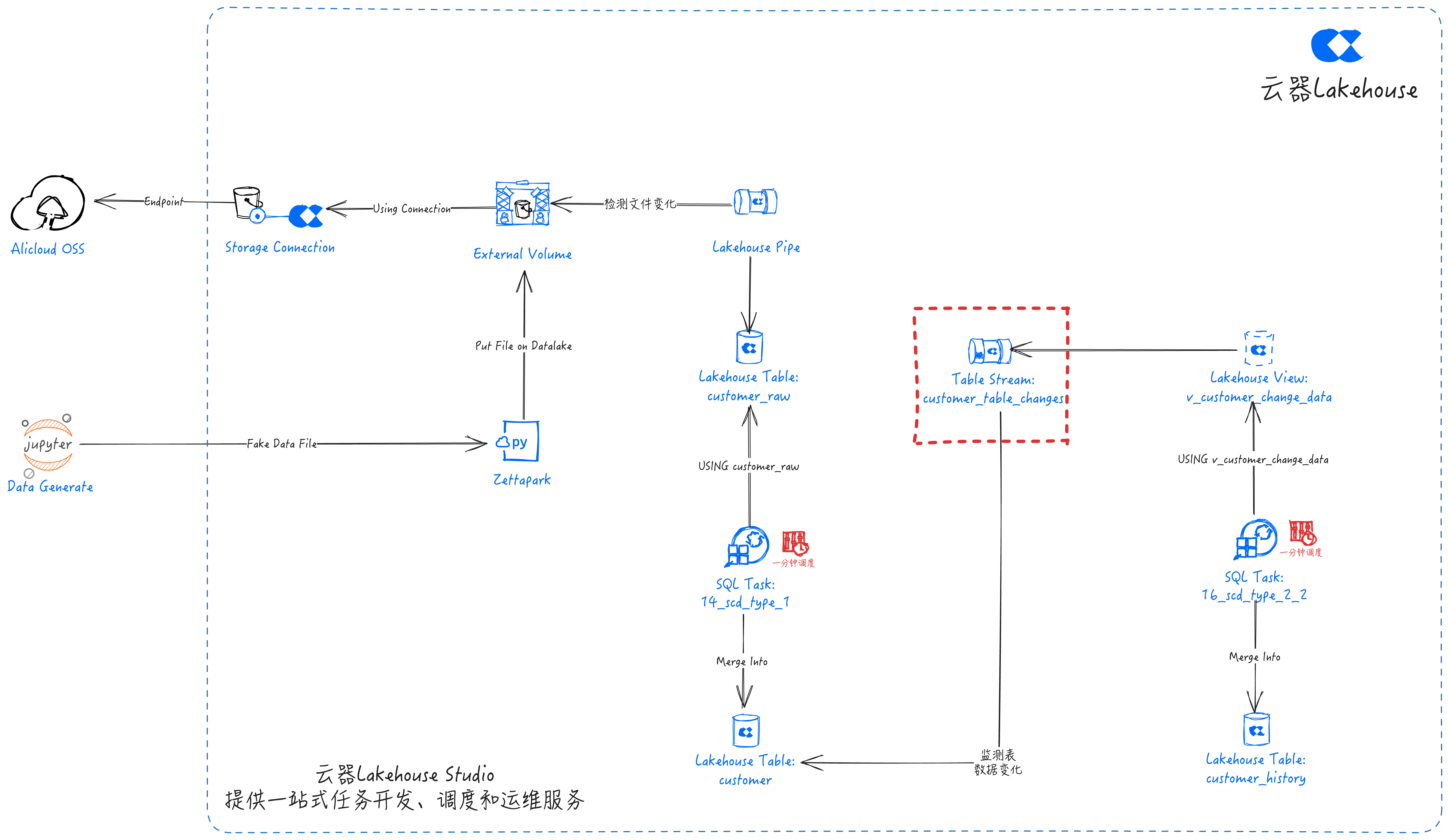
Lakehouse Stream (Table Stream):
- Capture operations such as INSERT, UPDATE, DELETE
- Maintain change tracking metadata
- Efficiently handle incremental changes
- Store detected change data from customer into customer_table_changes
Processing Layer
-
Lakehouse SQL Tasks:
- Scheduled jobs for SCD processing
- Handle Type 1 (overwrite) and Type 2 (historical) changes
- Maintain referential integrity
- Tasks
- Insert new or updated records into the
customertable (SCD Type 1). - Record updates into the
customer_historytable (SCD Type 2) to preserve audit trails.
- Insert new or updated records into the
Storage Layer
-
Temporary Tables: Temporary storage area for raw data
-
Dimension Tables: Final tables with historical tracking
- Include effective dates
- Maintain current and historical records
- Support point-in-time analysis
Application Scenarios
- Customer dimension management
- Product catalog version control
- Employee data tracking
- Any dimension requiring historical change tracking
Technology Stack
Required components:
- Singdata Lakehouse
- Alibaba Cloud OSS (data lake storage)
- Jupyter Notebook (for test data generation and PUT files to data lake Volume), or other Python environments
Implementation Steps
Task Development
Navigate to Lakehouse Studio Development -> Tasks,
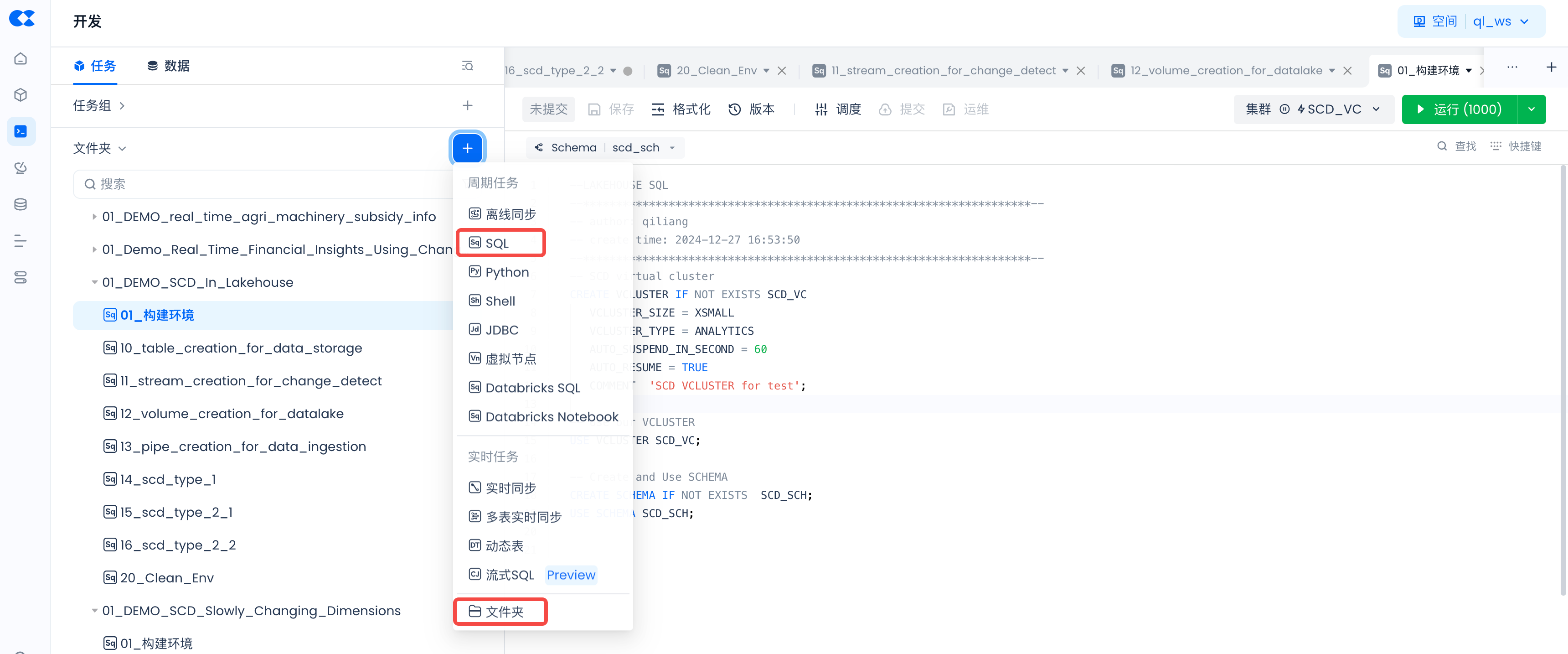
Click “+” to create the following directory:
- 01_DEMO_SCD_In_Lakehouse
Click “+” to create the following SQL tasks:
- 01_setup_env
- 10_table_creation_for_data_storage
- 11_stream_creation_for_change_detect
- 12_volume_creation_for_datalake
- 13_pipe_creation_for_data_ingestion
- 14_scd_type_1
- 15_scd_type_2_1
- 16_scd_type_2_2
- 20_clean_env
Copy the following code into the corresponding tasks, or download the files from GitHub and copy the contents into the corresponding tasks.
Lakehouse Environment Setup
SQL Task: 01_setup_env
Create Table
SQL Task: 10_table_creation_for_data_storage
Create Stream
SQL Task: 11_stream_creation_for_change_detect
Create Data Lake Volume
SQL Task: 12_volume_creation_for_datalake
Creating a Volume requires a Connection to Alibaba Cloud OSS. Please refer to Create Connection.
Create Pipe
SQL Task: 13_pipe_creation_for_data_ingestion
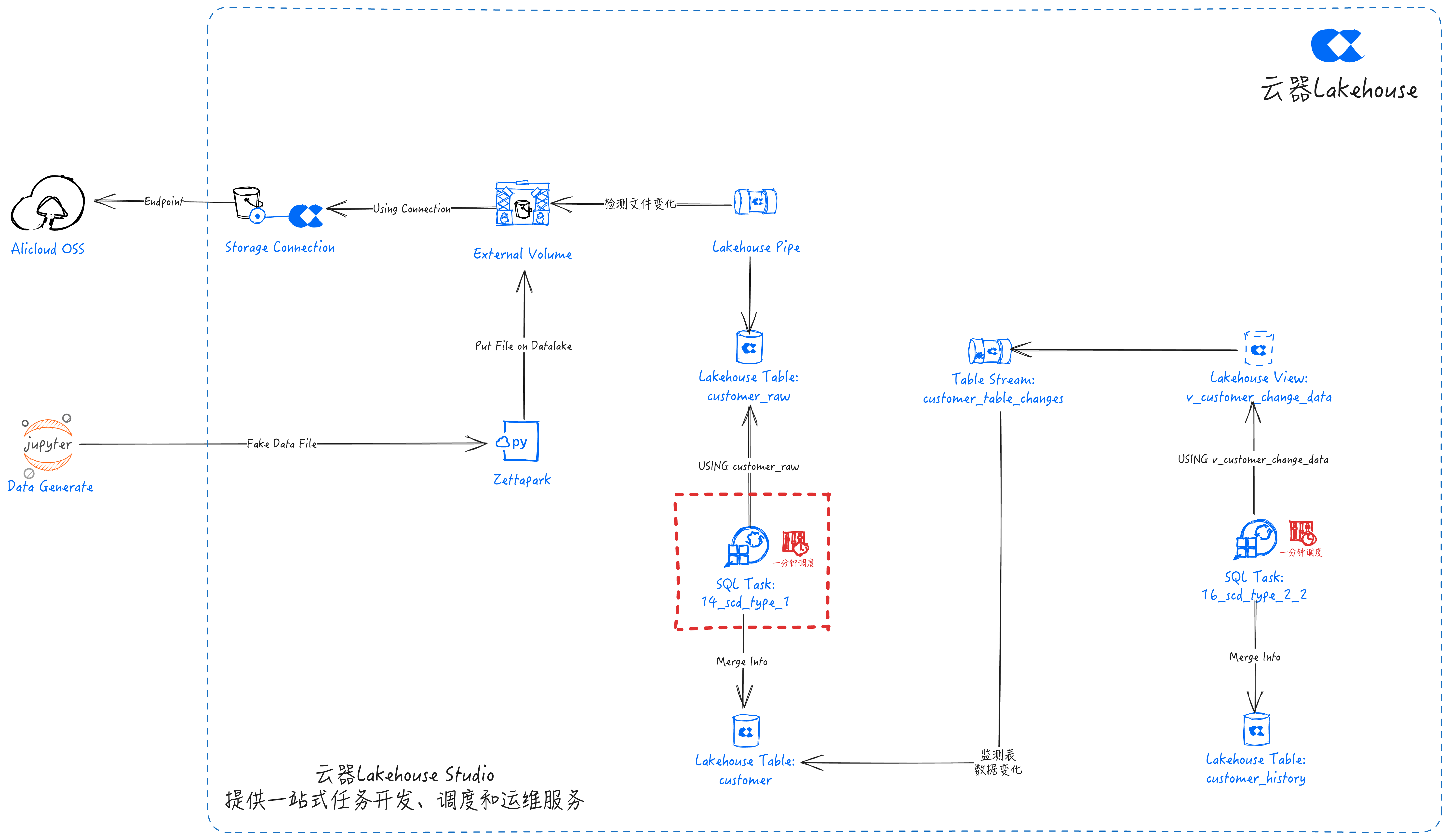
SCD Type 1
SQL task: 14_scd_type_1
SCD Type 2-1
SQL Task: 15_scd_type_2_1
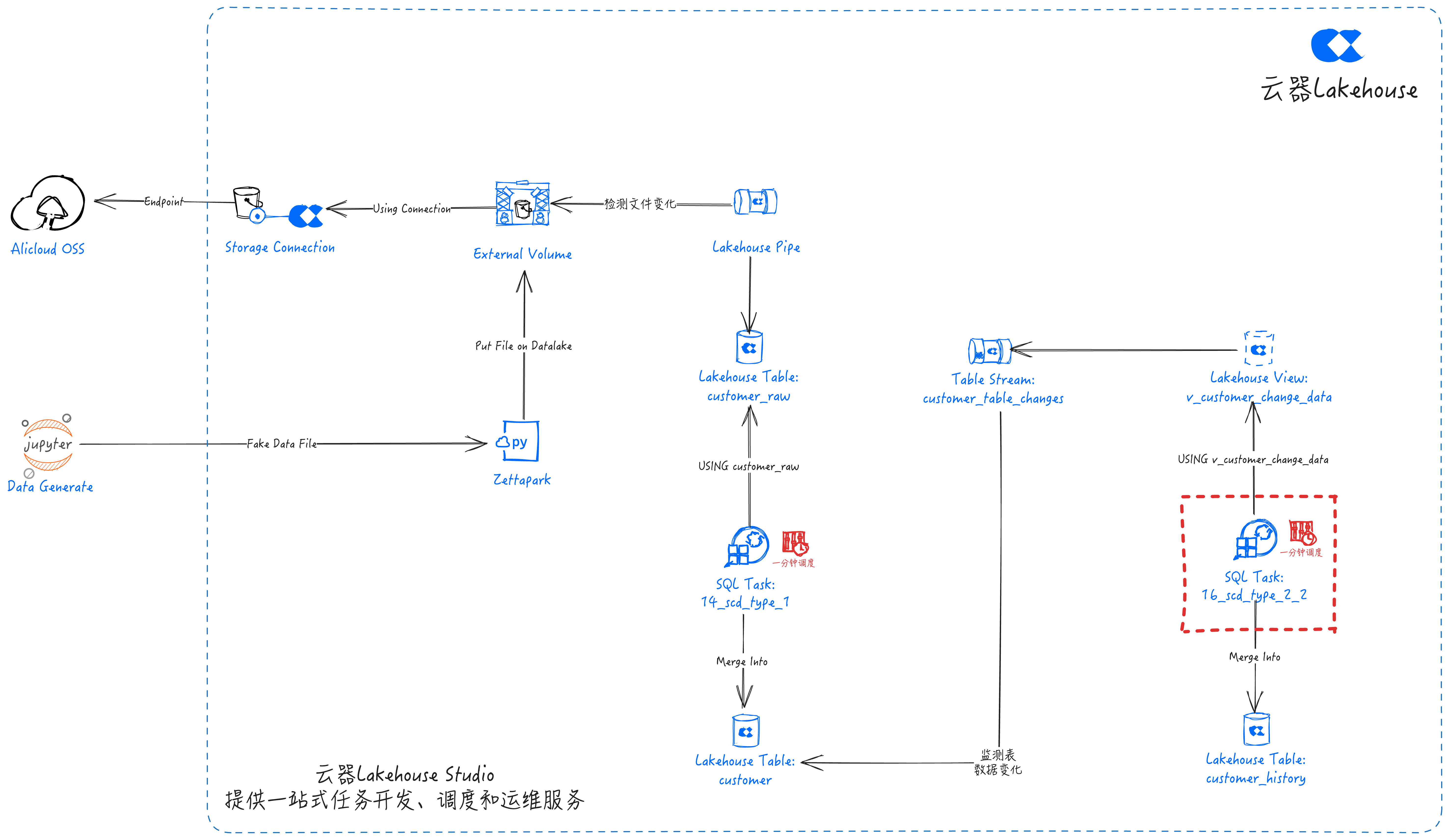
SCD Type 2-2
SQL Task: 16_scd_type_2_2
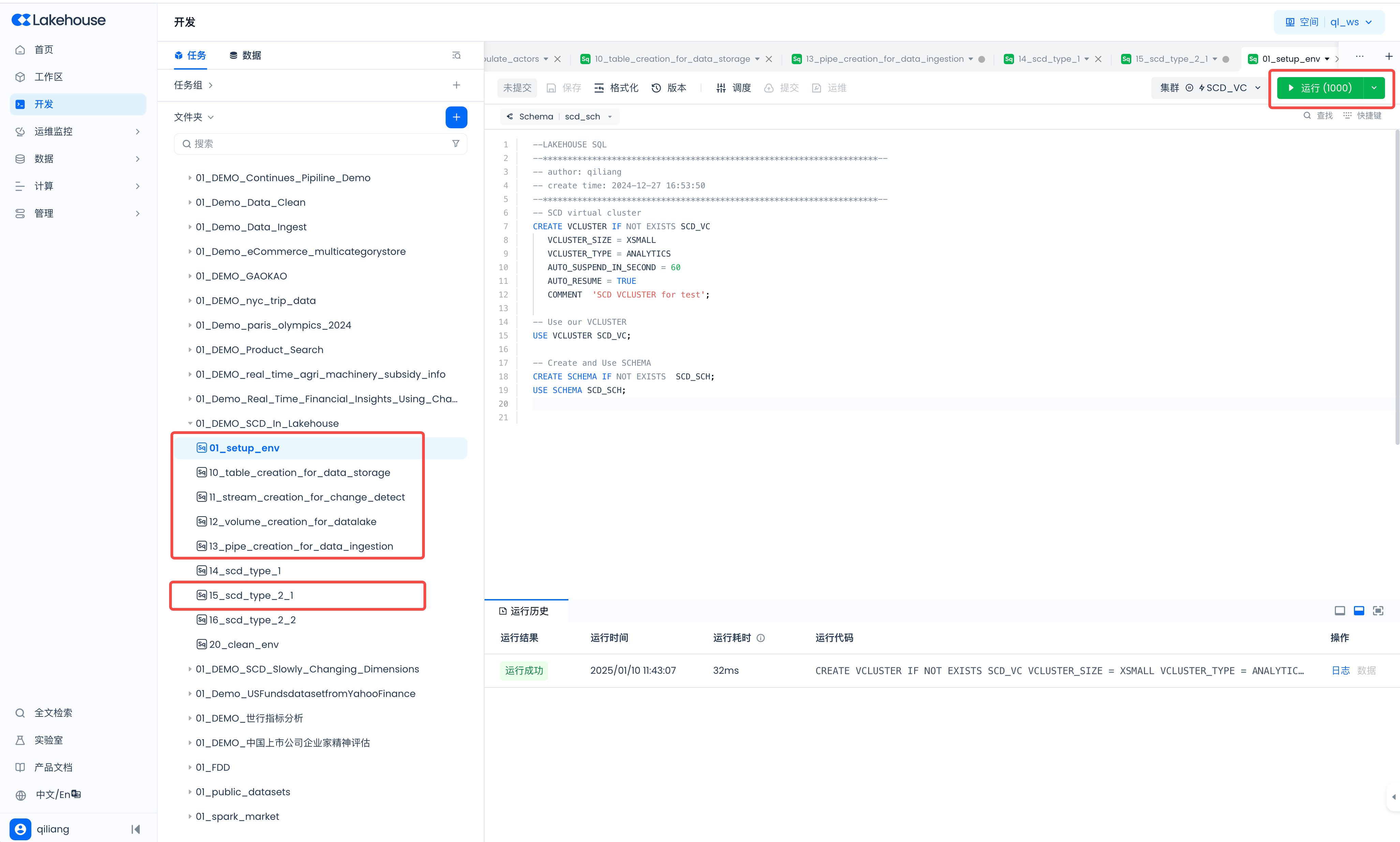
Build Environment
Run the developed tasks to build the Lakehouse runtime environment. Navigate to Development -> Tasks page, open the following tasks and run them one by one:
- 01_setup_env
- 10_table_creation_for_data_storage
- 11_stream_creation_for_change_detect
- 12_volume_creation_for_datalake
- 13_pipe_creation_for_data_ingestion
- 15_scd_type_2_1
Task Scheduling and Submission
Schedule the developed SCD tasks to run every minute. Navigate to Development -> Tasks page, open the following tasks and configure the scheduling one by one:
- 14_scd_type_1
- 16_scd_type_2_2
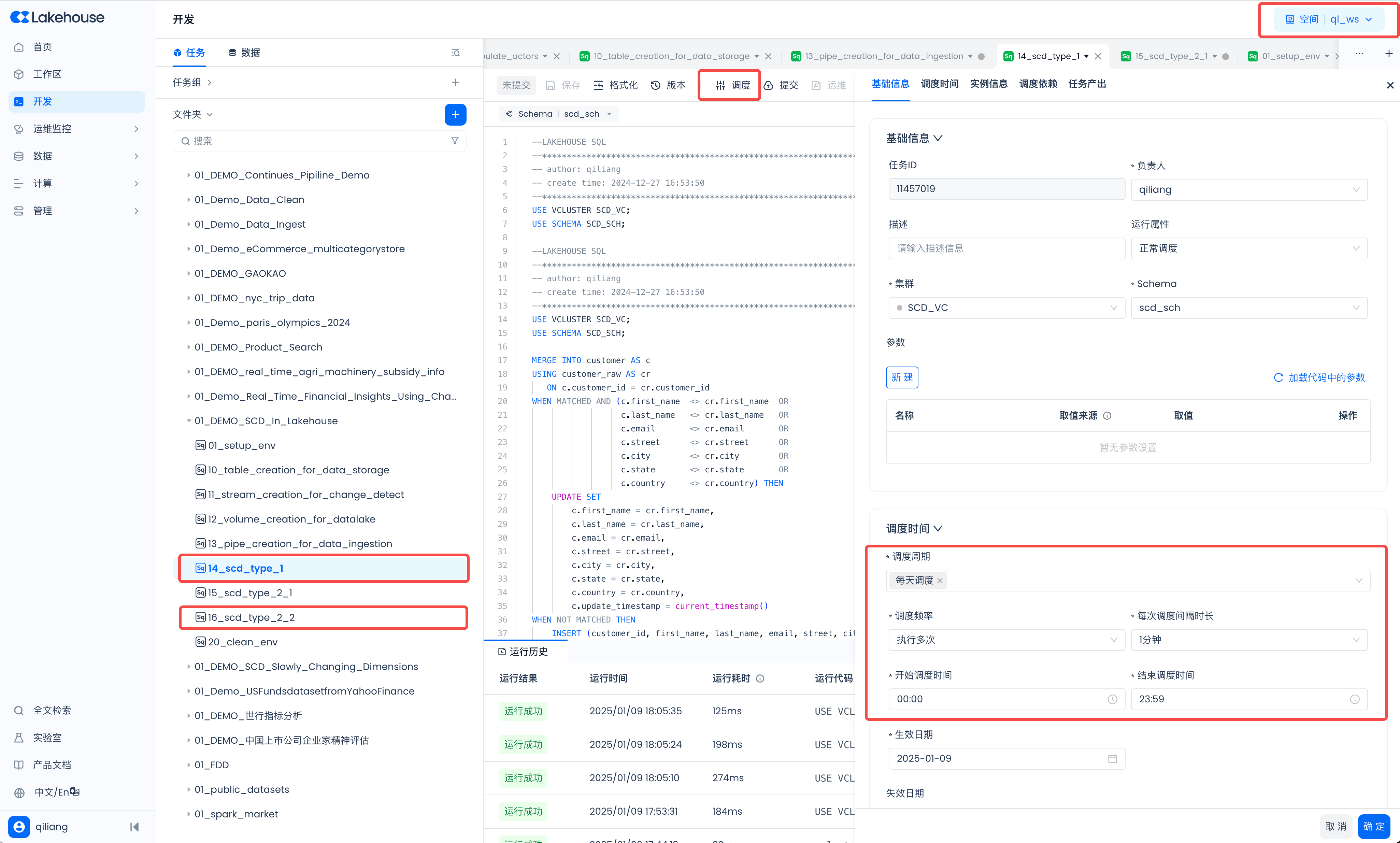
Submit Tasks
After configuring the scheduling, click "Submit". The tasks will be scheduled to run every minute, updating the data in the target table.

Generate Test Data
Generate test data and PUT to the data lake Volume
- Executing the above code will PUT a new file into the Volume. Pipe will automatically detect the new file and write the data into the customer_raw table.
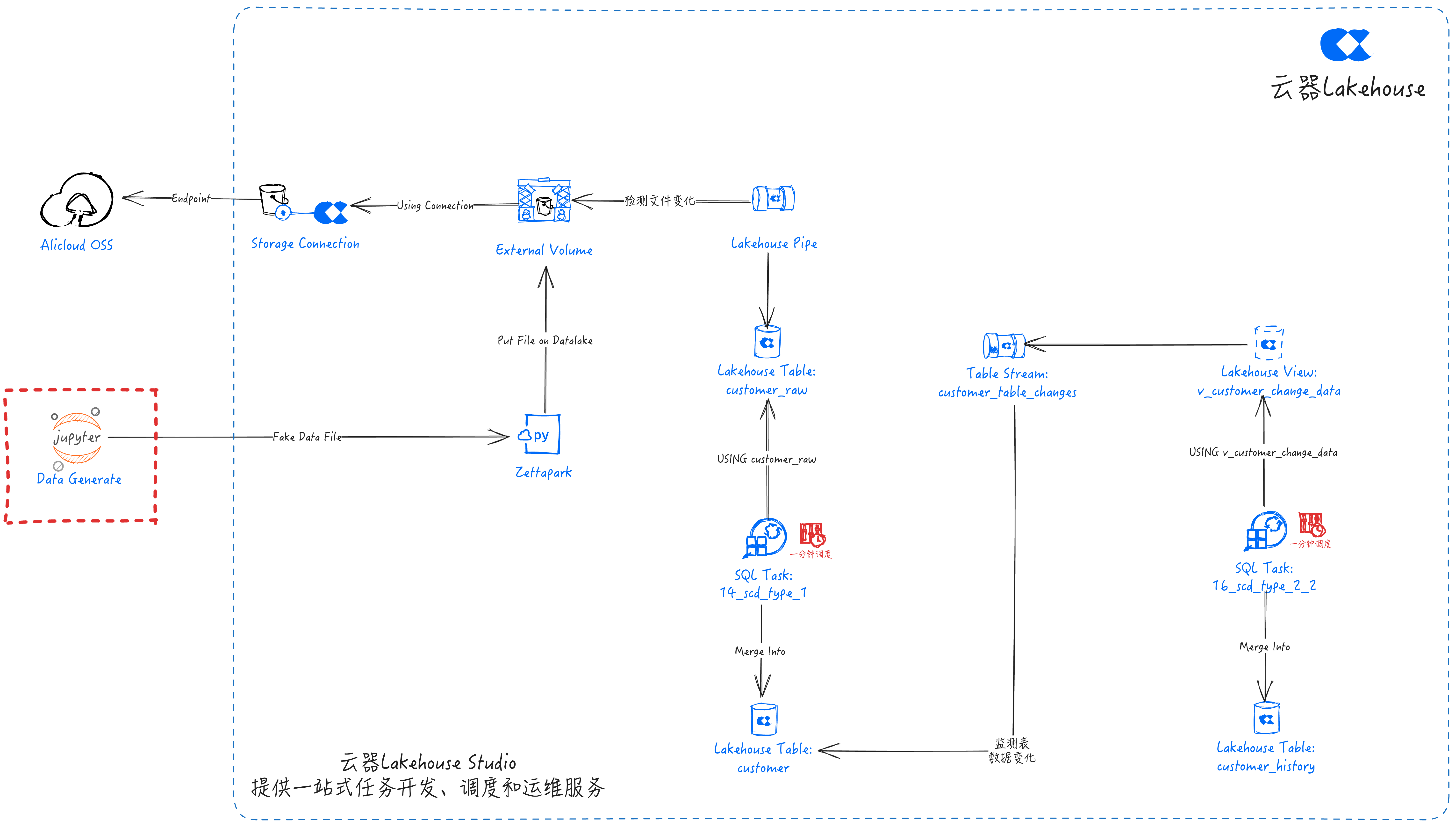
- The 14_scd_type_1 task is configured with periodic scheduling. It will perform scd_type_1 calculations every minute and merge the results into the customer table.
- Table Stream will automatically detect changes in the customer table data and save the changed data in customer_table_changes.
- The 14_scd_type_2_2 task is configured with periodic scheduling. It will perform scd_type_2 calculations every minute and merge the results into the customer_history table.
Monitoring and Maintenance
Pipe Monitoring
- Use the SHOW PIPES command to view the list of PIPE objects
- Use the DESC PIPE command to view detailed information about the specified PIPE object
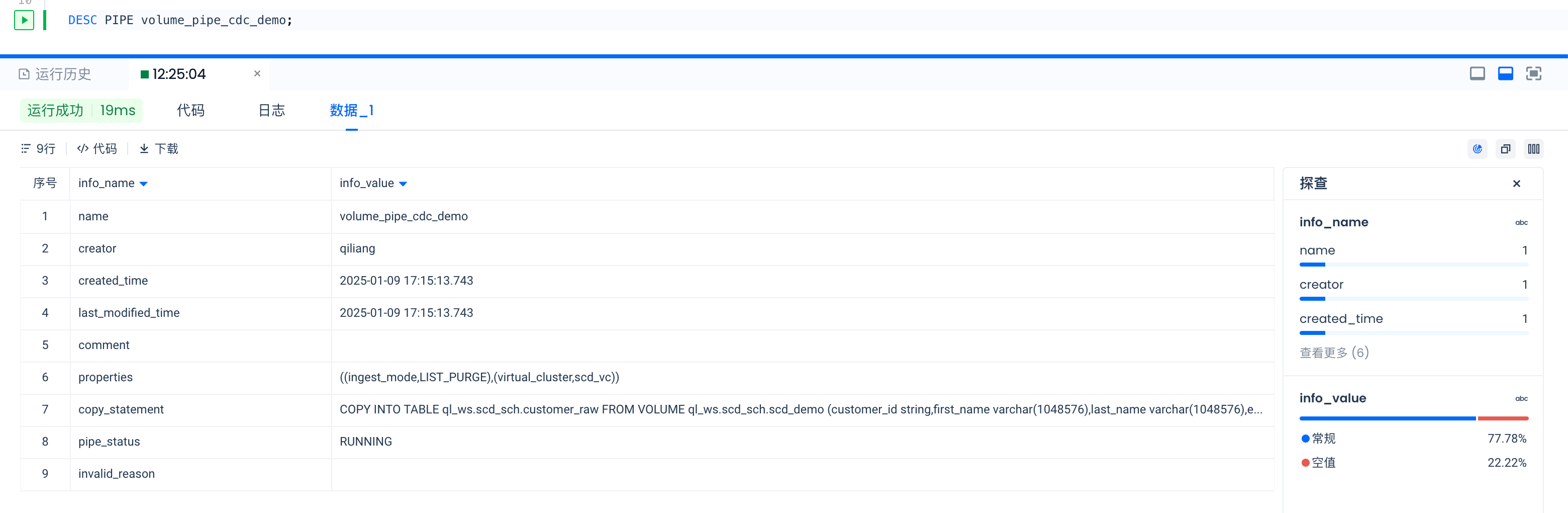
- View pipe copy job execution status
Filter through the job history using the query_tag. All pipe executed copy jobs will be tagged in the query_tag with the format: pipe.worksapce_name.schema_name.pipe_name
In this guide, worksapce_name is ql_ws, schema_name is SCD_SCH, and pipe name is volume_pipe_cdc_demo. Therefore, the query_tag is:
pipe.ql_ws.scd_sch.volume_pipe_cdc_demo
Navigate to Compute -> Job History:
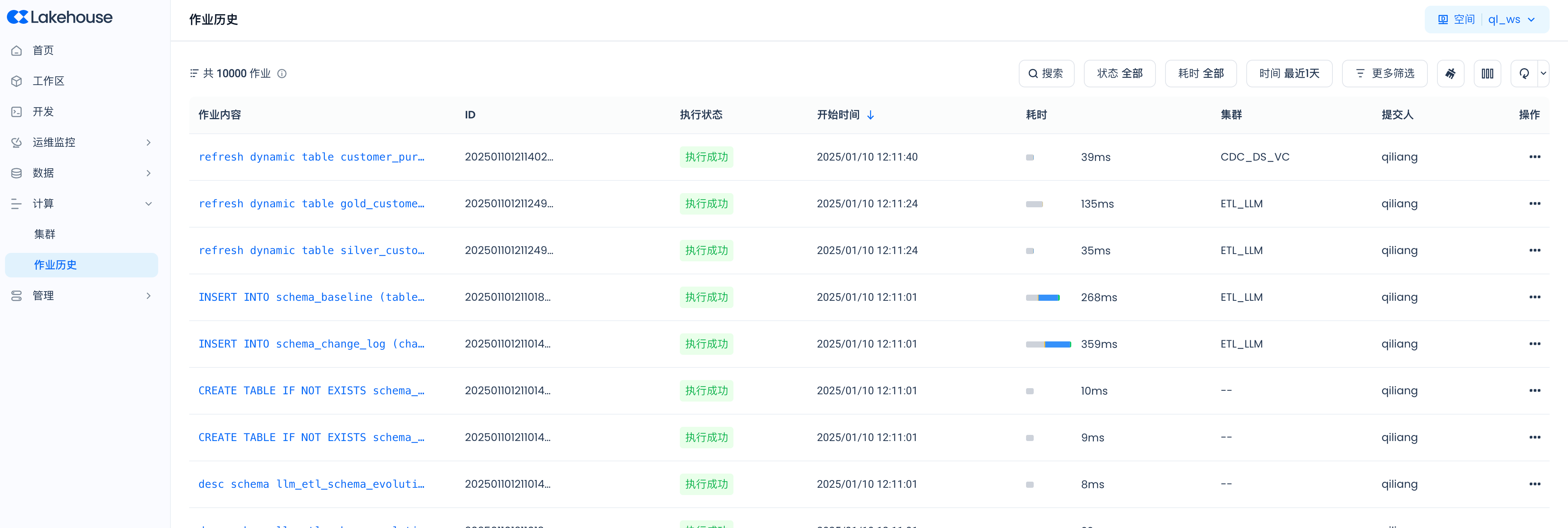
Click "More Filters" and enter "pipe.ql_ws.scd_sch.volume_pipe_cdc_demo" in the QueryTag to filter:
{kind=link}
Periodic Scheduling Tasks
Navigate to Operations Monitoring -> Task Operations -> Periodic Tasks:
{kind=link}
View task instances:
