Using Pipe for Continuous Data Import
Overview
Pipe is an object type in Singdata Lakehouse used for streaming data ingestion. Using Pipe allows for continuous incremental collection of streaming data (such as from Kafka), simplifying the streaming data import process.
When defining a Pipe, the COPY command is used to express the semantics of reading from an external data source and writing to a target table. The main difference from a standalone COPY command is that Pipe will automatically and continuously schedule COPY tasks, maintain and manage the read position of the data source, and continuously import data incrementally from the data source.
The overall logic of using Pipe for automatic streaming data import is illustrated as follows:
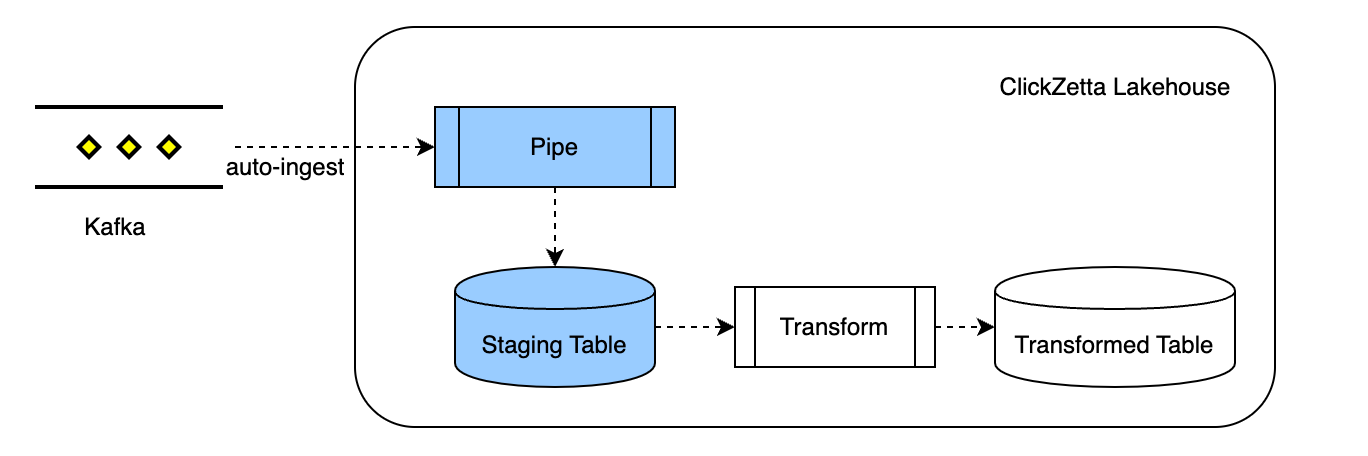
Data Source Support
Pipe provides the capability to continuously collect new data changes from data sources, currently including:
- Kafka data source
- Object storage Alibaba Cloud OSS
Managing and Using Pipe
Lakehouse provides a set of commands to manage Pipe:
- CREATE PIPE
- DESC PIPE
- SHOW PIPES
- DROP PIPE
Creating a Pipe Object
Creating a Pipe Object to Read from Kafka Data Source
A Pipe object can be created using SQL commands, with the syntax as follows:
Parameter Description:
-
VIRTUAL_CLUSTER: The VC used for submitting copy jobs via pipe. Required.
-
BATCH_INTERVAL_IN_SECONDS: Job generation interval. Optional parameter, default is 60 seconds.
-
BATCH_SIZE_PER_KAFKA_PARTITION: Maximum number of messages per partition for the job. Optional parameter, default is 500,000.
-
COMMENT: Add comments. Optional parameter.
-
COPY_STATEMENT: Use COPY INTO <table> to import data into the target table.
- For Kafka data sources, the
read_kafkatable-valued function will be used in the SELECT statement to read Kafka message data. For parameter descriptions of the function, please refer to theread_kafkafunction documentation.
- For Kafka data sources, the
Create Pipe to Read Object Storage Data Source
Reading object storage requires creating a VOLUME and enabling Alibaba Cloud Message Service. The message service is used to send object storage events to the Pipe to trigger its execution.
Parameter Description:
- VIRTUAL_CLUSTER: VC used for submitting copy jobs with pipe. Required.
- ALICLOUD_MNS_QUEUE: Message queue name. The Message Service MNS can actively push events generated on specified resources of object storage to the specified receiver as messages. Pipe receives the message queue event to trigger the execution of fetching which files are new files, and then triggers the COPY command to import them into the table.
View Pipe List and Object Details
Currently, you can use SQL commands to view the Pipe list and object details.
- Use the
SHOW PIPEScommand to view the Pipe object list
Notes
-
SHOW PIPES: Lists Pipe objects in the current Schema by default. -
SHOW PIPES IN SCHEMA schema_name: Lists all Pipe objects in the specified Schema. -
SHOW PIPES IN WORKSPACE workspace_name: Lists all Pipe objects in the specified Workspace. -
Use the
DESC PIPEcommand to view detailed information about the specified Pipe object
Delete Pipe Object
Currently, you can use SQL commands to delete Pipe objects.
Constraints and Limitations
- When the data source is Kafka: Only one
read_kafkafunction is allowed in a pipe. - When the data source is object storage: Only one volume object is allowed in a pipe.