Building an Analysis-Oriented Modern Data Stack Based on Singdata Lakehouse
This article introduces how to build an analysis-oriented Modern Data Stack based on Singdata Lakehouse, Metabase, and MindsDB.
Solution Architecture
Features of the Modern Data Stack solution based on Singdata Lakehouse:
- Implement AWS data warehouse through the data lake, using Singdata Lakehouse to achieve optimized integration of lake and warehouse, significantly reducing data storage costs, computing costs, and maintenance costs.
- Unlimited storage and efficient migration. The entire data channel uses cloud object storage to achieve a storage-compute separation architecture, avoiding the bandwidth and storage capacity bottlenecks of intermediate server nodes in traditional solutions.
- Singdata Lakehouse + Metabase, achieving simplified BI data analysis, allowing visual data exploration and analysis with just two mouse clicks, greatly lowering the threshold for business personnel to analyze data, making it very friendly for business personnel.
- Singdata Lakehouse + MindsDB, achieving 100% SQL-based AI and LLM enhanced analysis. Without mastering other complex languages, data engineers and BI analysts can achieve AI and LLM enhanced analysis based on SQL.
- Reducing the requirements for technical personnel across the entire data stack (cloud infrastructure, data lake, data warehouse, BI, AI), lowering the human resource threshold for enterprises, and improving talent accessibility.
The entire solution focuses on simplicity and ease of use, helping enterprises shift their focus from data infrastructure to data analysis, achieving modernization of data analysis.

The above diagram shows how we will migrate and build the Modern Data Stack, summarized as follows:
- Use the Reshift unload command to unload data to Parquet files on an S3 bucket.
- Load data directly from Parquet files in the AWS S3 bucket into Singdata Lakehouse tables using Singdata Lakehouse SELECT * FROM VOLUME, achieving rapid data warehousing (in this example, loading a table with over 20 million rows takes only 30 seconds).
- BI application: Explore and analyze data through Metabase (from table to dashboard with just two mouse clicks, yes, just two mouse clicks).
- AI application: Predict house prices through MindsDB (100% SQL-based model prediction).
Solution Components
-
AWS:
- Redshift
- S3
-
Singdata
- Singdata Lakehouse, a multi-cloud and integrated data platform. It adopts a fully managed SaaS service model, providing enterprises with a simplified data architecture.
- Singdata Lakehouse Driver for Metabase.
- Singdata Lakehouse Connector for MindsDB.
-
Data Analysis
- Metabase with Lakehouse Driver on Docker. Metabase is a complete BI platform, but its design philosophy is very different from Superset. Metabase focuses heavily on the experience of business personnel (such as product managers, marketing operators) when using this tool, allowing them to freely explore data and answer their own questions.
- MindsDB with Lakehouse Connector on Docker. MindsDB can directly model in Singdata Lakehouse, eliminating the professional steps of data processing and building machine learning models. Data analysts and BI analysts can use it out of the box without being familiar with data engineering and modeling knowledge, lowering the modeling threshold, making everyone a data analyst, and everyone can apply algorithms.
- Zeppelin with Lakehouse JDBC Interpreter on Docker
- Zeppelin with MySQL JDBC Interpreter on Docker (connecting to MindsDB's MySQL interface)
Why Use Singdata Lakehouse?
- Fully Managed: Singdata Lakehouse provides a fully managed, cloud-based Lakehouse service that is easy to use and scale. This means you don't have to worry about managing and maintaining your own hardware and infrastructure, avoiding time-consuming and expensive costs, and achieving peace of mind.
- Cost Savings: Compared to Redshift, the total cost of ownership (TCO) of Singdata Lakehouse is usually lower because it charges based on usage without requiring upfront commitments. Singdata Lakehouse's highly flexible pricing model allows you to pay only for the resources you actually use, rather than being locked into a fixed cost model.
- Scalability: Singdata Lakehouse is designed to handle large amounts of data and can scale up or down as needed, making it a good choice for enterprises with significant fluctuations in computing loads. Singdata Lakehouse data is stored in cloud object storage services, achieving "unlimited scalability" in data scale.
- Performance: Singdata Lakehouse adopts a Single Engine All Data architecture, separating compute and storage, enabling it to process query tasks faster than Redshift.
- Easy to Use: Singdata Lakehouse provides an integrated platform for data integration, development, operations, and governance, making development and management easier without the need for complex scheme integration.
- Data Source Support: Singdata Lakehouse supports multiple data sources and formats, including structured and semi-structured data. In most cases, BI and AI applications can be developed using only SQL.
- Data Integration: The built-in data integration of Singdata Lakehouse supports a wide range of data sources, making data loading and preparation for analysis easier. Overall, migrating to Singdata Lakehouse can help you save time and money, and enable you to handle and analyze data more easily and effectively.
Implementation Steps
Data Extraction (E)
Unload Housing Price Sales Data from Redshift to S3
Redshift UNLOAD command: Use Amazon S3 server-side encryption (SSE-S3) to unload query results into one or more text, JSON, or Apache Parquet files on Amazon S3.
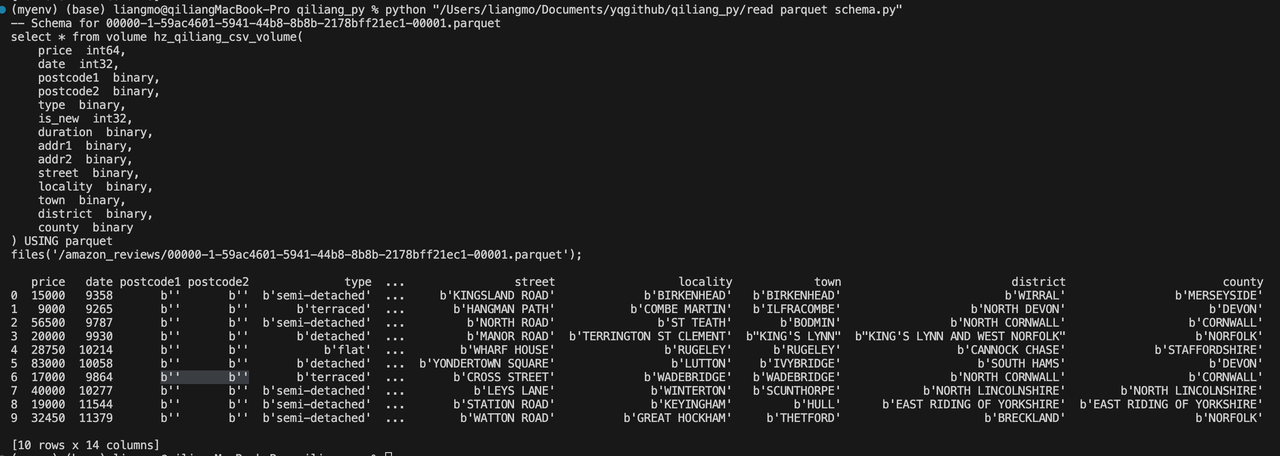
Data Lake Data Exploration: Explore Parquet Data on AWS S3 with Singdata Lakehouse
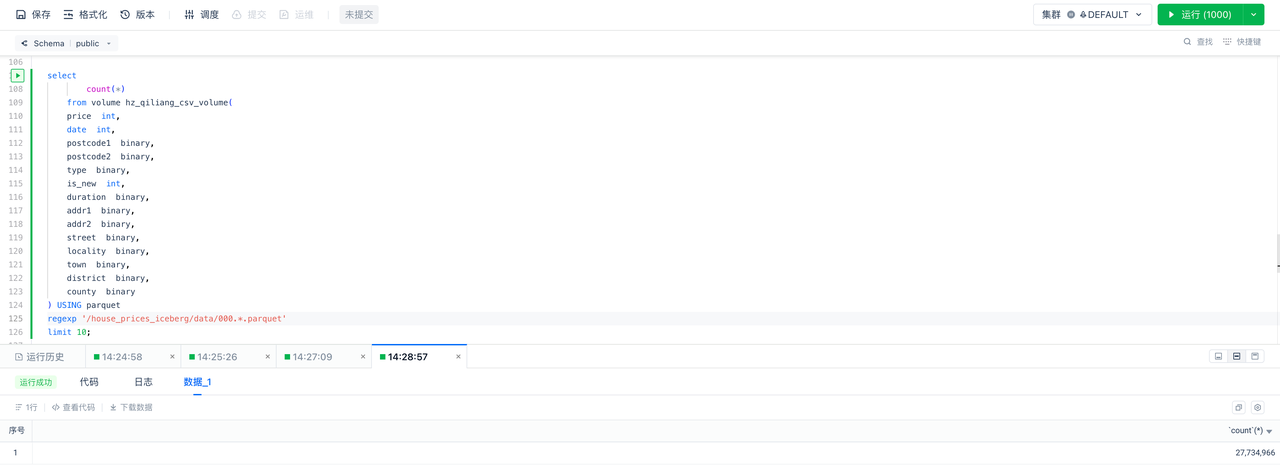
View the total number of rows of data (requires pre-creation of Singdata Lakehouse STORAGE CONNECTION and EXTERNAL VOLUME):
Preview Data
In Singdata Lakehouse, executing the above query yields the following result:
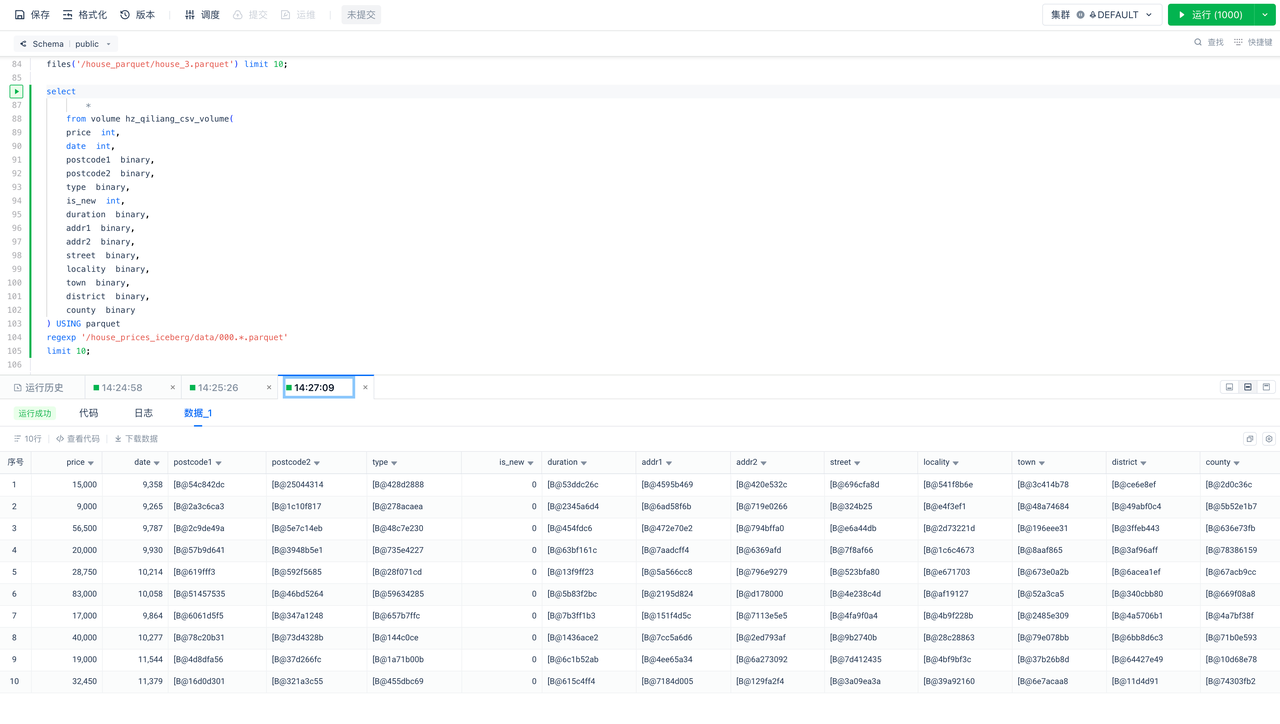
Data Ingestion: Load Data from S3 (L) to Singdata Lakehouse and Perform Data Transformation (T)
Verify the number of rows of data in the warehouse:
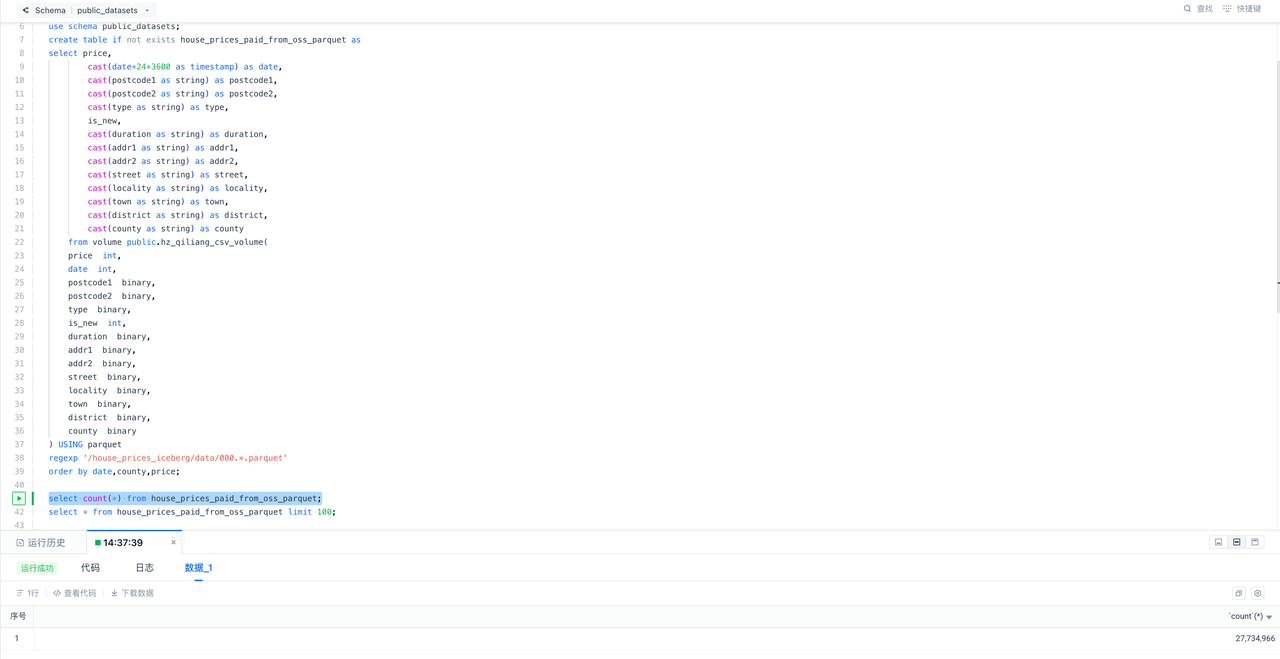
Explore the data in the warehouse using SQL:
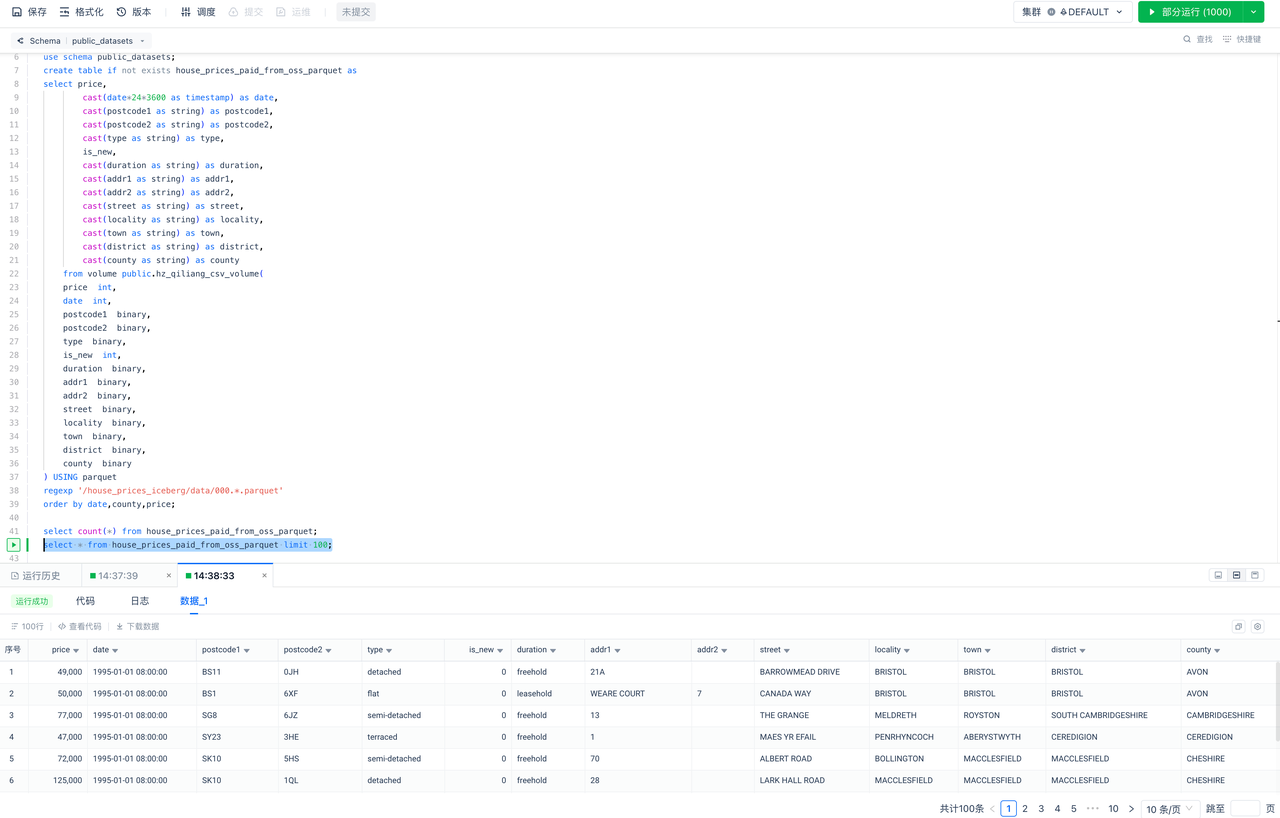
BI Application: Explore and analyze data in Singdata Lakehouse through Metabase
Create a database connection to Singdata Lakehouse in Metabase
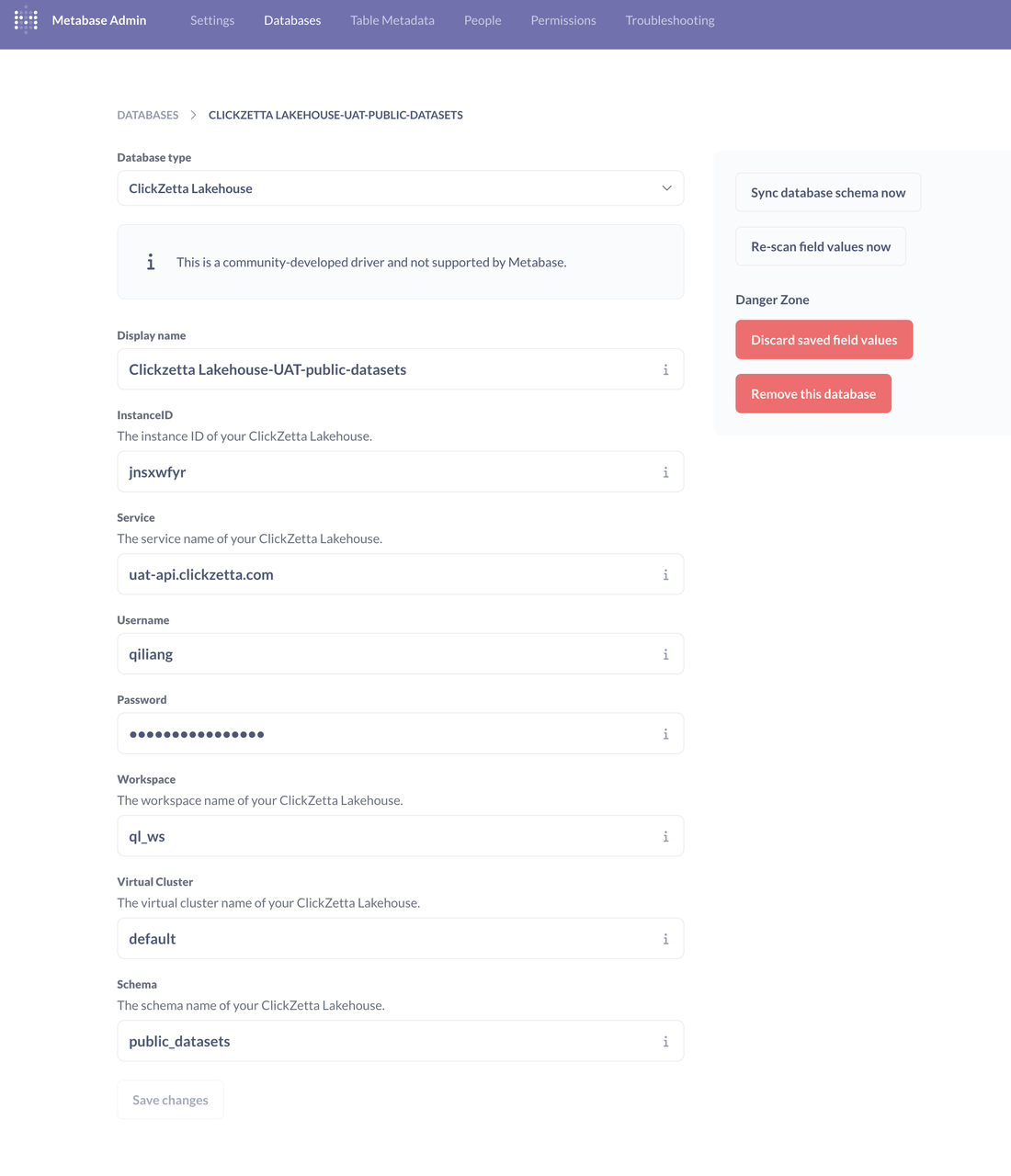
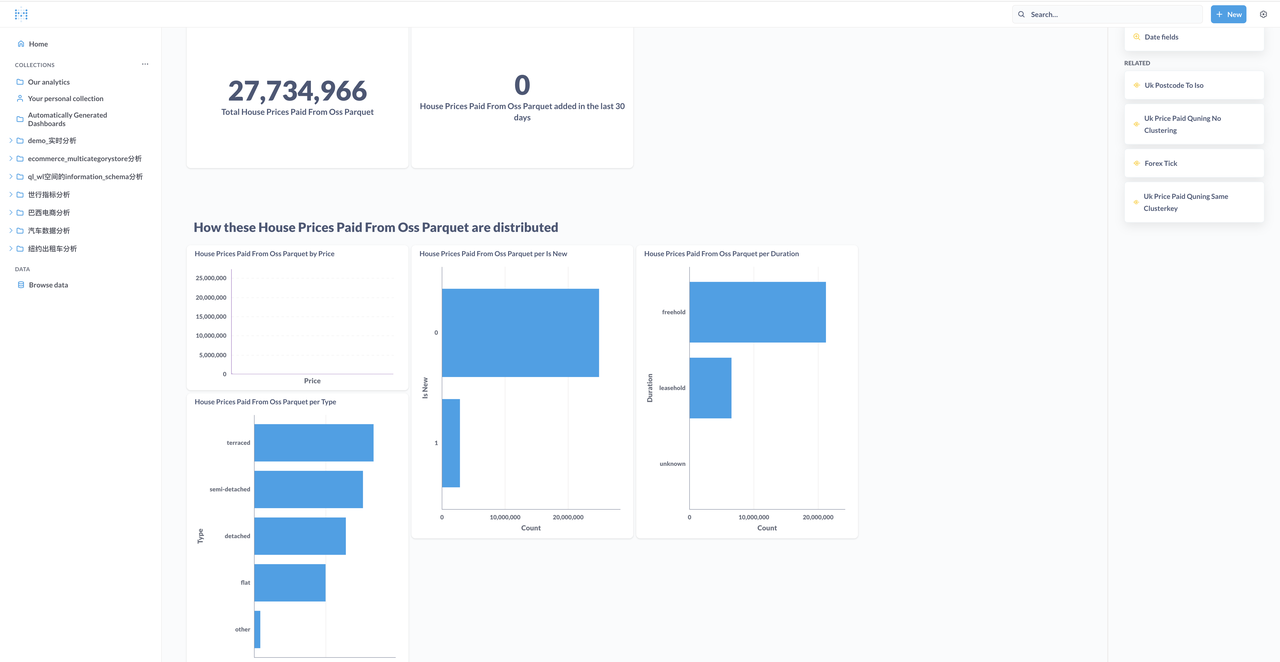
Explore and analyze data through Metabase (just two clicks, yes, just two!)
Select the database and table:
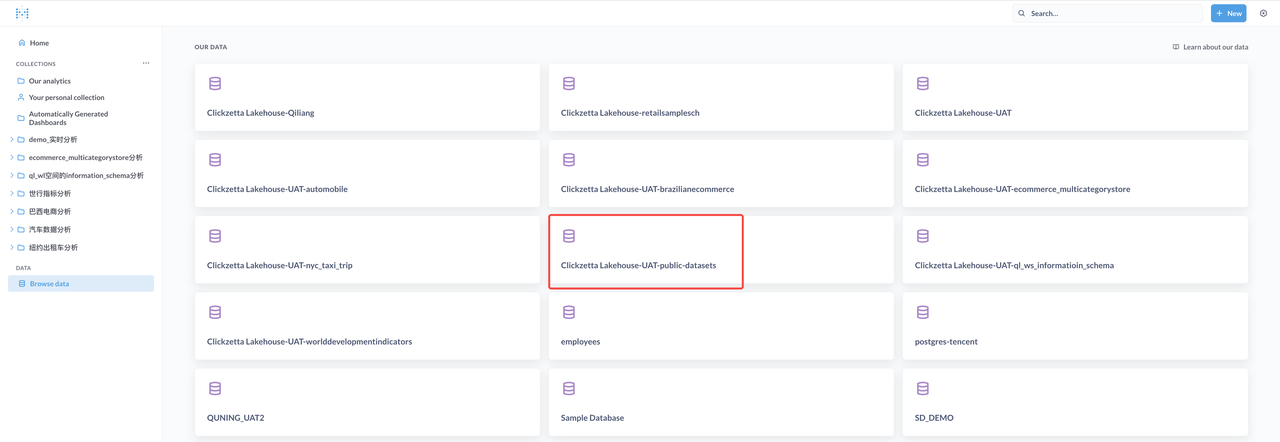
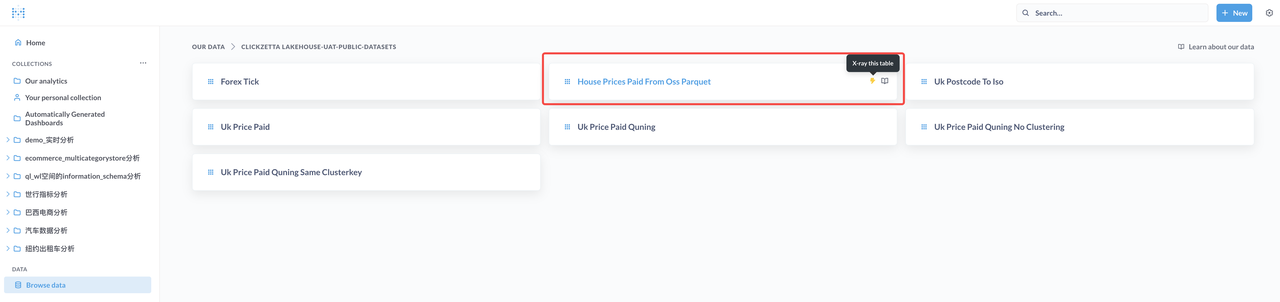
Browse and analyze data through Metabase
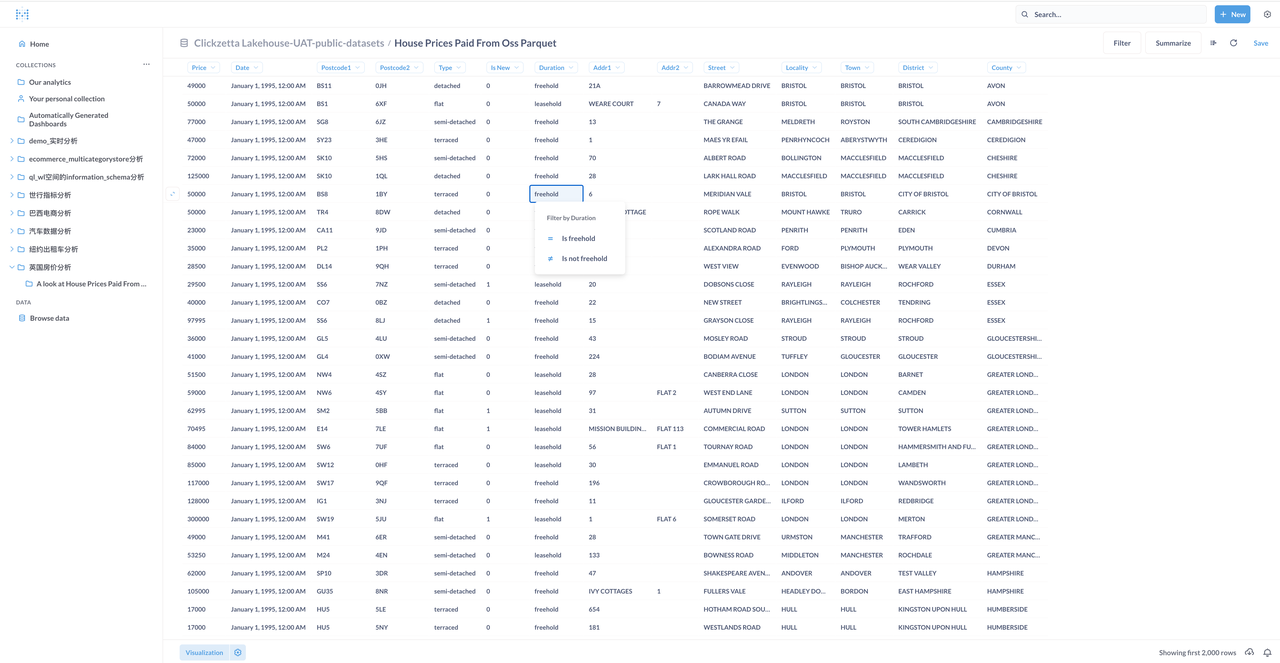
Explore and analyze data through Metabase:
AI Application: Predict and analyze house prices through MindsDB (Only SQL)
The data flow in this section: Zeppelin -> MindsDB -> Singdata Lakehouse.
- Zeppelin creates a new Interpreter connection to MindsDB through MySQL JDBC Driver
- MindsDB connects to Singdata Lakehouse through clickzetta handler (based on python SQLAlchemy)
Build model training data in Singdata Lakehouse
Create a Zeppelin Interpreter to Connect MindsDB via MySQL JDBC
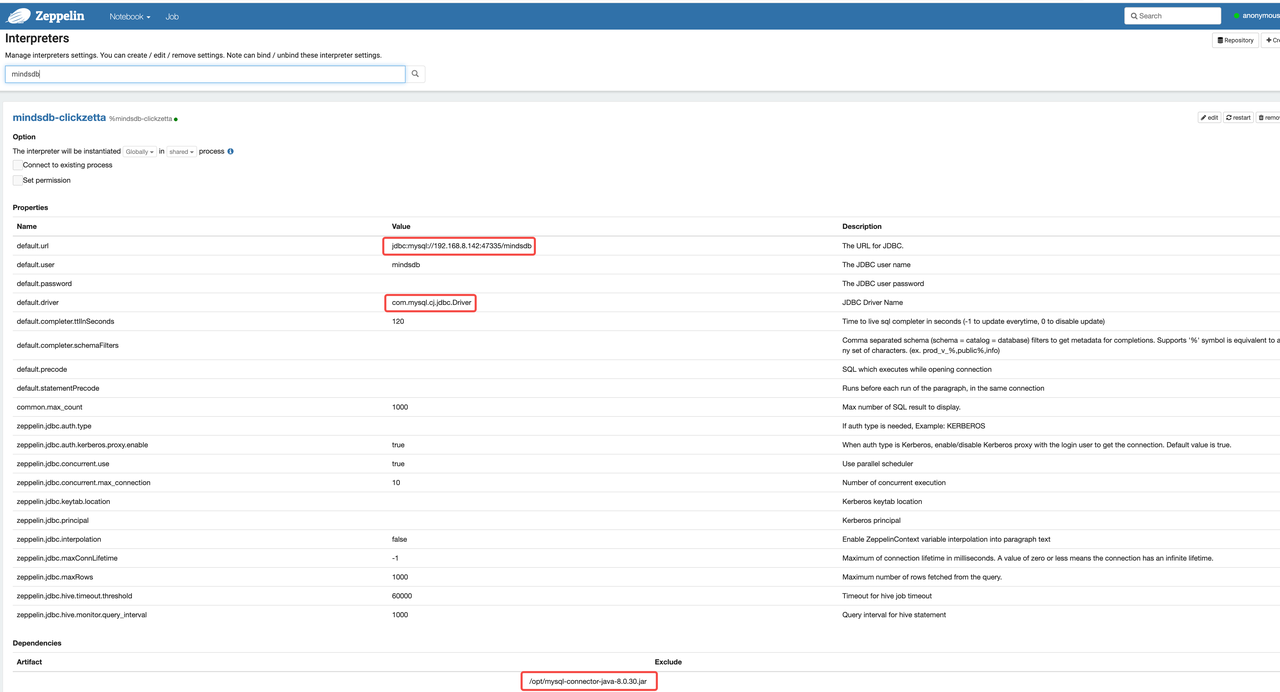
Create a New Notebook in Zeppelin
MindsDB connects to Singdata Lakehouse, using Singdata Lakehouse as a data source
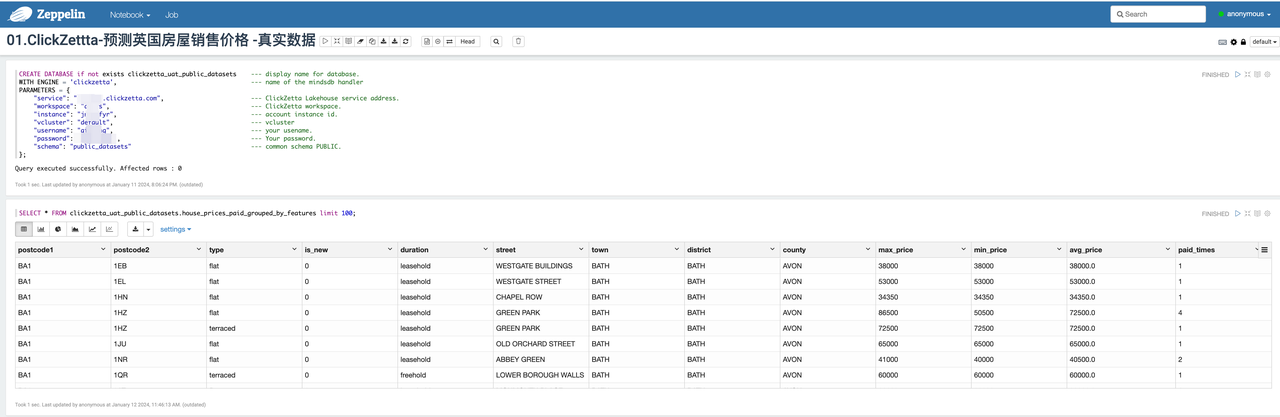
Create Model
Create a prediction model to predict paid_times, which is the number of times a house is sold.
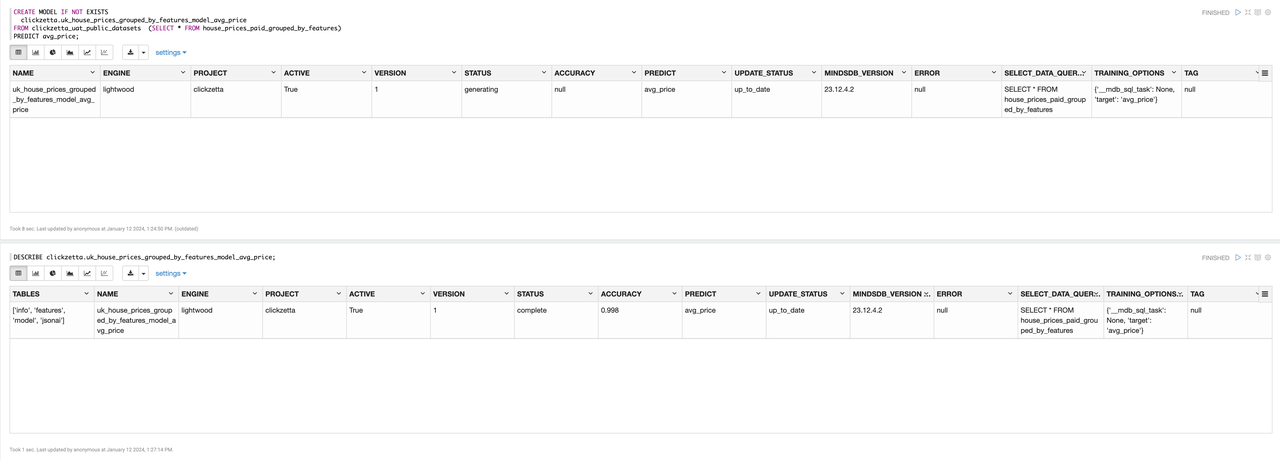
House Price Prediction

Prediction results:
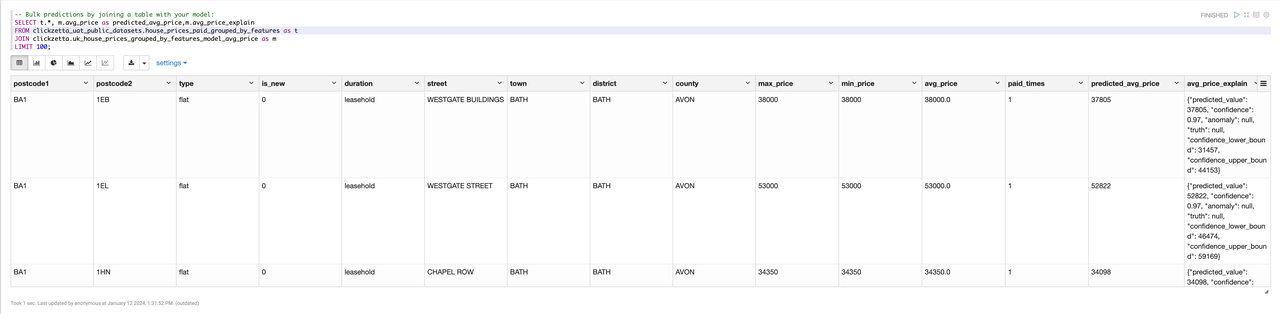
Batch House Price Prediction
Appendix
Metabase, MindsDB, Zeppelin Environment Installation and Deployment Guide
- Metabase with Lakehouse Driver on Docker
- MindsDB with Lakehouse Connector on Docker
- Zeppelin with Lakehouse JDBC Driver
Preview Parquet file schema and data through Python code, and generate Singdata Lakehouse SQL code
Input example: