Building an ELT-Oriented Modern Data Stack Based on Singdata Lakehouse
As enterprise data volumes and data architectures become increasingly complex, companies urgently need to find faster, more efficient, and cost-effective methods for data management and analysis. In recent years, the Modern Data Stack (MDS) has been continuously innovating and developing, attracting widespread attention.
What is MDS?
MDS is a collection of cloud-based data tools and technologies centered around cloud data warehouses, data lakes, or Lakehouses, enabling data storage, processing, analysis, and visualization. Over the past decade, cloud data warehouses represented by Snowflake, AWS Redshift, GCP BigQuery, and MaxCompute have rapidly developed and evolved into Lakehouse architectures that integrate data warehouses and data lakes. They leverage massive parallel processing and SQL support to make big data processing faster and cheaper. On this basis, many low-code, easy-to-integrate, scalable, and economical cloud-native data tools have emerged, such as Fivetran, Airbyte, dbt, dagster, Looker, etc. MDS has changed the way enterprises manage and analyze data, making data more valuable.
Singdata Lakehouse was born in this context. It is a platform focused on data, helping enterprises manage and fully utilize data, providing a new solution for building a modern data stack MDS.
What are the key features of a modern data stack?
- Cloud-first. MDS is cloud-based, offering greater scalability and flexibility, and can easily integrate with existing cloud infrastructure.
- Centered around cloud data warehouses/data lakes/Lakehouses. MDS aims to seamlessly integrate with cloud data warehouses such as Redshift, BigQuery, Snowflake, Databricks, MaxCompute, and Singdata Lakehouse, as well as data lakes and Lakehouses.
- Modular design. MDS prevents vendor lock-in, providing enterprises with greater flexibility and control over their data stack.
- Primarily SaaS or open source. While open source is beneficial, it requires a high level of expertise, making the fully managed SaaS model more popular.
- Lowering the threshold. With MDS, everyone within the enterprise can access and use the data they need, rather than confining data to specific teams or departments. This helps achieve data democratization and fosters a data culture within the enterprise.
Differences between traditional data stacks and modern data stacks
Traditional data stack:
- Requires high technical skills
- Relies on extensive infrastructure
- Time-consuming
Modern data stack:
- Breaks the constraints of cloud and data
- Simple and easy to use
- Toolkits suitable for non-technical personnel and business departments
- Saves time
Why is the data stack important?
"Time is money." This old saying is true, especially for data-driven companies. The efficiency of the data stack in processing raw data determines the speed at which data analysis and data science teams can derive value from the data. Having the right tools is key to a modern data stack and crucial to a company's success.
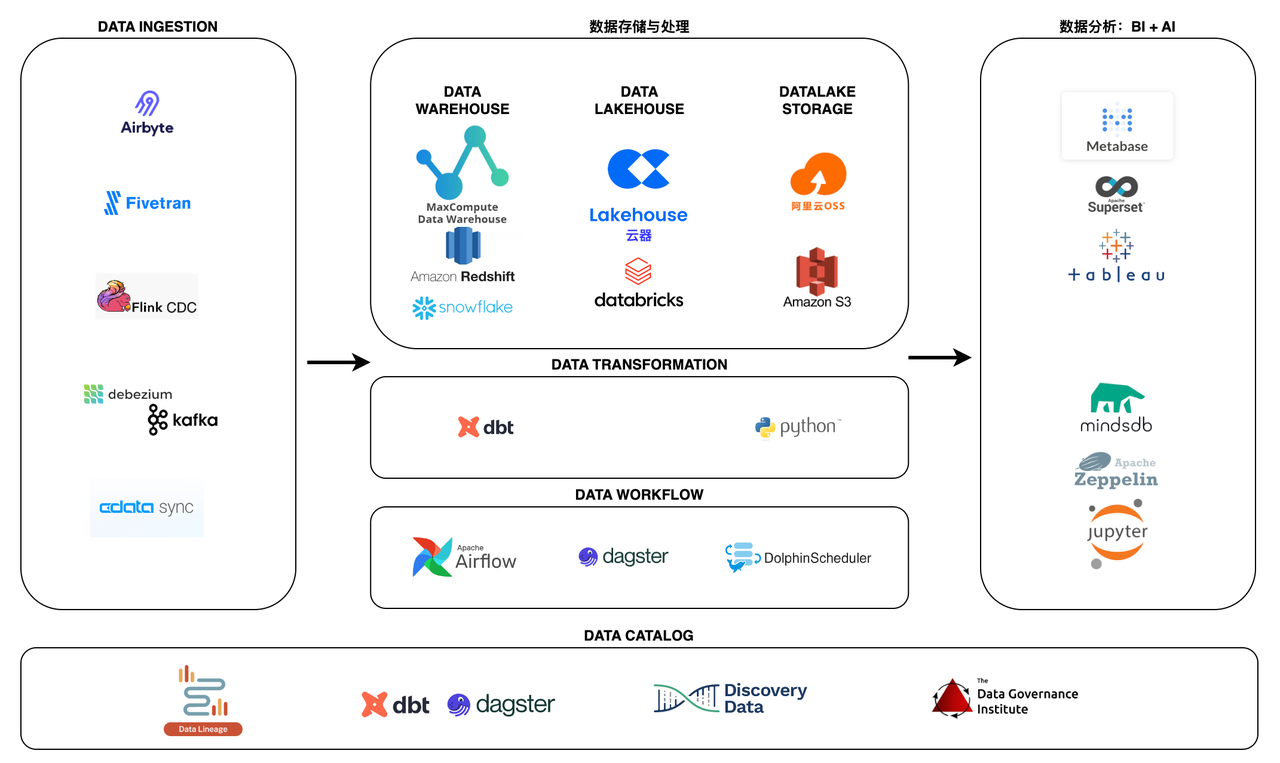
Basic components of MDS
To understand the advantages of MDS tools and make appropriate tool choices, it is first necessary to understand the various components of the data platform and the common functions of the tools that serve each component.
The basic components of a data platform (in the direction of data flow) include:
- Data ingestion (E)
- Data storage and processing (L, data warehouse/data lake/Lakehouse)
- Data transformation (T)
- Metrics layer (Headless BI)
- Business intelligence tools
- Reverse ETL
- Orchestration (workflow engine)
- Data management, quality, and governance
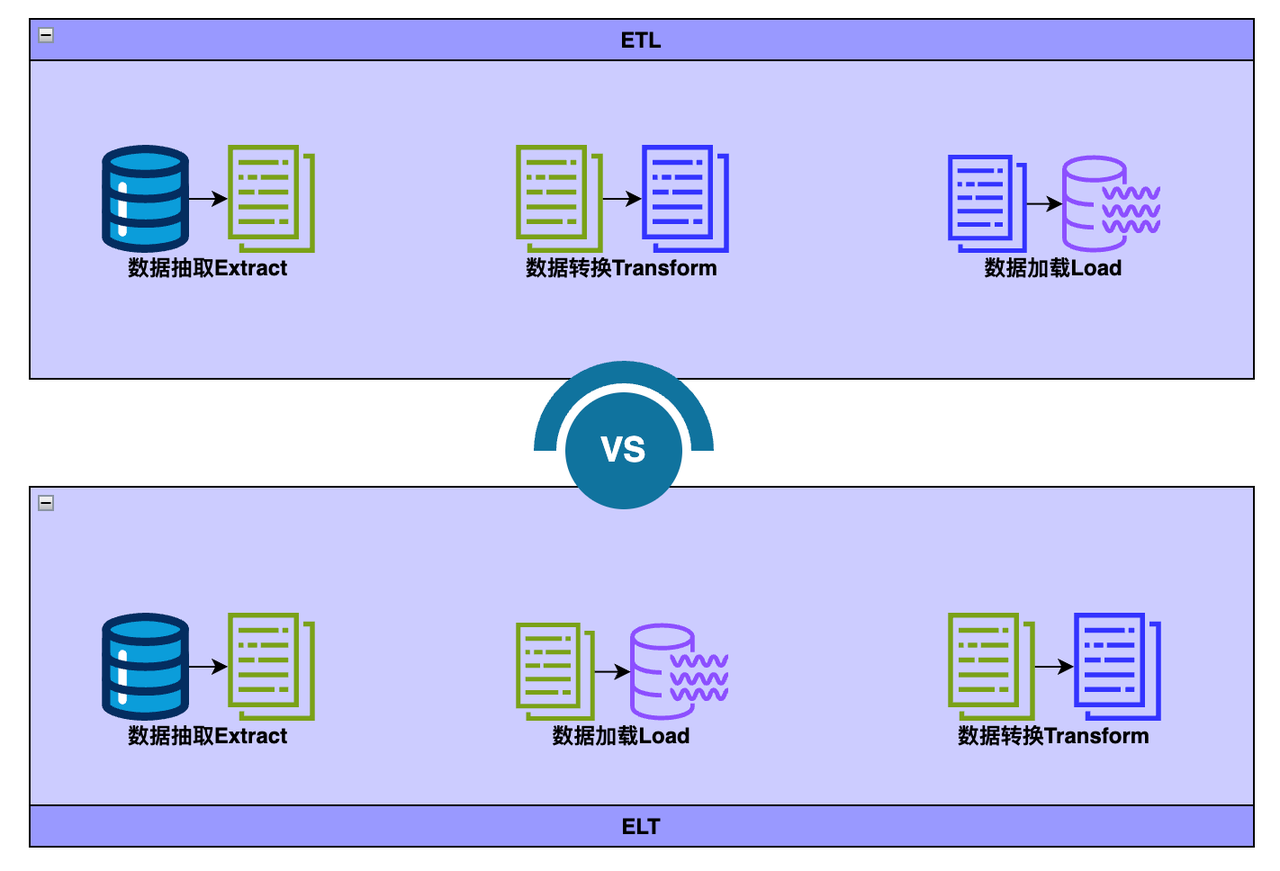
From ETL to ELT
ETL and ELT both describe the process of integrating data for data analysis, business intelligence, and data science in data warehouses or Lakehouses by cleaning, enriching, and transforming data from various sources.
- Extract refers to the process of extracting data from sources such as SQL or NoSQL databases, XML files, or cloud platforms.
- Transform refers to the process of transforming the format or structure of data sets to match the target system.
- Load refers to the process of loading data sets into the target system (data warehouse, Lakehouse).
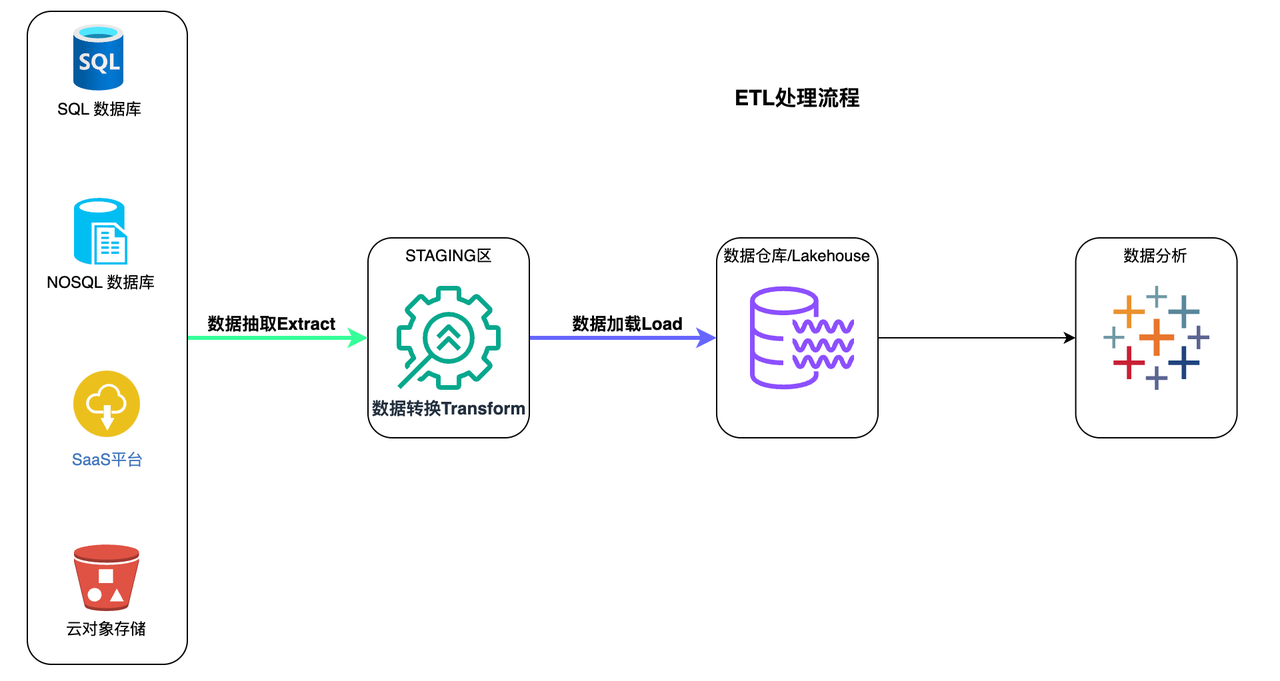
ETL
ETL stands for Extract > Transform > Load
In the ETL process, data transformation is performed in a staging area outside the data warehouse, and the entire data must be transformed before loading. Therefore, transforming large data sets can take a long time, but once the ETL process is complete, analysis can be performed immediately.
ETL process
- Extract a predetermined subset of data from the source.
- Data is transformed in the staging area in some way, such as data mapping, applying concatenation, or calculations. To cope with the limitations of traditional data warehouses, it is necessary to transform the data before loading.
- Data is loaded into the target data warehouse system and is ready for analysis by BI tools or data analysis tools.
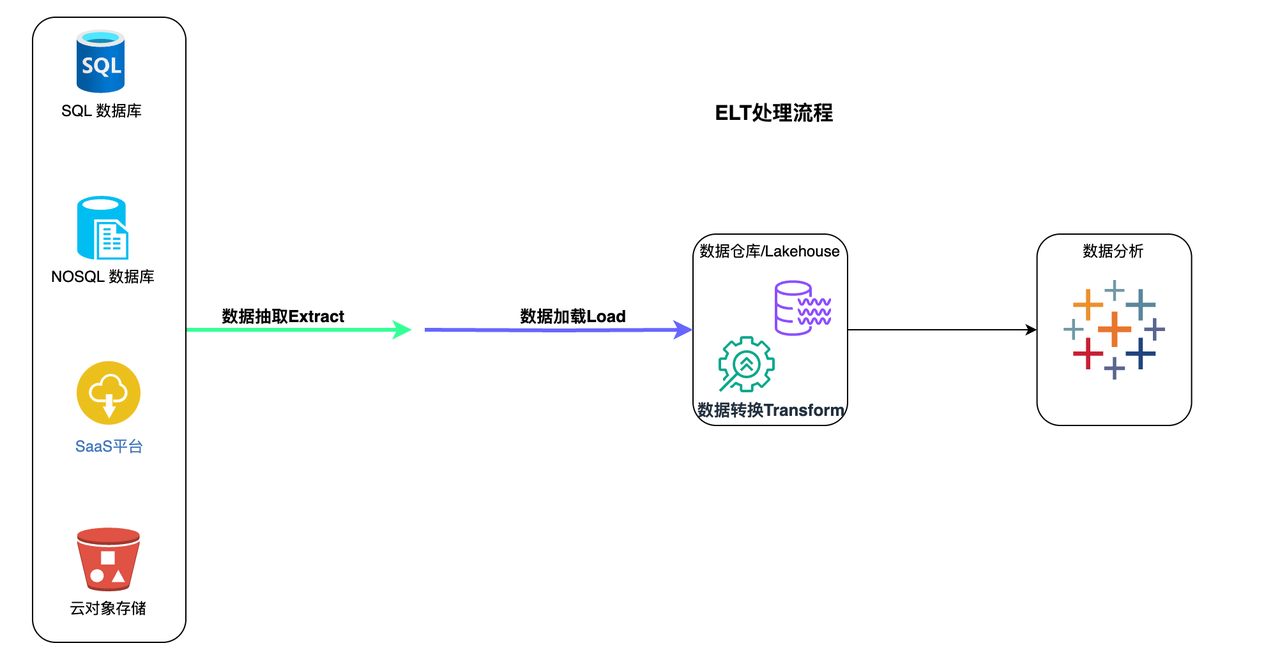
ETL
ELT stands for Extract > Load > Transform
In the ELT process, data transformation is performed as needed within the target system itself. Therefore, the transformation step takes very little time, but if there is not enough processing power in the cloud solution, it may slow down the query and analysis process.
ELT Process
- All data is extracted from the source.
- All data is immediately loaded into the target system (data warehouse, Lakehouse). This can include raw data, unstructured, semi-structured, and structured data types.
- Data is transformed within the target system and prepared for analysis by BI tools or data analysis tools.
Typically, the target system for ELT is a cloud-based data warehouse or Lakehouse. Cloud-based platforms like Amazon Redshift, Snowflake, Databricks, and Singdata Lakehouse offer nearly unlimited storage and powerful processing capabilities. This allows users to extract and load any and all data they might need almost in real-time. Cloud platforms can transform any data needed for BI, analysis, or predictive modeling at any time.
Why Choose ELT?
- Real-time, flexible data analysis. Users can flexibly explore the complete dataset from any direction, including real-time data, without waiting for data engineers to extract, transform, and load more data.
- Lower costs and less maintenance. ELT benefits from the powerful ecosystem of cloud-based platforms, which offer lower costs and various options for storing and processing data. Moreover, since all data is always available and the transformation process is usually automated and cloud-based, the ELT process typically requires very little maintenance.
Building an ELT-oriented Modern Data Stack based on Singdata Lakehouse
The Position of ELT in MDS
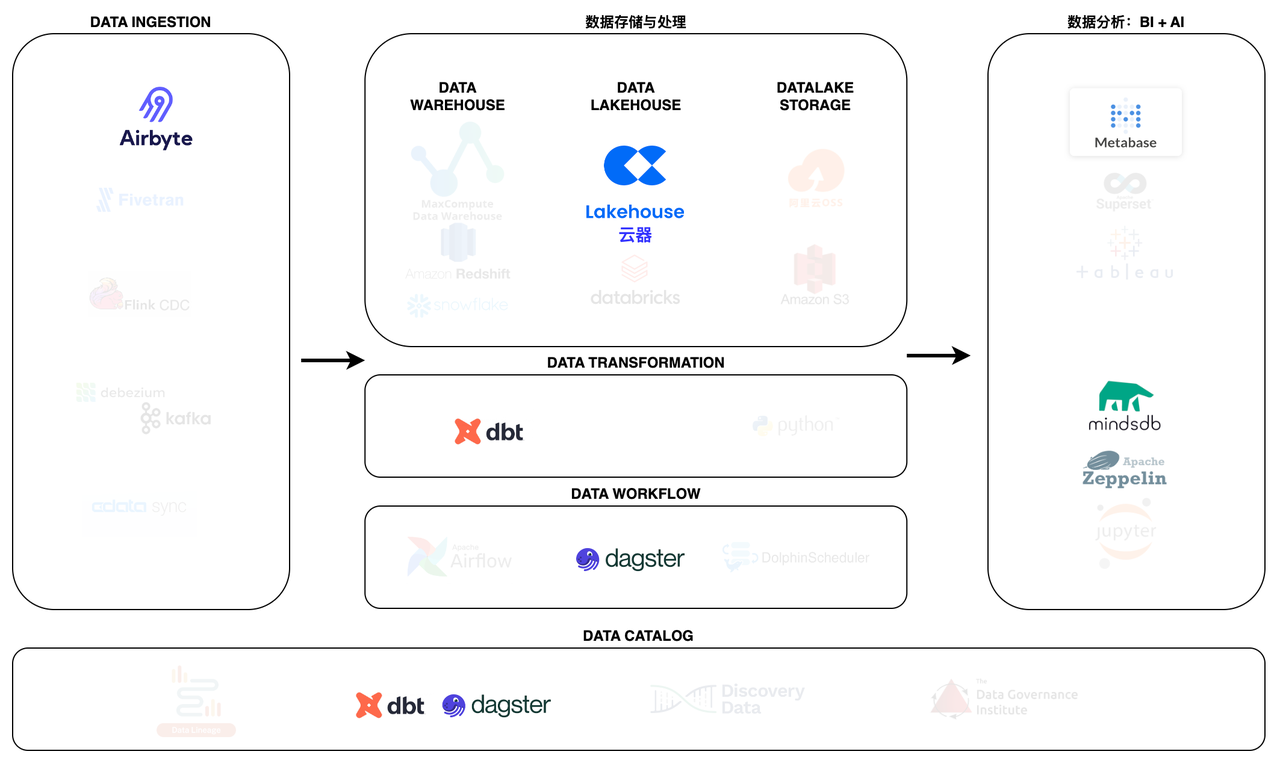
Data Ingestion - Airbyte
Airbyte is a leading data integration platform suitable for ETL/ELT data pipelines from APIs, databases, and files to data warehouses, data lakes, and Lakehouses.
Airbyte already provides over 300 connectors for APIs, databases, data warehouses, and Lakehouses, and developing new connectors is very convenient, known for its support for multiple sources, especially suitable for long-tail data source scenarios.
Data Storage and Processing - Singdata Lakehouse
Singdata Lakehouse is a fully managed data management and analysis service with a lakehouse architecture. Singdata Lakehouse meets the needs of data warehouse construction, data lake exploration and analysis, offline and real-time data processing and analysis, business reporting, and other scenarios with a single engine. It meets the scalability, cost, and performance needs of enterprises at different stages through storage-compute separation, serverless elastic computing power, and intelligent optimization features. Built-in data integration, development and operations, data asset management, and other services are ready to use, greatly simplifying data development and management work, accelerating enterprise data insights and value realization.
Data Transformation - dbt
dbt enables data analysts and engineers to transform data using the same practices that software engineers use to build applications. Analysts using dbt only need to write select statements to transform data, while dbt takes care of turning those statements into tables and views in the data warehouse.
These select statements or "models" form a dbt project. Models often build on each other - dbt can easily manage relationships between models, visualize these relationships, and ensure the quality of transformations through testing.
dbt avoids writing boilerplate DML and DDL by managing transactions, dropping tables, and managing schema changes. *Simply write business logic using SQL select statements or Python DataFrames that return the desired dataset, and dbt takes care of materialization.
dbt generates valuable metadata to find long-running queries and has built-in support for standard transformation models such as full or incremental loads.
Data Workflow - dagster
Dagster is an orchestrator designed to develop and maintain data assets such as tables, datasets, machine learning models, and reports.
You can declare the functions to run and the data assets these functions generate or update. Then, Dagster can help you run your functions at the right time and keep your assets up to date.
Dagster is designed for every stage of the data development lifecycle - local development, unit testing, integration testing, staging environments, all the way to production.
Like dbt, it enforces best practices such as writing declarative, abstract, idempotent, and type-checked functions to catch errors early. Dagster also includes simple unit testing and convenient features to make pipelines reliable, testable, and maintainable. It also integrates deeply with Airbyte, allowing data ingestion as code.
ELT Processing Flow
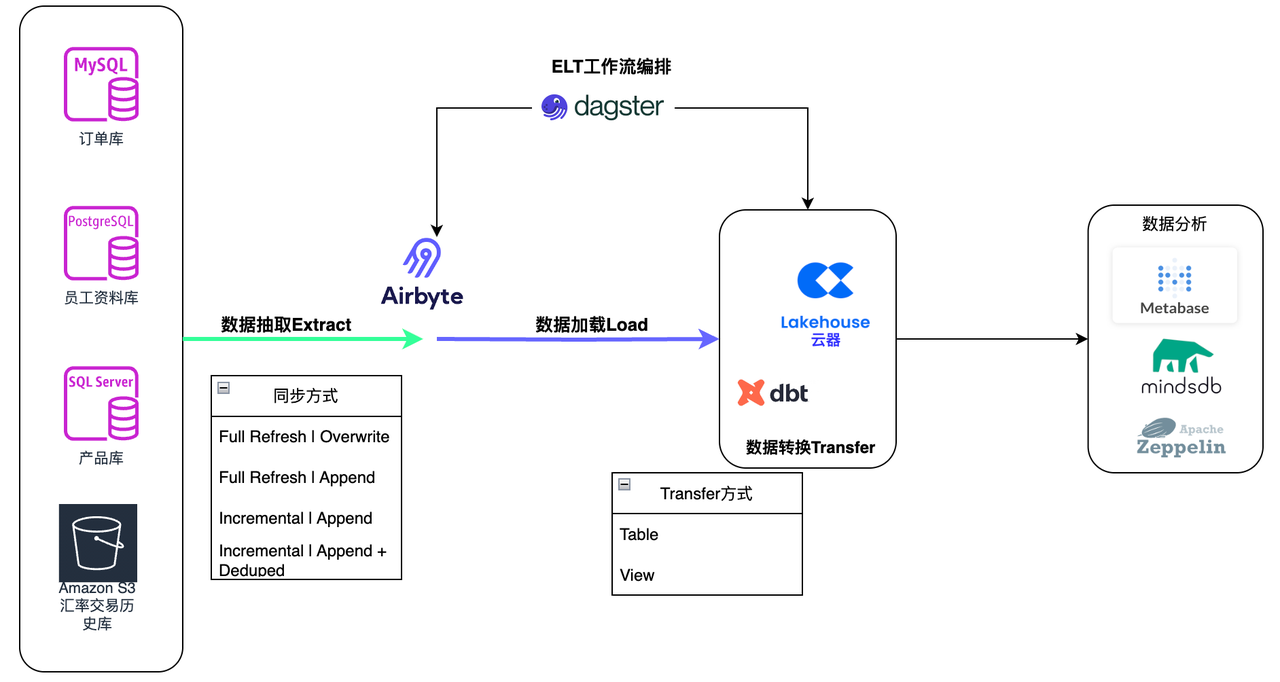
Data Extraction and Loading (Airbyte)
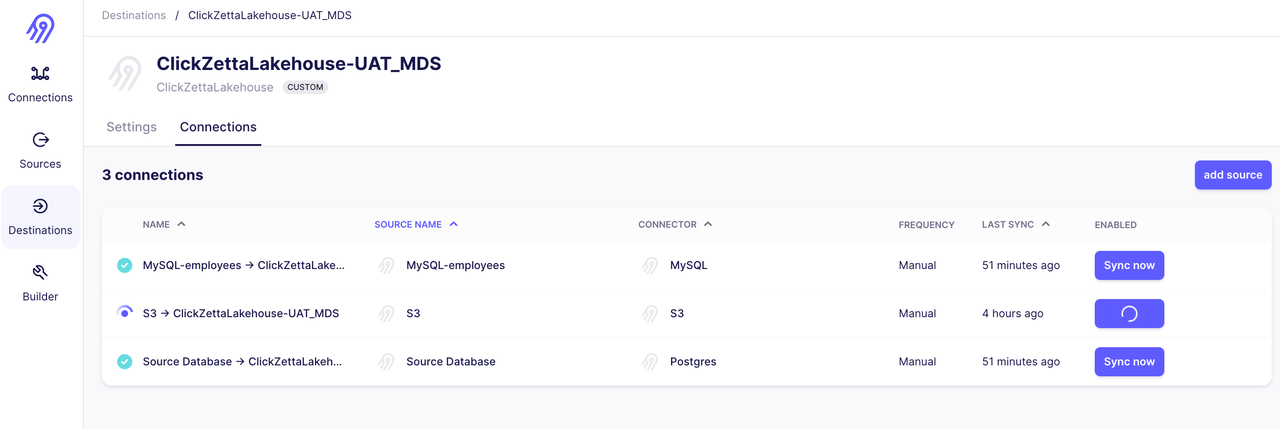
Using Singdata Lakehouse as Airbyte's Destination Connector
Synchronize Employee Database via Incremental | Append + Deduped Method
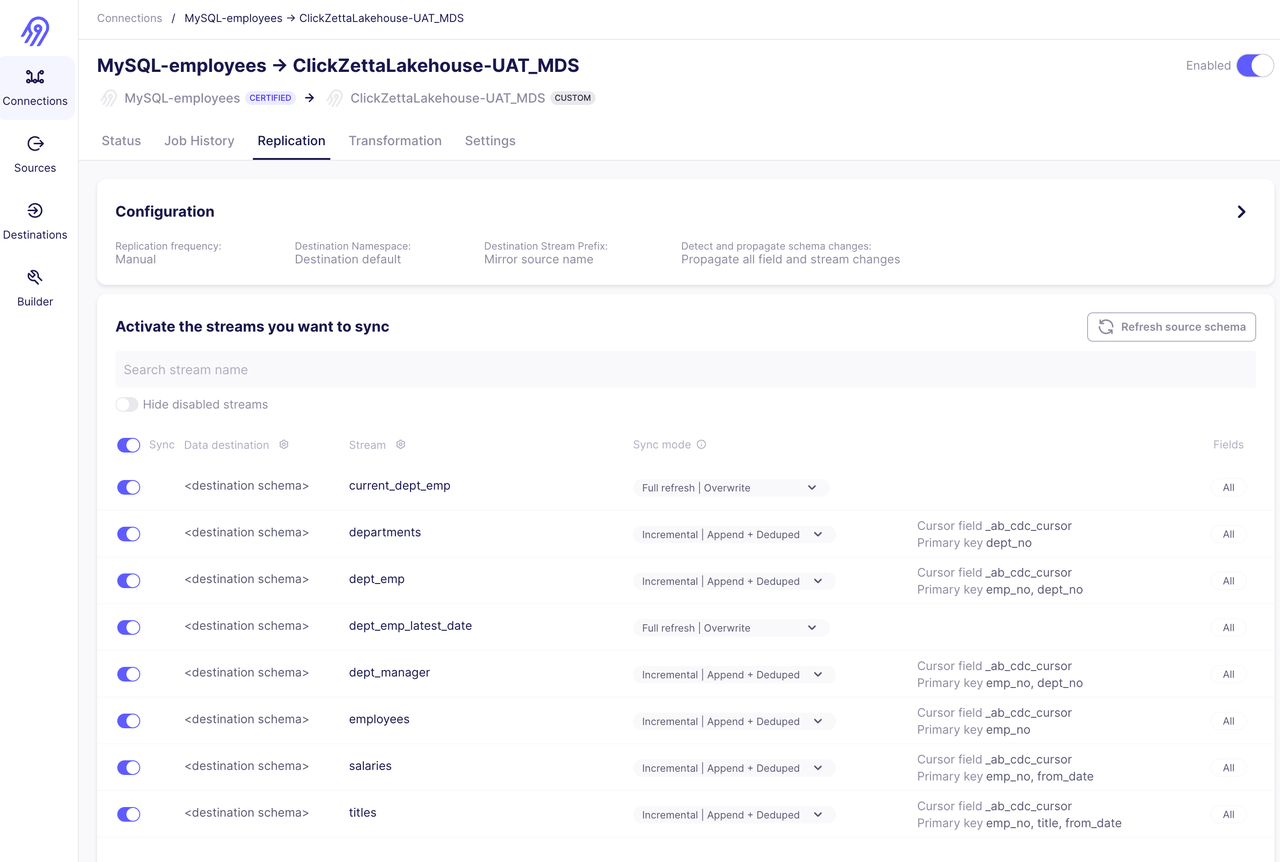
Synchronize Historical Forex Trading Data in Parquet Format on S3
Data Transformation (dbt)
Configure DBT's profile.yml
The target here points to clickzetta_uat, which means that the data transformations in this project will run on clickzetta_uat. The target table will be output to the modern_data_stack schema in the ql_ws workspace of the Singdata Lakehouse. The computing resources will use a vcluster named default.
Define DBT's source.yml
Develop DBT Transformation Models
DBT will generate a target table or view with the same name as the file based on the SELECT statement, which is confirmed by the configuration in dbt_project.yml. For example:
models:
mds_dbt:
+materialized: "table"
indicates that the data transformation target type is a table, not a view. If a view needs to be generated, it should be set to:
models:
mds_dbt:
+materialized: "view"
The following is the data transformation model:
user_augmented.sql
orders_cleaned.sql
daily_order_summary.sql
employees_detail_single_view.sql
Define DBT's schema.yml
DBT debug、compile
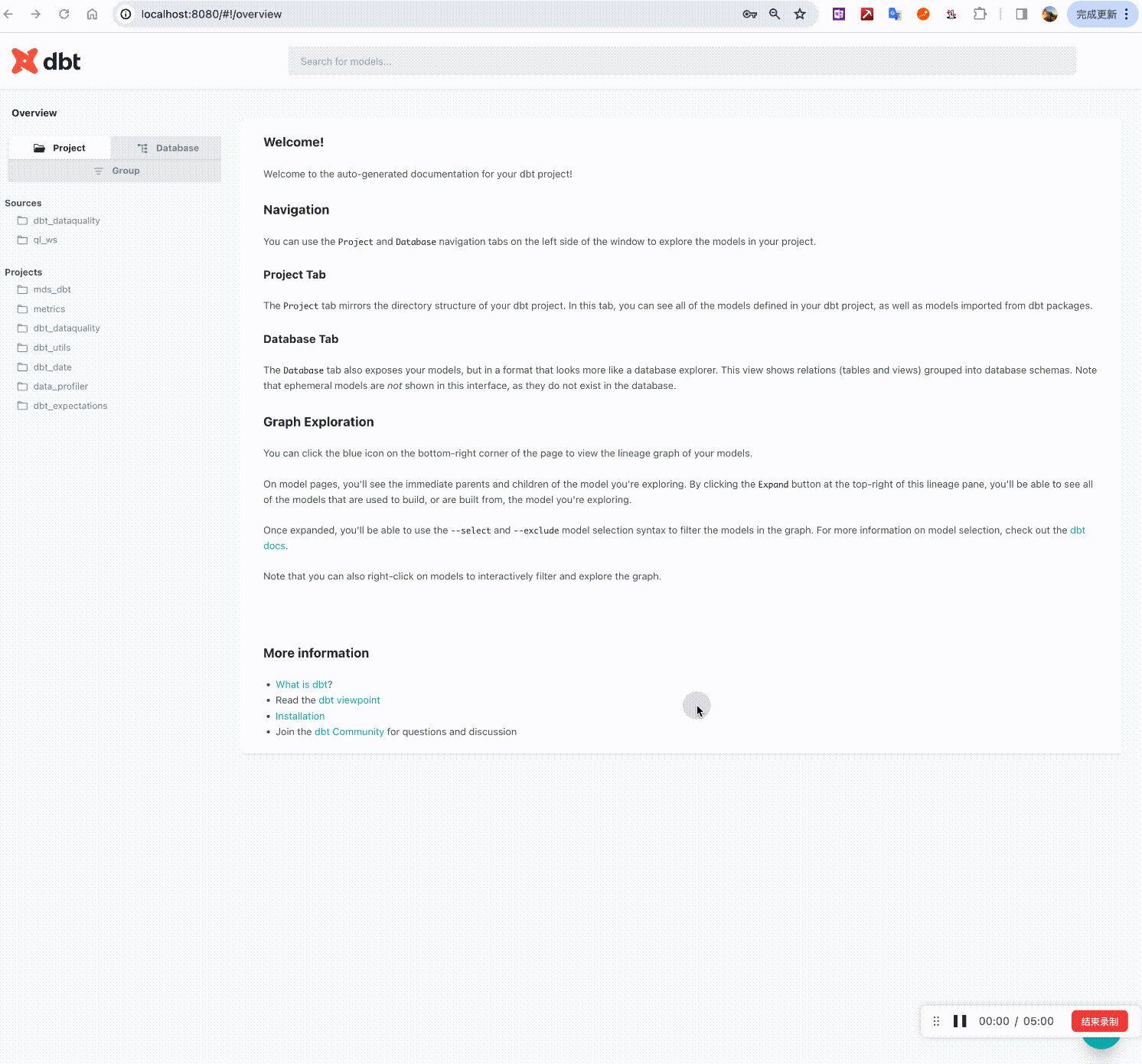
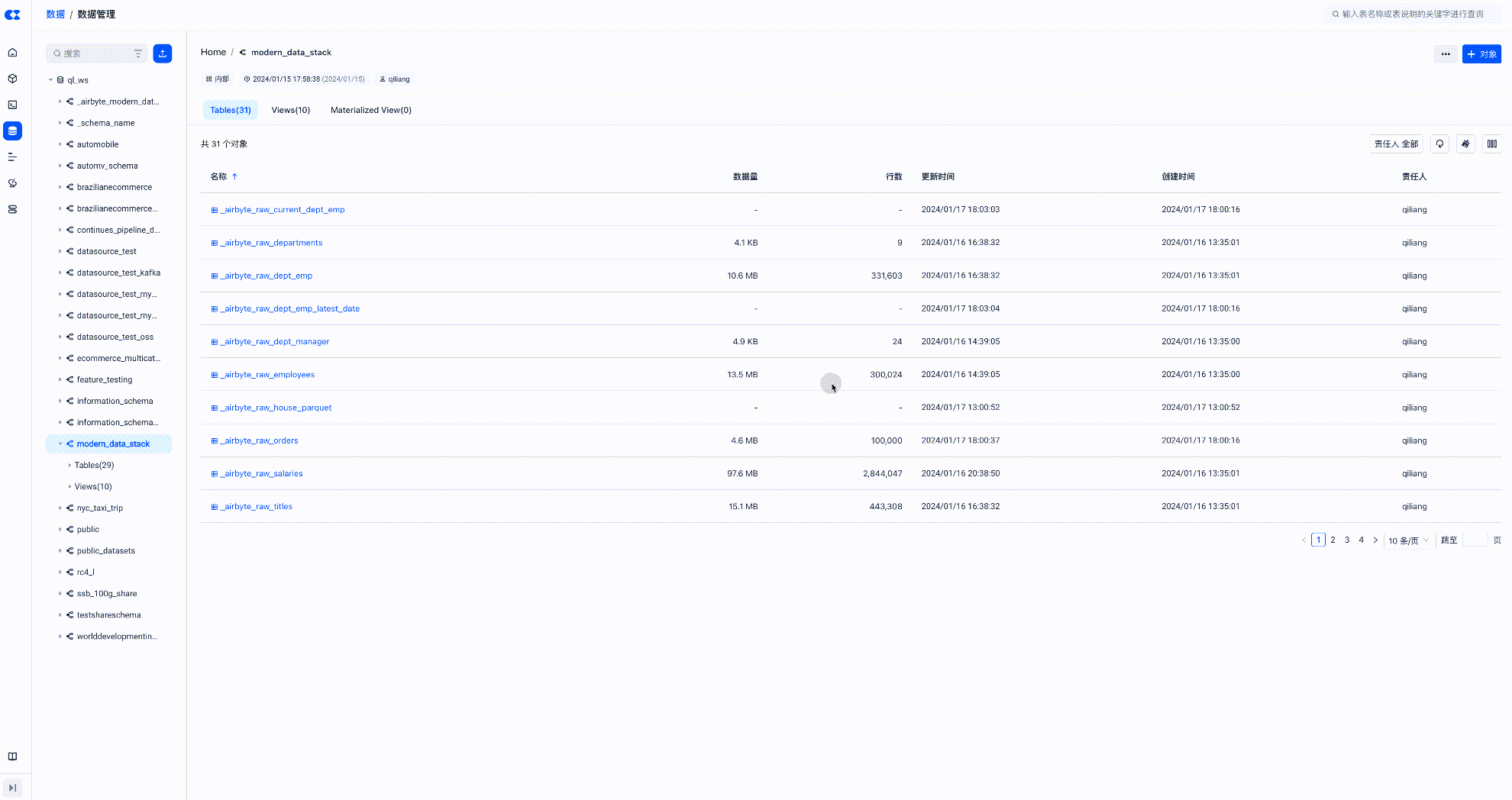
Check if the Data Lineage is Correct
自动弹开:http://localhost:8080/#!/overview
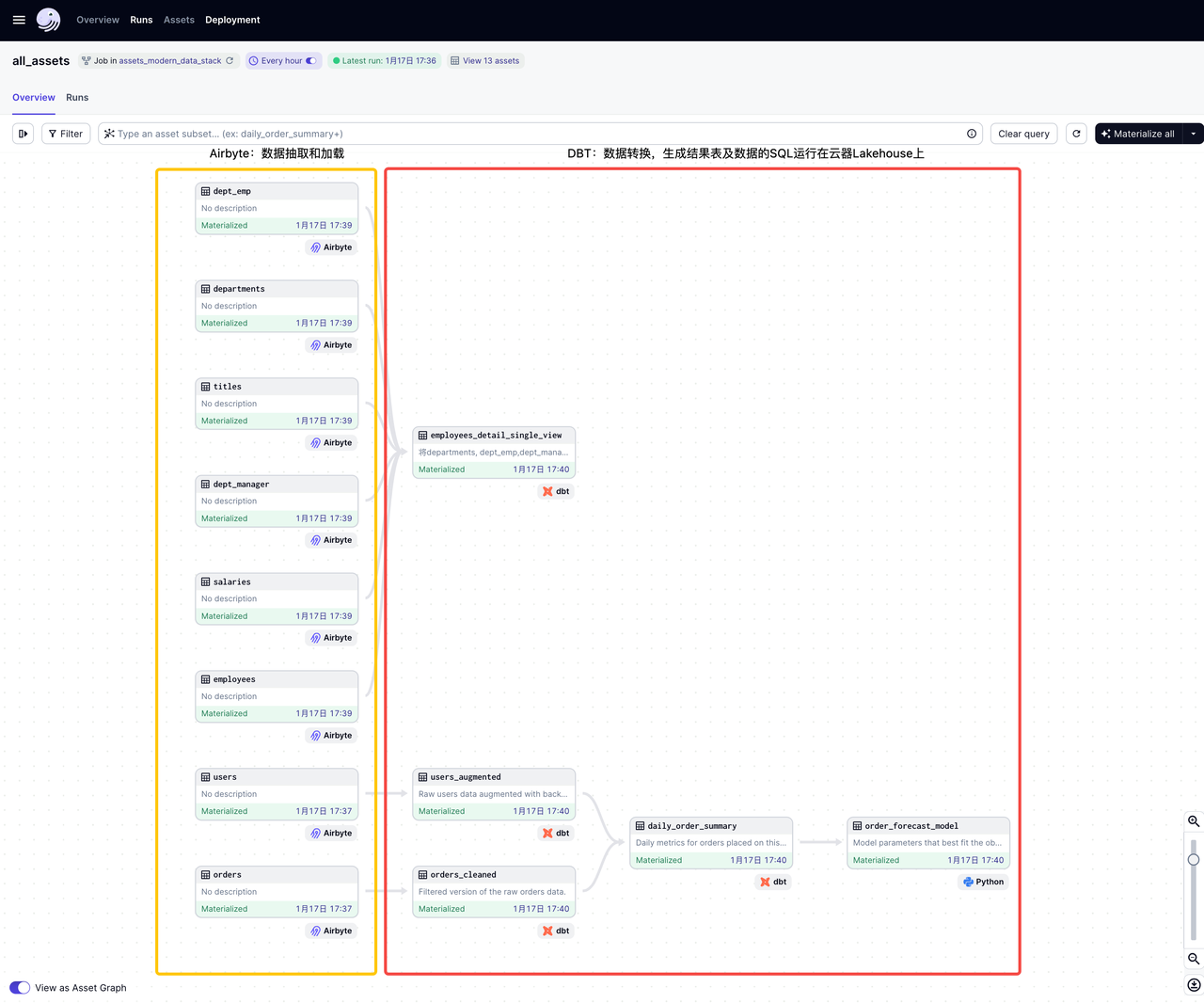
Workflow Orchestration (dagster)
dagster implements a software-defined, ETL pipeline complete data workflow DAG diagram, which is very clear and readable:
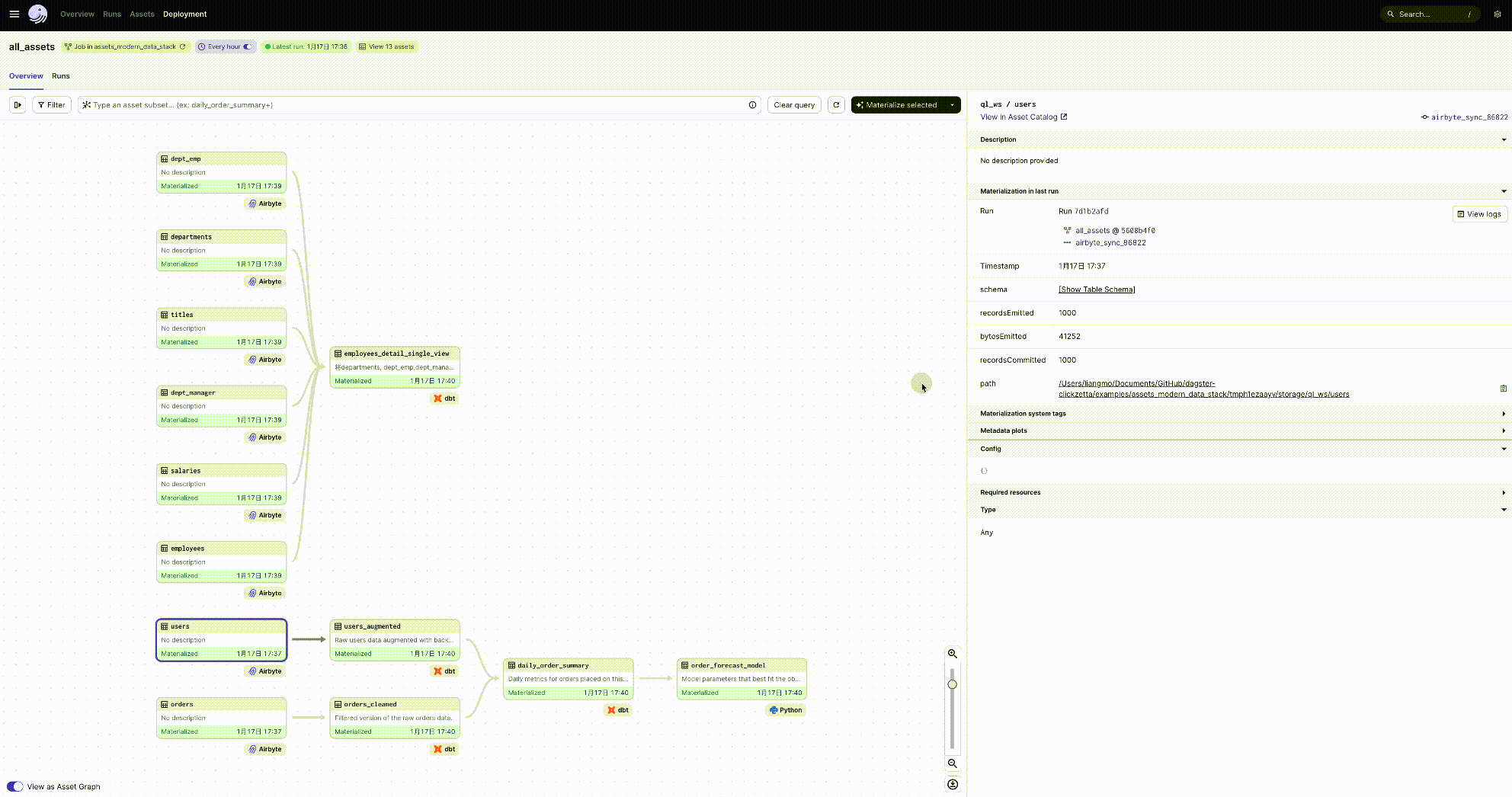
View the Target Table of Data Transformation on Singdata Lakehouse
Next Steps
So far, we have reviewed the differences between the modern data stack and the traditional data stack, discussed the differences between ETL and ELT, and how to build a complete ELT-oriented modern data stack based on Singdata Lakehouse, Airbyte, DBT, and Dagster.
Once the data enters the Singdata Lakehouse, the next step is how to analyze the data. Please read: Building an Analytics-Oriented Modern Data Stack Based on Singdata Lakehouse
Appendix
Airbyte Installation and Deployment Guide
DBT Installation and Deployment Guide
dagster project: https://github.com/yunqiqiliang/dagster-clickzetta/tree/master/examples/assets_modern_data_stack