Scaling to Billions: How Rednote Built a Near Real-Time Data Warehouse Using Incremental Compute
Authors
Marco (Wu Haoliang) Head of Transaction and Core Data Warehouse at Rednote, specializing in data architecture with deep expertise in offline/real-time data warehouses, OLAP systems, and data lake implementations across diverse use cases.
Sun Wu (Shi Yuhao) Data Warehouse Engineer at Rednote, leading real-time data warehouse initiatives for transaction systems and pioneering near real-time data warehouse solutions.
Huang Yuan (Wu Xiaoqi) Data Warehouse Engineer at Rednote, focusing on attribution modeling and data pipeline performance optimization.
Yu Shi (Zhang Kebing) Data Platform Engineer at Rednote, building advanced query capabilities for the BI platform.
TL;DR
As mobile social media & content platforms experience explosive growth, Rednote now processes hundreds of billions of log events daily. Traditional data architectures struggle to balance cost efficiency with low-latency requirements for algorithmic experimentation. Partnering with Singdata, we've implemented a near real-time experimental data warehouse powered by incremental computing and data lake technologies. This solution delivers significant improvements: reduced infrastructure costs, enhanced data accuracy, streamlined batch-stream unification, and superior query performance—establishing the foundation for enterprise-wide near real-time analytics.
1. The Challenge
The modern content ecosystem has reached unprecedented scale. User bases continue expanding while engagement patterns intensify, creating a perfect storm of exponential data growth. At Rednote, we're now ingesting hundreds of billions of log events daily. Simultaneously, our machine learning teams demand faster iteration cycles for algorithmic experiments, pushing beyond what traditional offline batch processing can deliver.
This creates a classic engineering dilemma. Batch processing offers cost efficiency but lacks the responsiveness needed for real-time decision making. Stream processing provides low latency but demands persistent resource allocation with complex operational overhead, typically limited to critical paths or sampled datasets.
Enter incremental compute—a paradigm that processes only data deltas while maintaining minute-level freshness. By dynamically compute changes and merging results with previous states, it bridges the gap between batch economics and streaming responsiveness. This approach enables flexible scheduling intervals, distributes computational load to avoid resource contention, and fundamentally reimagines the stream-batch dichotomy.
As China's leading social media platform, Rednote operates massive near real-time workloads across recommendation engines, search systems, and monetization platforms. Singdata brings cutting-edge incremental compute expertise as one of Asia's pioneering vendors in this space. Our joint initiative aims to deliver China's first hundred-billion-scale end-to-end incremental compute pipeline, focusing initially on real-time algorithmic experimentation metrics.
1.1 Understanding the Use Case
Real-time experiment metrics serve as mission-critical observability tools for our ML engineering teams. Every experiment launch requires immediate visibility into performance differences across treatment groups, with data accuracy remaining paramount. Our algorithms frequently adjust parameters every 30 minutes based on real-time signals, making rapid feedback loops essential for optimization.
The technical requirements are demanding:
Sub-minute latency: Algorithm teams need minute-level freshness to support rapid parameter tuning while maintaining cost efficiency.
Query performance: Processing hundreds of billions of daily logs requires sub-second response times for complex analytical queries—a significant computational challenge.
Data fidelity: Experiment metrics demand high precision without sampling, maintaining less than 1% variance between real-time and batch results.
1.2 Legacy Architecture Limitations
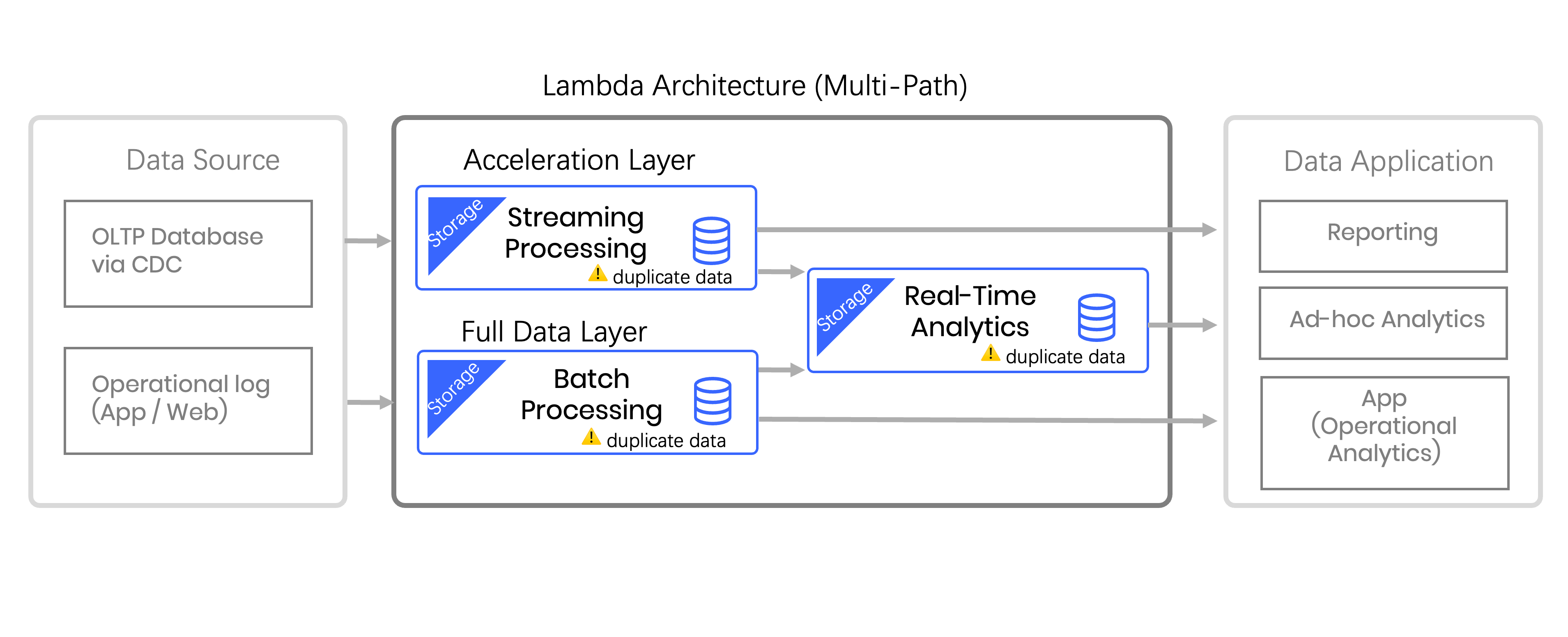
Our existing infrastructure separates offline and real-time metrics into distinct architectural stacks. The offline pipeline ingests ODS data into our data lake, leveraging Spark for daily aggregations before writing DWS tables to ClickHouse. Meanwhile, the real-time pipeline processes Kafka streams through Flink, writing detailed DWD data directly to ClickHouse with necessary sampling to manage volume.
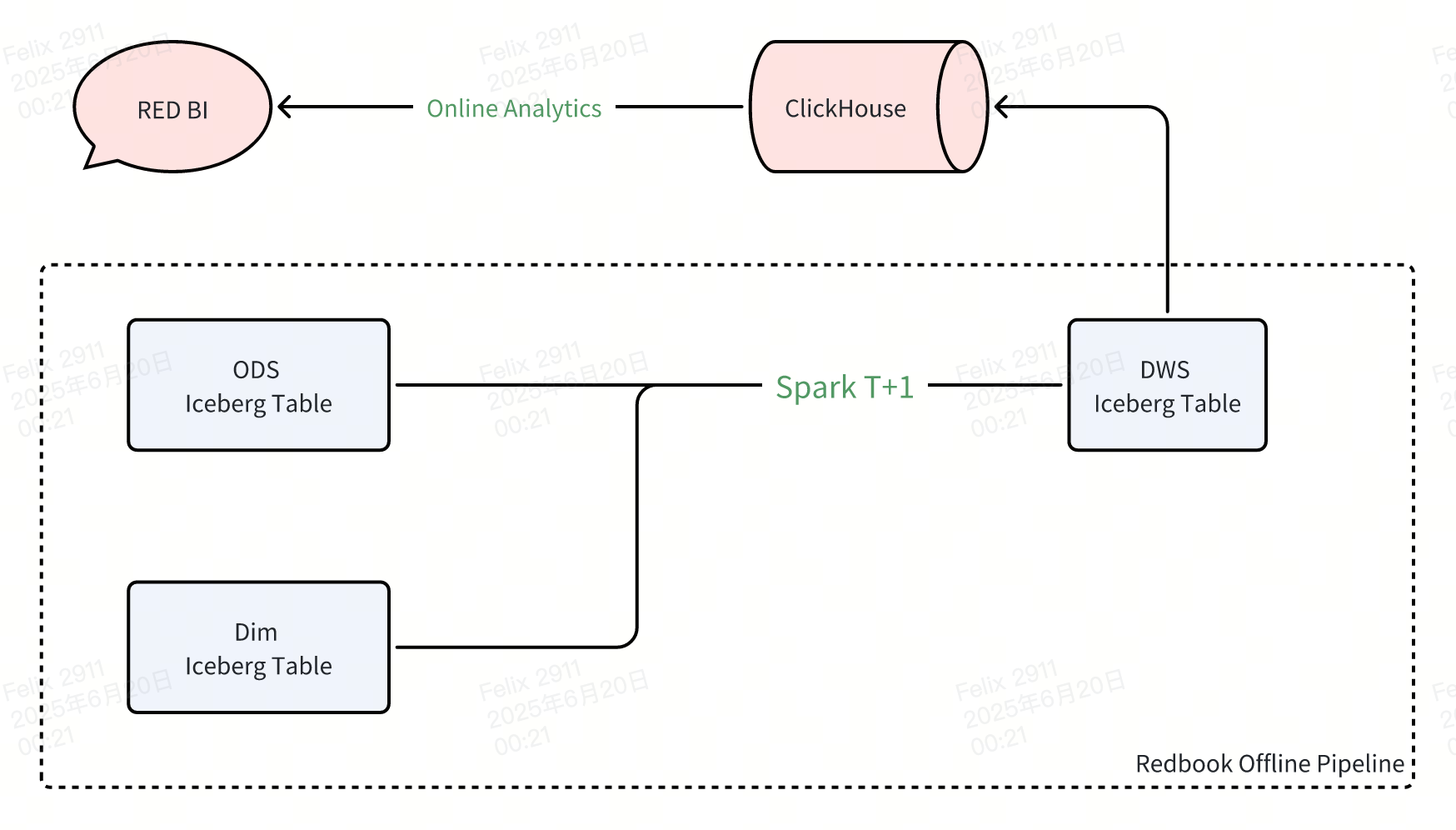
This Lambda architecture introduces several pain points:
Data inconsistency: Real-time and offline systems produce divergent results due to sampling logic and processing differences, undermining data confidence.
Operational complexity: Maintaining separate Flink streaming and Spark batch semantics requires duplicate effort with different SQL dialects and dimension table logic.
Windowing constraints: Stream processing memory limitations prevent large window operations, while out-of-order data handling complicates state management.
Resource inefficiency: Flink's persistent resource allocation scales linearly with data volume, creating unsustainable cost growth.
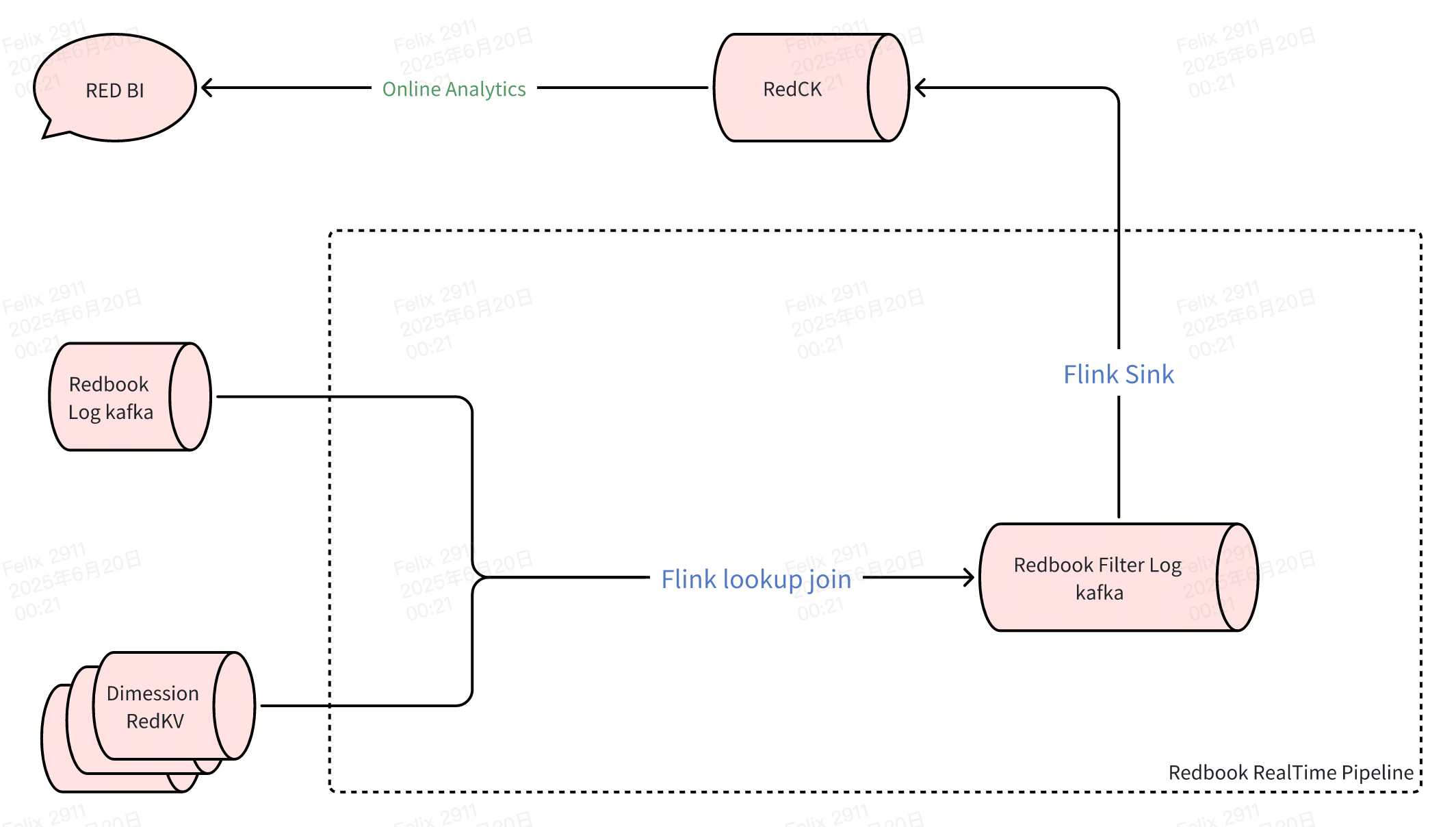
When Kafka experiences delays requiring full reprocessing of hundred-billion-record partitions, resource demands become prohibitive, making recovery practically impossible.
1.3 Root Cause Analysis
Real-Time vs Offline Data Inconsistencies
Our Lambda architecture creates fundamental inconsistencies between real-time and offline data pipelines. The real-time system relies on sampling logic to manage computational load, making it impossible to maintain data consistency with offline results. This sampling introduces variance that undermines confidence in real-time metrics, creating a trust gap for business stakeholders who need reliable data for decision-making.
The offline pipeline processes complete datasets with comprehensive dimensional coverage, but operates on T+1 schedules that can't meet real-time business requirements. When Kafka experiences failures or delays, the system requires full reprocessing of hundred-billion-record daily partitions—a computationally prohibitive operation that's rarely feasible in practice. Recovery scenarios essentially become impossible due to resource constraints.
Meanwhile, our real-time pipeline achieves sub-second latency but demands persistent allocation of high-specification compute resources, driving storage costs to unsustainable levels. To manage this overhead, we've had to sacrifice dimensional richness by trimming non-essential attributes, resulting in less comprehensive metrics compared to offline processing. This creates a fundamental tension between timeliness, cost efficiency, and data completeness, forcing business teams to maintain parallel statistical systems with similar logic but divergent results. Ensuring data consistency across these dual systems becomes an ongoing operational challenge.
Pipeline Complexity and Maintenance Overhead
Rednote's real-time architecture combines separate log ingestion and dimension table update pipelines, each requiring distinct maintenance approaches. Log ingestion flows through Flink stream processors, while dimension updates involve multiple Flink jobs writing to Redis key-value stores, followed by stream join operations, and finally append-only writes to ClickHouse.
This separation creates significant operational complexity because Flink's streaming SQL semantics differ fundamentally from Spark's batch processing model. Dimension table generation logic must be implemented differently across systems, leading to code duplication and increased maintenance burden. Engineering teams must develop expertise in multiple processing paradigms while ensuring logical consistency between implementations. The result is higher development velocity friction and increased operational risk from managing parallel processing pipelines.
Streaming Window Size Limitations
Stream processing architectures face inherent constraints when handling large temporal windows due to memory management and state persistence requirements. Real-time processing must maintain all window data in memory to support incremental computation, creating state explosion when window durations extend beyond optimal ranges. As traffic volumes continue growing, these memory requirements become increasingly problematic.
Out-of-order data handling compounds these challenges in real-time scenarios. Large windows extend data buffering periods, causing computation delays to cascade and potentially resulting in data loss when buffers overflow. To maintain data freshness guarantees, Rednote's real-time pipelines typically reduce window sizes, limiting analytical capabilities for use cases requiring longer temporal aggregations. This constraint forces architectural trade-offs between real-time responsiveness and analytical depth.
Escalating Infrastructure Costs
Flink's resource model requires persistent compute allocation with dedicated resource pools that scale proportionally with data volume. As Rednote's traffic logs continue expanding, computational state requirements grow correspondingly, driving real-time infrastructure costs higher each quarter. Unlike batch processing that can leverage shared compute resources during scheduled windows, streaming jobs maintain constant resource consumption regardless of actual processing load.
This economic model becomes unsustainable at hundred-billion-scale data volumes, where streaming infrastructure costs can exceed the business value derived from real-time insights. Cost optimization strategies typically involve reducing analytical scope or accepting higher latency—both compromising the original real-time processing objectives. The challenge requires rethinking fundamental assumptions about resource allocation models for large-scale real-time analytics.
1.4 Solution Requirements
We needed a unified approach delivering more accurate data, comprehensive metrics, faster queries, simplified pipelines, and efficient development workflows. The solution required building a near real-time pipeline that balances business freshness requirements with operational costs.
2. Technology Evaluation
2.1 Open Source Approach: Paimon + Iceberg
The open source ecosystem lacks mature end-to-end near real-time solutions for enterprise workloads. However, combining emerging technologies could potentially construct minute-level data pipelines suitable for our requirements.
a). Paimon's Dynamic Table Evolution
Paimon introduces dynamic dimension tables with partial update capabilities that fundamentally change traditional data processing approaches. Historically, real-time dimension table updates required complex Flink + Redis architectures for lookup joins. Paimon enables real-time updates and associations directly on data lake storage, eliminating separate caching infrastructure while supporting efficient incremental updates across multiple dimension tables.
The key advantage lies in seamless integration with offline Spark minute-level scheduling, creating unified processing architecture bridging batch and streaming paradigms. Partial update mechanisms enable selective column updates without full row rewrites, crucial for maintaining performance when dimension tables receive frequent updates across different attributes.
b). StarRocks MPP Analytics
StarRocks provides mature massively parallel processing(MPP) architecture optimized for OLAP workloads. The engine directly consumes Iceberg table data from production pipelines, eliminating additional data movement while maintaining sub-second query performance for complex analytical workloads. Its cost-based optimizer and vectorized execution enable sophisticated dimensional analysis required for experiment metrics.
The active open source community ensures ongoing improvements in data lake integration and query optimization, providing confidence in long-term viability for our use case.
Integration Strategy and Limitations
This approach leverages Flink + Paimon to resolve data lake dimension table bottlenecks, accelerating T+1 offline processes to 5-minute delays. StarRocks provides direct data lake consumption, further reducing production-to-consumption latency. The result would be end-to-end near real-time processing maintaining data lake flexibility with real-time performance characteristics.
However, multi-component architecture introduces significant integration complexity. Each component requires individual optimization and monitoring, with integration points creating potential failure modes absent in unified architectures. Troubleshooting spans multiple processing engines and storage formats, substantially complicating operations.
Technical Risk Factors
Paimon's recent release creates uncertainty around production stability at hundred-billion-scale volumes. Throughput performance and scheduling reliability remain unproven at Rednote's scale, likely requiring extensive cross-component optimization. Additionally, introducing Paimon alongside existing Iceberg infrastructure adds storage format complexity, requiring parallel expertise in schema evolution, partition management, and performance tuning across multiple table formats.
The optimization requirements span Flink job configuration, Paimon compaction strategies, Iceberg partition schemes, and StarRocks cluster sizing—each affecting downstream performance in ways requiring holistic system understanding beyond individual technology expertise.
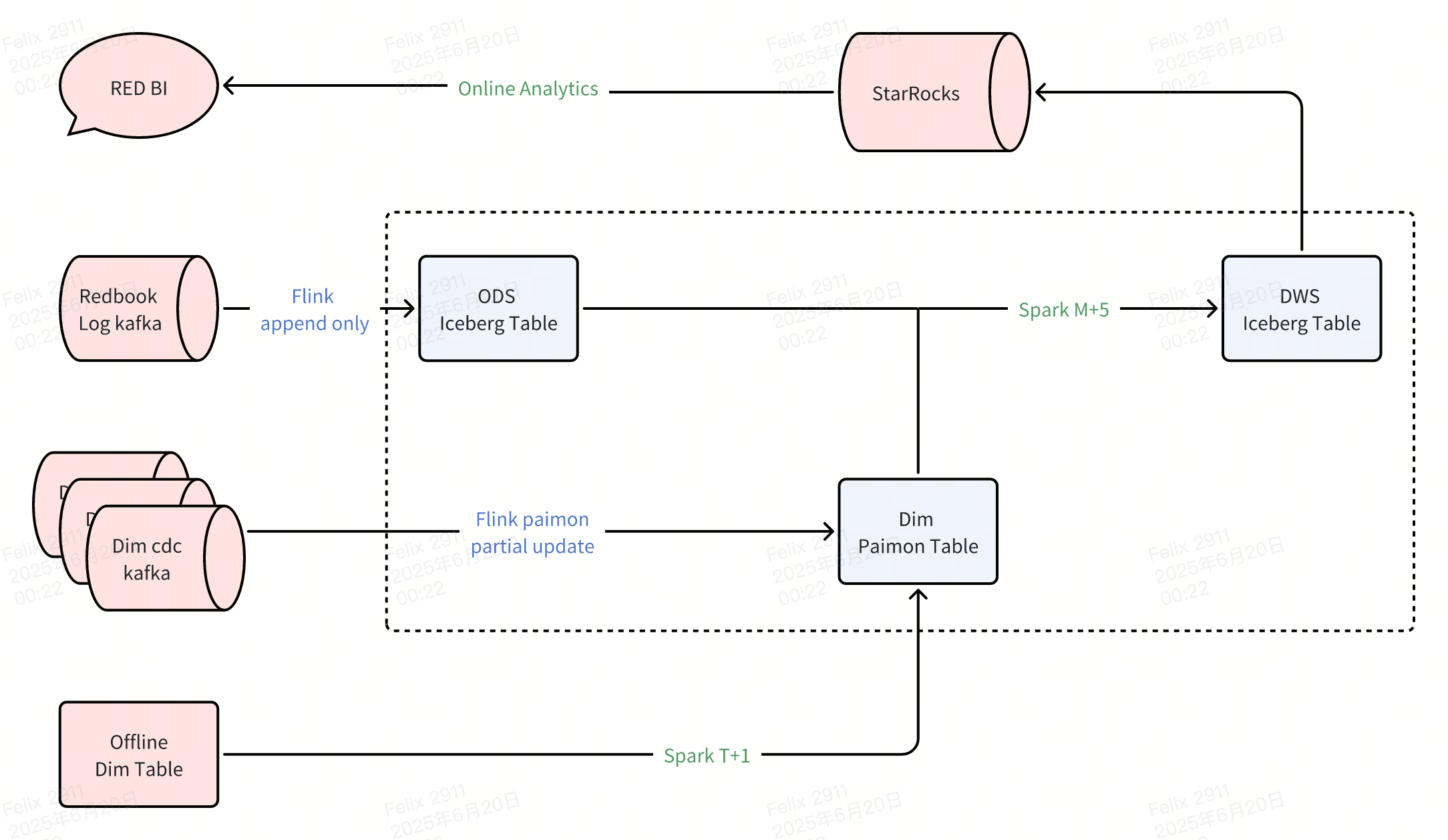
2.2 Commercial Solution: Singdata Generic Incremental Compute
Commercial vendors increasingly offer incremental compute capabilities, including Snowflake, Alibaba's MaxCompute, and Singdata's Lakehouse. Singdata provides the most open and versatile incremental compute platform suitable for our evaluation.
Generic Incremental Compute (GIC) implements dynamic data processing with incremental computation principles. This high-performance, low-latency compute paradigm processes only changed data portions, merging results with previous states to generate fresh query results efficiently.
Singdata pioneered universal incremental compute concepts since 2021, focusing on incremental compute and Kappa architecture. Their 2023 release introduced the GIC framework with production-ready capabilities.
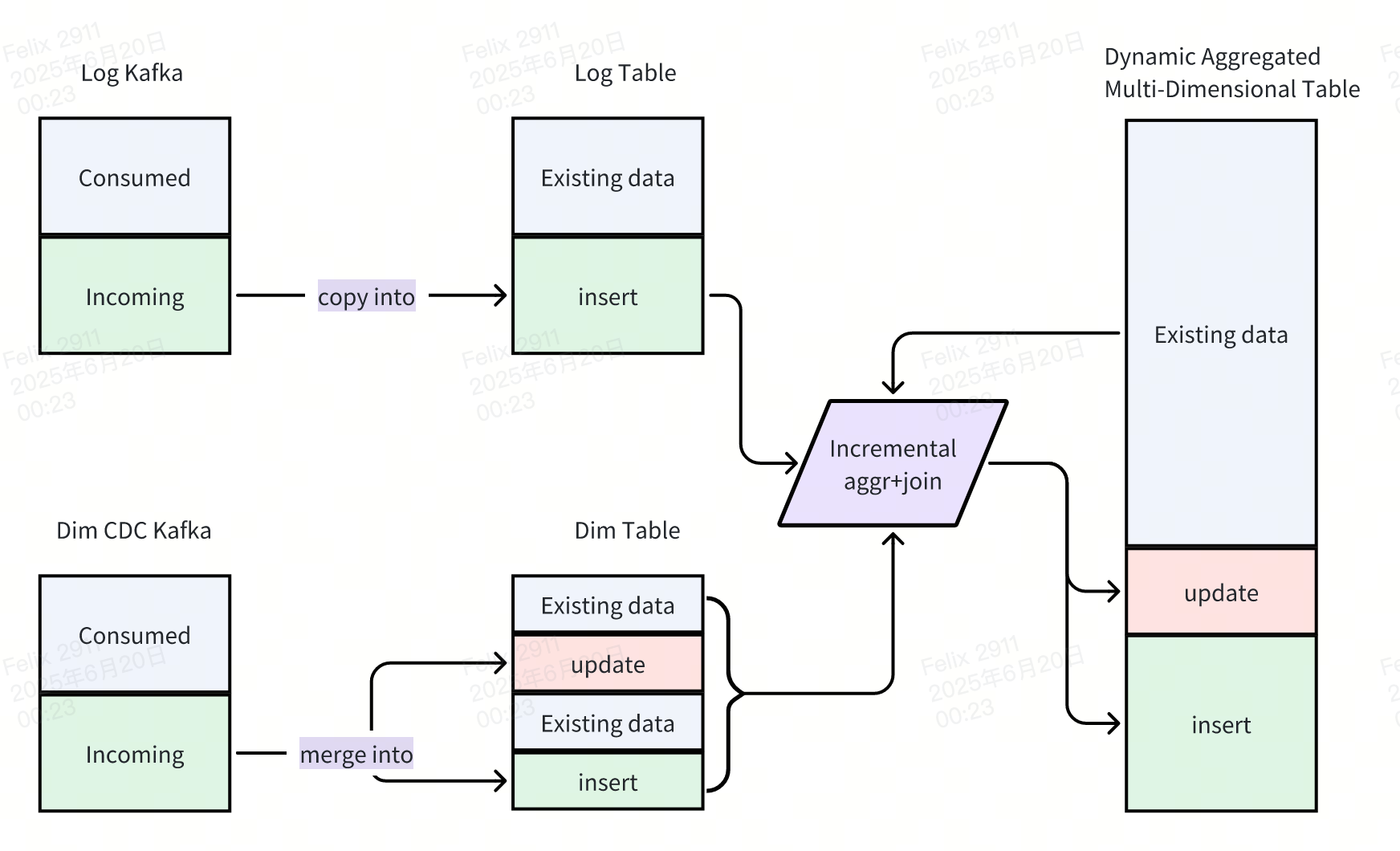
Unified Technology Stack: Singdata's integrated engine accelerates incremental compute to minute-level intervals while supporting efficient OLAP queries. Built-in Kafka connectivity enables unprecedented architectural simplification, supporting standardized SQL across real-time ETL, batch ETL, and interactive analytics.
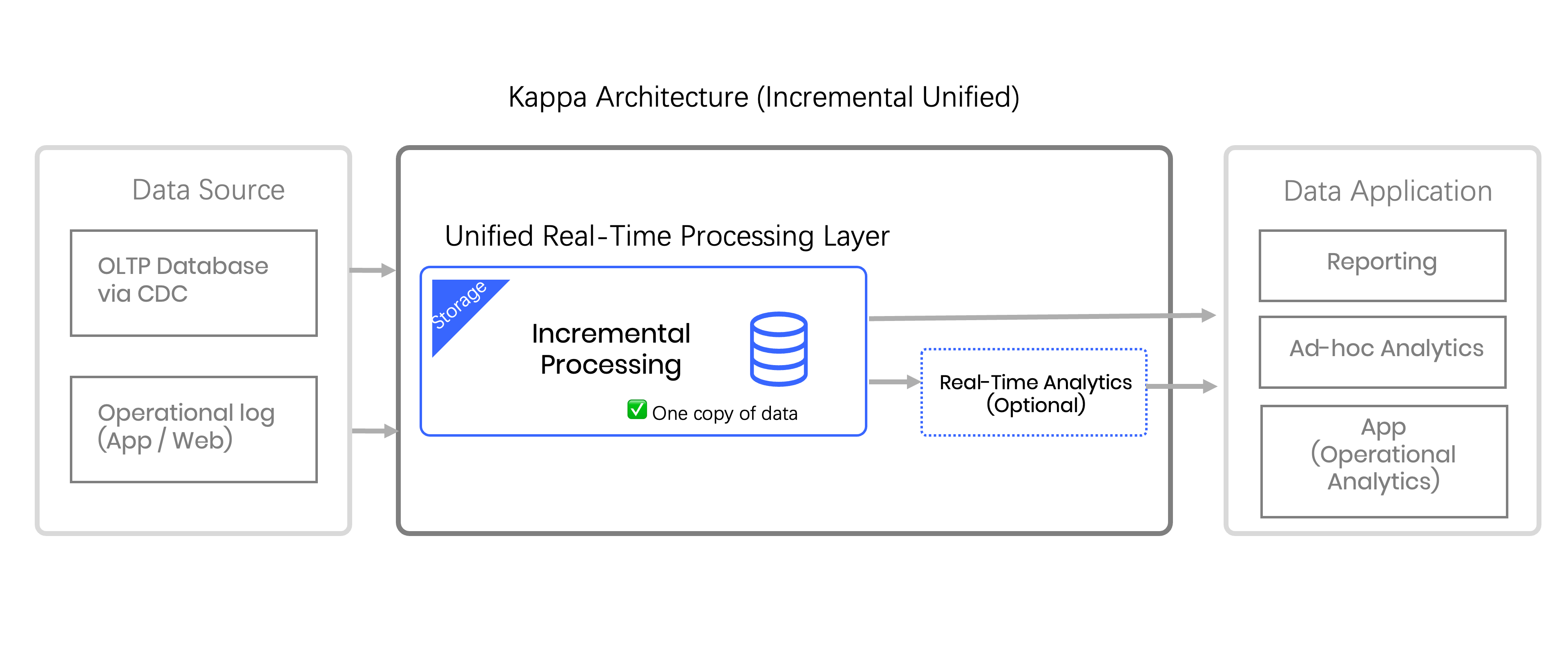
2.3 Open Format Foundation and Architectural Flexibility
Singdata's Lakehouse architecture fundamentally adheres to Iceberg standards for its underlying storage layer, enabling seamless integration with Rednote's existing object storage infrastructure. This design choice eliminates vendor lock-in concerns while leveraging our substantial investment in Iceberg-based data lake architecture.
The Iceberg compatibility allows incremental computing pipeline construction to directly replicate our proven offline ODS/DWD/DWS modeling patterns. Every layer within the incremental processing hierarchy remains fully queryable, enabling development teams to build new analytical branches using familiar offline development methodologies. This preserves institutional knowledge while extending capabilities into near real-time domains.
Singdata's incremental computing processes utilize standard table structures to represent intermediate computation states, unlike traditional streaming frameworks requiring specialized state management. This table-based approach enables expression of virtually unlimited window sizes without the cost explosion associated with streaming state persistence. Large temporal windows become economically feasible because state storage follows standard data lake cost models rather than premium in-memory pricing.
The dynamic tables maintain full compatibility with Iceberg's partition semantics, providing operational flexibility when business logic evolves. When dynamic table definitions require modification, partition-based boundaries enable precise control over affected data ranges. Historical partitions can undergo data supplementation, recalculation, or complete overwriting using familiar offline processing patterns without disrupting new data production.
The open format foundation: ensures all data produced through incremental computing remains accessible to existing analytical tools and frameworks across our ecosystem, while teams gain access to significantly fresher data through the near real-time pipeline.
Standard SQL Development: Core business logic uses standard SQL syntax with scheduled refresh operations. This approach enables direct reuse of offline ETL logic and Hive UDFs, significantly reducing development complexity compared to streaming frameworks.
-- Log table append-only real-time write scenario
create pipe pipe_ods_log_table -- Create pipe pipeline
as
copy into ods_log_table -- Write data using standard SQL insert into/overwrite
select ... from (
from READ_KAFKA(...)
);-- Dimension table primary key update real-time write scenario
create pipe pipe_ods_dim_table -- Create pipe pipeline
as
merge into ods_dim_table a using ( -- Write data using standard SQL merge into
select ... from READ_KAFKA(...)
) b on a.id = b.id
when matched then update set *
when not matched then insert *;Real-time/Batch Processing
-- DWS real-time computation/offline computation scenario
create dynamic table dt_dws_table
as select ...,demo_udf(...)
from ods_log_table a
left join ods_dim_table b -- Dimension table: user-experiment association table
on a.id = b.id2.4 Flexible Performance Tuning
Singdata's incremental computing framework provides dynamic configurability that enables precise optimization between real-time performance and computational cost efficiency. The system supports runtime adjustment of scheduling parameters and execution intervals, allowing teams to fine-tune processing characteristics based on evolving business requirements and operational constraints.
The fundamental advantage stems from Singdata's use of standard table structures for state storage, which dramatically reduces both storage and computational overhead compared to Flink's in-memory state management. This architectural choice means storage costs follow traditional data lake economics rather than premium streaming infrastructure pricing, while computational resources are allocated only during active processing windows. The result enables development teams to concentrate on business logic implementation rather than infrastructure optimization and cost management.
Workload-Specific Optimization Strategies
For high-throughput Kafka data processing pipelines where input and output volumes remain relatively balanced, scheduling intervals can be tightened to 1-minute cycles. This aggressive scheduling prevents data accumulation that could trigger massive short-term resource demands during processing windows. The frequent execution model works particularly well for streaming ingestion scenarios where consistent processing velocity is more important than computational efficiency.
Conversely, dimension table updates and compute-intensive dynamic table refresh operations benefit from relaxed 5-minute scheduling cycles. This extended interval effectively reduces small file proliferation caused by redundant updates to identical primary keys, while maximizing the computational efficiency of Singdata's vectorized execution engine. Longer processing windows enable better batch optimization and reduced coordination overhead across distributed processing nodes.
Runtime Adaptability
The scheduling configuration remains fully adjustable even after pipeline deployment and production operation. This post-deployment flexibility proves crucial for responding to changing data patterns, evolving business requirements, or shifting cost optimization priorities. Teams can experiment with different scheduling intervals to identify optimal performance characteristics without requiring code changes or pipeline redeployment, enabling continuous optimization based on operational experience and performance monitoring insights.
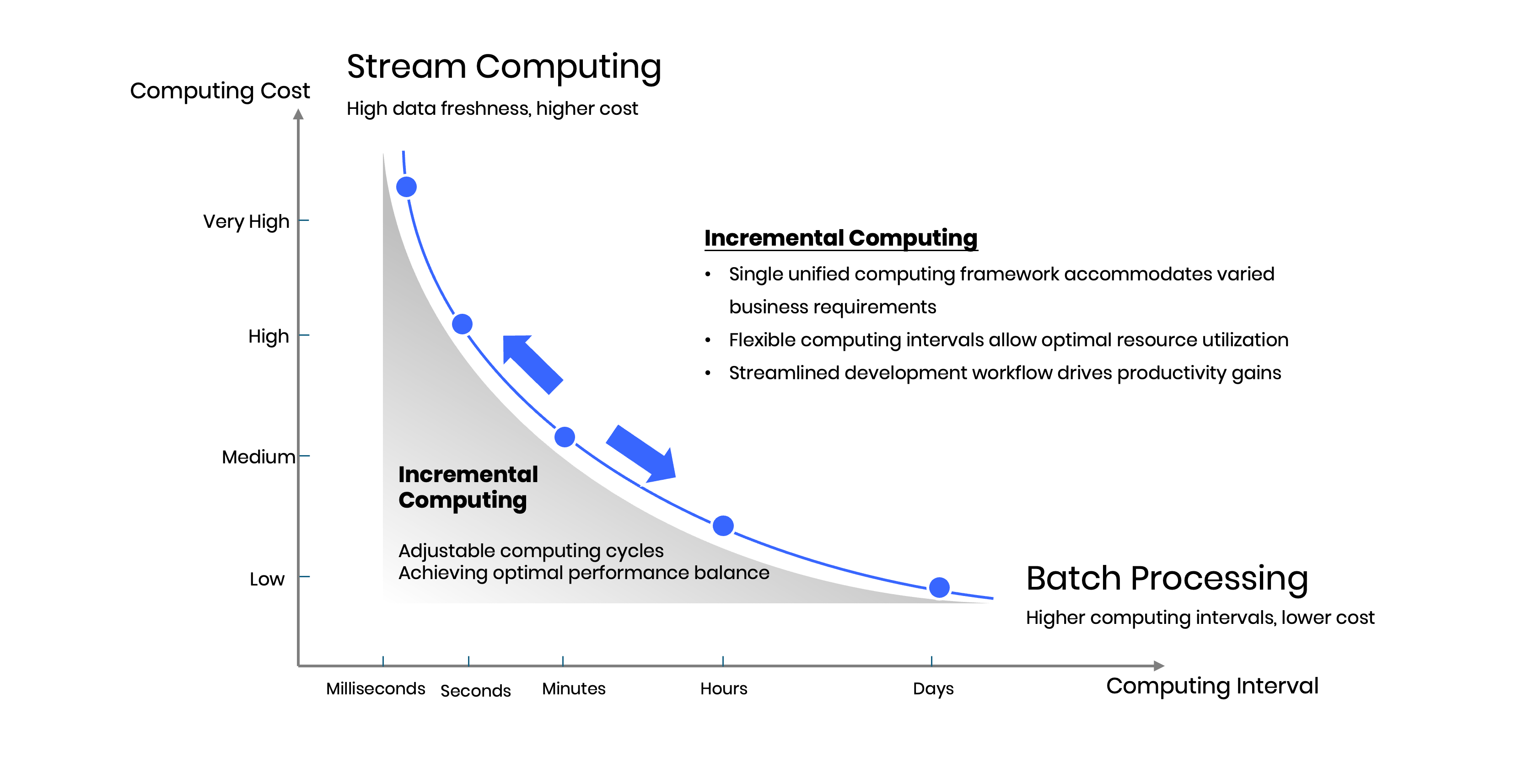
2.5 Decision Factors and Platform Selection
Our evaluation process considered multiple dimensions critical to Rednote's operational requirements and long-term architectural strategy.
Performance Characteristics: Singdata demonstrated superior performance across both batch scheduling efficiency and interactive query response times compared to open source combinations. The unified incremental computing engine achieved faster processing speeds with lower resource consumption than equivalent Flink + Paimon configurations, while delivering sub-second query performance against hundred-billion-record datasets without requiring separate query engine deployment.
Late Data Handling and Incremental Backfill: Singdata provides comprehensive support for late-arriving data through automatic partition-level reprocessing capabilities. When upstream systems experience delays or require historical corrections, the platform intelligently identifies affected partitions and triggers selective recomputation without impacting concurrent processing. This granular approach maintains operational continuity while ensuring data consistency, unlike traditional streaming systems requiring full pipeline restarts.
Storage Architecture Compatibility: Singdata's native Iceberg integration provides seamless compatibility with Rednote's existing data lake infrastructure, eliminating operational complexity of introducing additional storage formats. This preserves our investment in Iceberg-based tooling and operational procedures while extending capabilities into near real-time domains, whereas open source approaches would require managing parallel expertise across multiple table formats.
Based on these evaluation criteria, we selected Singdata as our near real-time incremental computing platform, positioning our architecture for scalable growth while minimizing operational complexity.
3. Data Model Architecture
3.1 Design Principles
Rednote's business operations generate hundreds of billions of log records daily. Processing this volume through traditional detailed aggregation approaches—directly computing metrics from raw transaction data while performing experiment filtering, user dimension associations, and other complex operations—would create unsustainable resource demands when targeting sub-second query performance.
The traditional methodology would trigger exponential resource scaling, dramatically increasing computational costs and making it difficult to achieve acceptable return on investment for near real-time analytics capabilities. Direct aggregation from detailed layers while simultaneously joining with dimension tables would require infrastructure investments exceeding the business value derived from near real-time insights.
To address these scalability and cost efficiency challenges, we implemented several strategic optimizations within our near real-time pipeline's data modeling approach. Our model design optimizes resource utilization while meeting performance expectations, ensuring target query performance characteristics remain within economically viable operational boundaries.
3.2 Data Modeling Architecture Optimizations
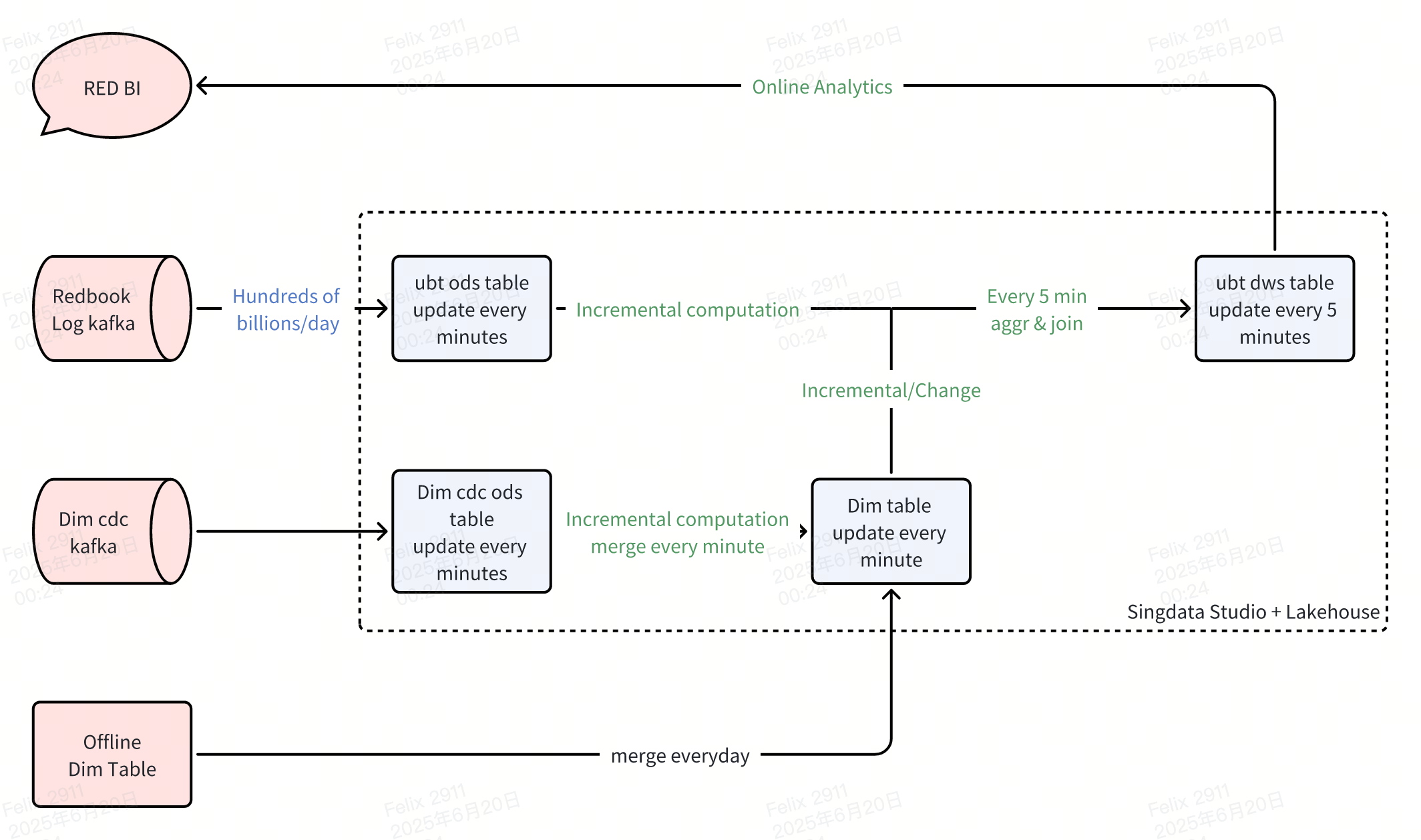
3.2.1 Minute-Level Aggregated DWS Layer
For Rednote's hundreds of billions of daily logs, direct querying demands extremely high performance requirements. Daily query metrics typically filter by user experiment information and user dimensional data, with real-time metric time dimensions usually spanning 5 minutes, 10 minutes, or 30 minutes. Therefore, we designed data at <minute, user_id> granularity in our model architecture, solidifying user and time dimensions while treating others as basic aggregation metrics.
Through 5-minute scheduled tasks, we transform detailed logs into 5-minute + user granularity DWS layer data. During minute-level scheduling, we associate user dimension tables, placing relevant dimensional information and corresponding user experiment data into the DWS aggregation layer. Overall data volume reduces from hundreds of billions to hundreds of millions. Since users may belong to multiple experiments, we store experiment fields as arrays for query-time filtering, ultimately optimizing P90 query performance to under 10 seconds.
3.2.2 Real-time User Dimension DIM Layer
Real-time user dimension tables divide into real-time and offline dimensions through partial update methodology. For dimensions requiring real-time updates, we read user real-time Kafka data streams, performing 1-minute scheduled updates on user dimension table data to achieve real-time refresh effects. For daily-updated dimensions, we use offline scheduled writes, identifying records requiring updates through table timestamp evaluation to implement on-demand updates.
3.2.3 Experiment Array Query Optimization
Algorithm platforms involve numerous metrics (reaching thousands) that gradually change over time. Traditional modeling approaches require separate columns for all metrics, constructing thousand-column wide tables. Every metric addition or removal involves schema evolution for these wide tables, requiring upstream and downstream ETL pipeline table structure corrections and corresponding job updates - an extremely burdensome process.
Therefore, we leverage Singdata's JSON type support, expressing variable algorithm metrics as JSON columns. Utilizing semi-structured expression capabilities and rich built-in JSON functions, algorithm users can independently add or remove metrics within JSON columns, significantly improving platform efficiency.
Singdata's Lakehouse engine supports file-level automated type inference technology, storing semi-structured JSON data in multi-column format within Parquet files. This approach means JSON column semi-structured tables compared to traditional wide tables only consume additional CPU for type inference during table creation, with virtually no difference in storage space consumption or subsequent query performance.
3.2.4 User Experiment Dimension Table Design
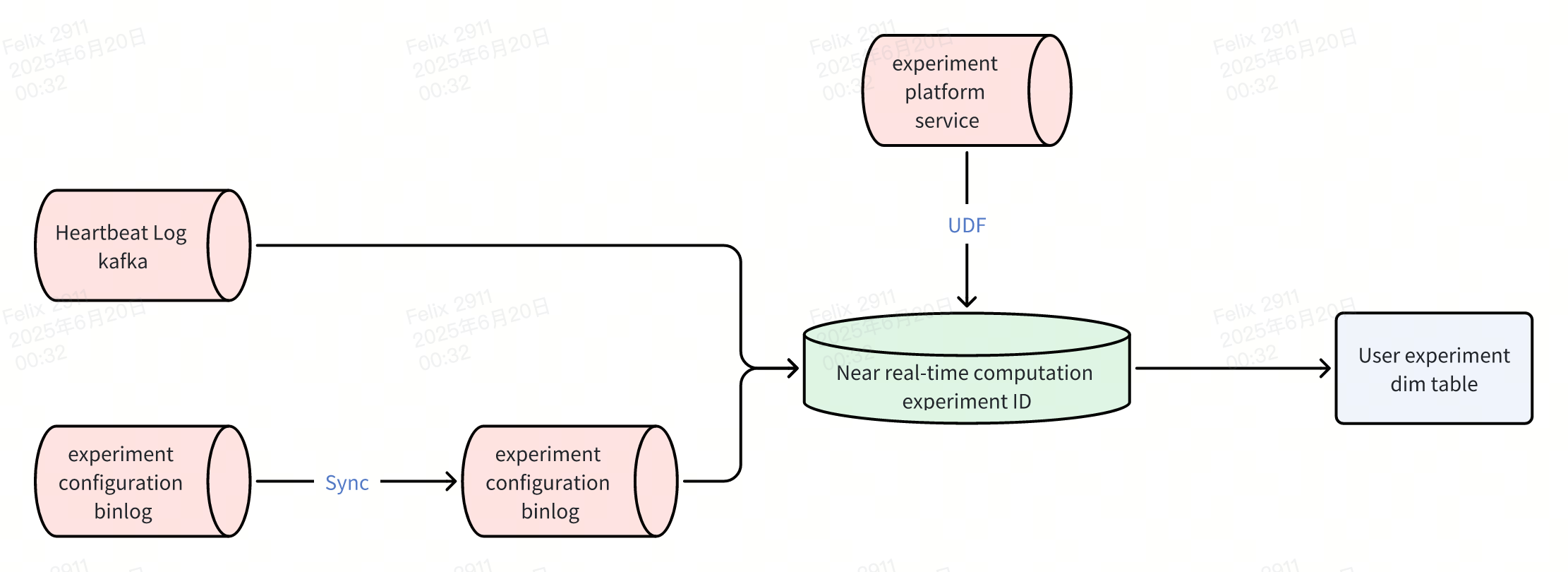
Thousands of experiments run daily on our experiment platform. Offline processing designs user ID to experiment group ID mapping tables when computing user experiment assignments, but these tables contain hundreds of billions of daily records. Real-time or near real-time scenarios cannot generate such massive mapping relationships within short timeframes.
Rednote's previous real-time experiment scenarios used whitelist approaches to limit experiment scope, filtering only experiments modified within the past day to reduce user experiment mapping relationships. User behavior logs retrieved corresponding experiments from experiment platform services, recording them in KV storage for real-time jobs to obtain user experiment group IDs. While this approach addressed basic real-time experiment viewing requirements, many experiments cannot determine effectiveness based solely on single-day metrics.
Our near real-time pipeline aims to support nearly 7-day experiments with execution times within 5 minutes. Following offline approaches, any engine processing such massive data volumes cannot avoid excessive execution times. Adopting real-time pipeline thinking would create substantial KV storage pressure and read/write bottlenecks.
After thoroughly understanding experiment grouping processes, we discovered that once experiments are configured, the platform combines user IDs with experiment configuration information for computation, ultimately determining which experiment group users belong to (or excluding them from experiments). We decided to use real-time computation to calculate experiment group IDs.
Computing user experiment groups requires only two pieces of information: user ID and experiment configuration information, with only experiment configuration changing in real-time. Therefore, we encapsulated experiment ID calculation processes within UDFs, using heartbeat logs to compute current user experiment group IDs. Calculated experiment group information stores in Singdata's user experiment dimension tables, enabling various near real-time business applications without repeated computation.
User experiment dimension tables follow <user_id, exp_ids> format, where exp_ids uses array<bigint> data structure. Traditional query methods necessarily traverse each data record. Since users can have hundreds of experiment group IDs, this query approach proves extremely inefficient. Singdata enables inverted index creation on exp_ids, improving query performance nearly 20-fold compared to original query methods after adding inverted indexes to user experiment dimension tables.
4. Performance Results
4.1 Real-time Experiment Data Pipeline Solution Comparison
Comparing offline, near real-time, and real-time approaches across latency and experiment coverage dimensions:
Comparison Dimension | Offline Pipeline | Real-time Pipeline | Near Real-time Pipeline |
Data Timeliness | T+1 day | 10-second latency | 5-minute latency |
Observable Experiments | All currently active experiments (~2,000) | Allowlisted experiments (~100) | Experiments modified within last 7 days (~300) |
New Metric Development Complexity | Simple | Complex | Simple |
Resource Scheduling Mode | Scheduled | Resident | Scheduled |
We conducted comprehensive comparisons across offline pipelines, near real-time pipelines, and real-time pipelines focusing on timeliness and experiment observability capabilities. The following conclusions emerged from this analysis:
Timeliness and Performance Balance: Our current business scenarios demonstrate that 5-minute near real-time solutions completely satisfy experiment observation effectiveness requirements. Compared to offline daily-level data processing, near real-time data provides excellent support for algorithm real-time parameter tuning while avoiding the complexity of real-time data development and excessive resource consumption challenges. Additionally, the near real-time approach offers flexible adjustment capabilities for data latency (data freshness) based on evolving business requirements, enabling dynamic optimization of data update frequencies to achieve optimal balance between business needs and operational costs.
Experiment Observability Coverage: Near real-time solutions achieve excellent balance in observable experiment numbers, positioning between offline and real-time approaches. In actual production environments, users primarily focus on data patterns during the initial days following experiment launch or traffic scaling, enabling timely strategic adjustments. Near real-time solutions effectively address these critical observability requirements without the operational overhead of full real-time processing.
Overall Solution Assessment: Comparing across all three approaches, near real-time solutions emerge as the superior option when evaluated against business timeliness requirements, experiment observation needs, and metric development complexity dimensions. This approach delivers better overall value compared to both real-time and offline alternatives, providing the optimal combination of performance, cost efficiency, and operational simplicity for our experiment analytics infrastructure.
4.2 Business Value Enhancement
Rednote leveraged Singdata's incremental computing capabilities and Iceberg data lake's open storage architecture to construct a new experiment metrics algorithm pipeline. We completed integration with the RedBI platform, providing fully compatible query capabilities with historical products while achieving substantial performance optimization compared to original pipelines.
The diagram primarily compares resource consumption, accuracy, and latency between near real-time and real-time pipelines, yielding the following comparative conclusions:
Comparison Dimension | Singdata x Rednote Incremental Solution | Rednote Current Real-time Pipeline |
Business Scenario | Analysis pipeline for Rednote app comprehensive behavioral logs (hundreds of billions daily) + hundreds of millions of daily dimension table updates | |
Architecture Selection | Singdata Studio + Lakehouse Integrated Engine | Flink + ClickHouse |
Resource Investment | 1,800 cores for near real-time pipeline | 5,000 cores for real-time pipeline |
Data Latency | 5 minutes | 10 seconds |
Data Accuracy | Consistent with offline data (average difference <1%) | Partial variance from offline data (difference <5%) |
Metric Dimensions | Freely extensible to hundreds of metrics | Limited to core metrics only |
Online Analysis Performance | P90 < 10 seconds | P90 < 10 seconds |
Offline Data Reusability | Yes | No |
Pipeline Complexity | Simple, unified integrated engine | Complex, multiple solution integration |
Migration Cost | Low, reusable standard SQL | High, different engines require different semantic expressions |
Resource Efficiency and Accuracy Improvements: Compared to historical real-time solutions, the new approach consumes only 36% of original resource investment while delivering superior data accuracy with variance reduced from 5% to 1%. Additionally, the incremental solution's metrics demonstrate stronger extensibility through incremental update capabilities, enabling data reuse for offline processing scenarios.
Development Agility and Schema Flexibility: Traditional real-time data scenarios required modifying existing table structures when adding new fields, involving DDL modifications, task restart submissions, and secondary development for new field writes—an extremely lengthy and complex development iteration process. Currently, leveraging Singdata's comprehensive JSON type support and high-performance JSON query capabilities, Rednote dumps all tracking feature-related fields into JSON format. This enables BI users to independently configure new tracking fields directly within datasets without submitting field addition requests. Self-service tracking field updates rapidly and flexibly satisfy algorithm debugging and parameter tuning requirements.
Enhanced Dimensional Analysis Capabilities: Based on the incremental computing engine, Singdata Lakehouse provides significantly more experiment dimensional extension data compared to original real-time pipelines while achieving superior performance compared to original offline pipelines. Through near real-time dimensional extension implementation, BI users can conduct more comprehensive multi-dimensional behavioral analysis, demonstrating that near real-time solutions outperform real-time approaches in current operational scenarios.
Future Outlook
The near real-time infrastructure we've built with Singdata represents a fundamental shift in how Rednote approaches data processing. By establishing this capability on open Iceberg formats, we've created a foundation that naturally extends beyond our initial experiment analytics use case.
The minute-level data freshness we now achieve opens new possibilities for migrating offline ETL workloads. Many processes that previously required overnight batch windows can now operate continuously with acceptable latency. The incremental computing capabilities that power this transformation enable selective processing of only changed data, making frequent updates economically viable at scale.
What excites us most is near real-time processing's role as a unifying layer between traditionally separate real-time and batch paradigms. This convergence eliminates consistency challenges that have historically plagued mixed-mode analytics architectures. Teams no longer need to choose between speed and accuracy—they can achieve both through intelligent incremental updates.
Our next phase involves expanding this approach across Rednote's core observational metrics. Rather than maintaining separate real-time and offline metric systems, we're building toward a unified near real-time metrics framework that serves all consumption patterns from a single source of truth. The incremental computing foundation makes this feasible by enabling complex transformations at costs previously associated only with batch processing.
As more teams experience the operational benefits—simplified development, reduced resource costs, and improved data consistency—we expect near real-time processing to become the default choice for new analytical initiatives. We're witnessing the early stages of a broader industry evolution toward near real-time as the optimal balance point for most analytical workloads, and Rednote is well-positioned to lead this transformation.
Experience the platform: www.singdata.com
