Using Lakehouse Compute Cluster
1. Overview: Why do we need a "Compute Cluster"?
In Singdata Lakehouse, whether executing offline/real-time data integration, performing complex ETL tasks, or conducting real-time/offline interactive queries, it is necessary to use the compute cluster (Virtual Cluster, abbreviated as Vcluster) provided by Lakehouse. The compute cluster supports:
- On-demand start and stop: Automatically stops when there are no queries or jobs, avoiding cost wastage due to idle resources; automatically starts when new jobs or queries arrive, ensuring timely processing.
- Flexible specification selection: Quickly "vertically scale" or "horizontally expand" based on job load and concurrency.
- Multiple usage methods: Cluster creation, start, stop, resizing, and permission management can be done through the web interface or SQL DDL commands.
This document will combine the features and operation methods of Lakehouse Compute Cluster (Virtual Cluster, abbreviated as Vcluster) with practical application scenarios to provide some application examples and best practices.
2. Core Concepts and Main Functions
1. Cluster Name
Each Singdata compute cluster has a unique name that cannot be duplicated within its workspace. Once a compute cluster is created, its name cannot be changed.
2. Specifications
In Lakehouse, specifications are measured in "CRU (Compute Resource Unit)", such as (1CRU, 2CRU, 4CRU... up to 256CRU). Depending on the needs, you can choose General Purpose/Analytics Purpose/Integration Purpose clusters and configure the corresponding cluster size.
Note: Larger cluster specifications mean higher load capacity and query performance, but also higher costs. You can adjust and optimize cluster specifications during use based on business load and cost expectations.
3. Cluster Types
Lakehouse compute clusters are divided into General Purpose (GP), Analytics Purpose (AP), and Integration Purpose (Integration).
- General Purpose (GP): Suitable for offline jobs or comprehensive scenarios, where job resources in the same compute cluster are shared and fairly scheduled. The specification size can automatically scale up and down (vertical scaling).
- Analytics Purpose (AP): Suitable for ad-hoc and high-concurrency online job scenarios, where jobs in the same compute cluster exclusively occupy resources and are queued for execution based on job order. The number of replicas can automatically scale up and down based on concurrent load (horizontal scaling).
- Integration Purpose (Integration): Suitable for real-time/offline data integration and other synchronization tasks, where multiple integration tasks can share one instance, and the specification size can automatically scale up and down based on load (vertical scaling).
4. Auto Start & Auto Stop
Auto Start: When a new job or query is submitted, if the cluster is in a "suspended" state, it will automatically start to execute the task.
Auto Stop: After a period of no job/query tasks, the cluster will automatically stop and release compute resources, no longer incurring charges.
5. Multi-instance Scaling
The analytics compute cluster in Lakehouse can set "minimum instances" and "maximum instances". When concurrent requests are high, instances are automatically added, and when concurrent requests decrease, instances are automatically reclaimed, meeting query business needs while saving resource costs.
6. Billing Method
Billing is based on the actual running time of the compute cluster, accurate to the second, with a minimum billing cycle of 1 minute. By reasonably setting compute cluster specifications and strategies such as auto stop and auto start, compute costs can be effectively saved.
3. Common Usage Scenarios and Examples
Scenario 1: Offline ETL Job Load
Requirement: Perform data cleaning/transformation every day or every hour, with large data volumes, taking tens of minutes to several hours, but do not want to incur compute cluster costs during idle periods. Solution:
- Create a General Purpose Compute Cluster
In the workspace where ETL jobs need to be executed, create a General Purpose compute cluster. Configure the cluster size based on data volume and job completion expectations. You can refer to the table in Compute Cluster for estimation and configuration:
| Business Scenario | Load Type | Execution Frequency | Job Concurrency | Data Volume | VCluster Type | Job Latency SLA | VCluster Specification |
|---|---|---|---|---|---|---|---|
| ETL Scheduling Jobs | Near real-time offline processing | Hourly | 1 | 1 TB | General Purpose | 15 Min | 4 |
| T+1 Offline Processing | Days | 1 | 10 TB | General Purpose | 4 Hours | 8 | |
| Tableau/FineBI | Ad-Hoc Analytics | Ad-Hoc | 8 | 1 TB | General Purpose | <1 Min TP90 <5s | 16 |
| Data Application Products | Applications | On demand | 8 | 100 GB | Analytical | <3 seconds | 4 |
| On demand | 96 | 100 MB | Analytical | <3 seconds | 4 | ||
| ClickZetta Web-UI | Ad-Hoc Analytics | Ad-Hoc | 8 | 3 TB | General Purpose | < 1 Min TP90 <15 s | 16 |
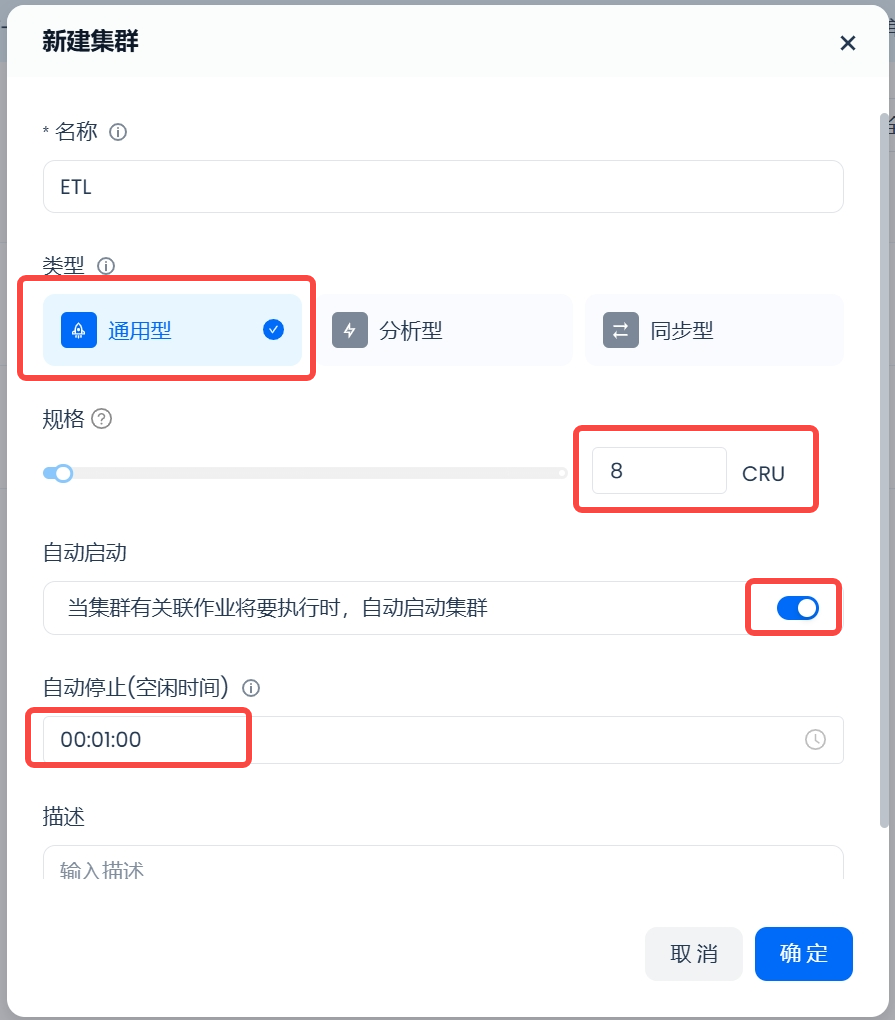
Assume the data to be processed is 10TB, and it is expected to be completed within 4 hours. Therefore, a general-purpose computing cluster with a specification of 8 CRU needs to be created.
-
Set the automatic stop time to 1 minute to ensure resources are released promptly after the job ends.
-
Enable the "Auto Start" configuration so that the computing cluster can be automatically started whenever the ETL scheduling task is initiated.
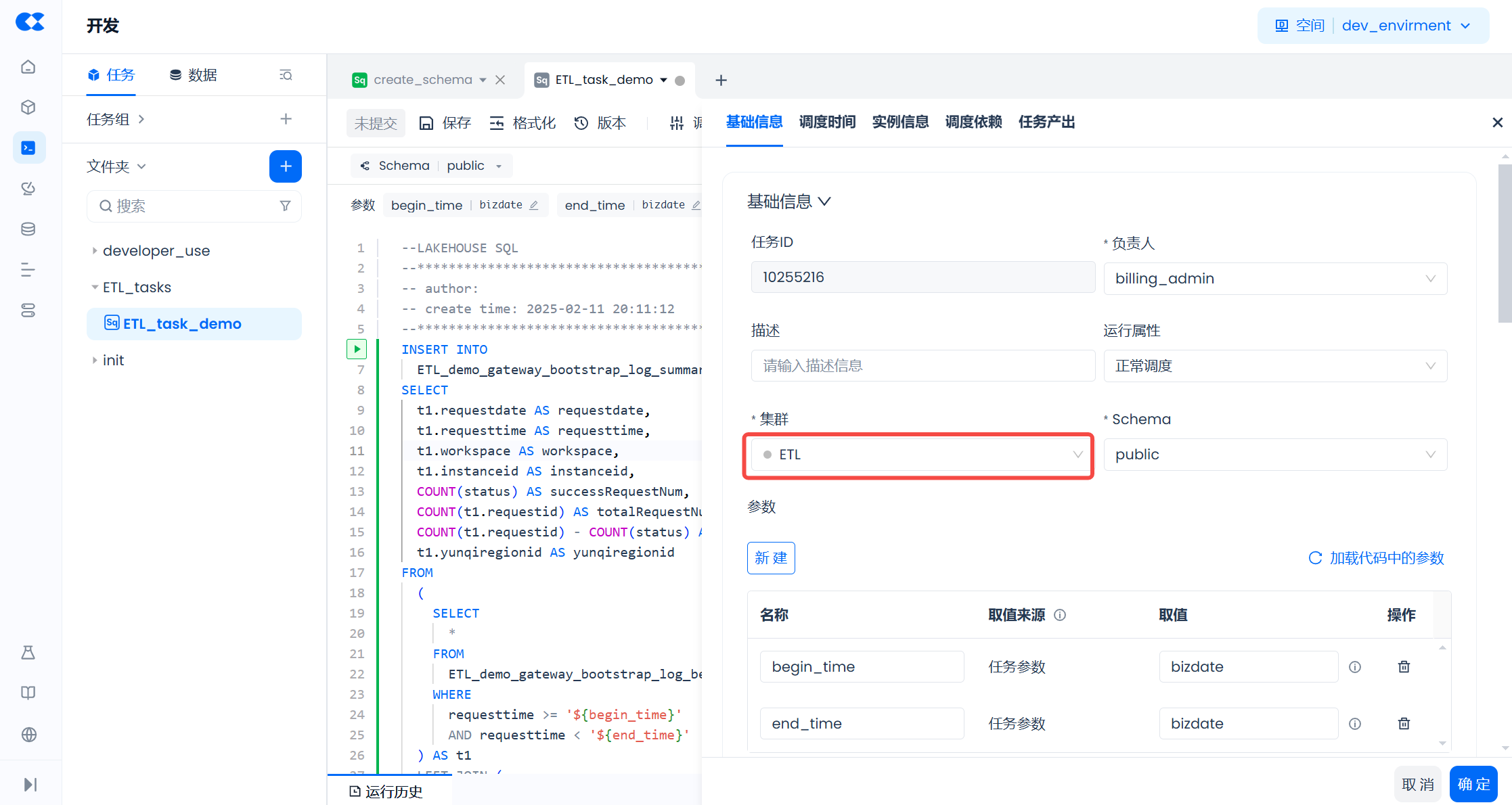
- In the scheduling configuration of the ETL task (ETL_task_demo), configure the computing cluster for task execution to the ETL cluster set in the previous step. For more scheduling configuration operations, refer to the relevant content in the Task Development and Scheduling document.
Effect:
-
When the ETL task (ETL_task_demo) starts executing, the general-purpose computing cluster ETL will automatically start.
-
After the ETL task (ETL_task_demo) finishes executing, the general-purpose computing cluster ETL will automatically shut down after being idle for 1 minute.
Scenario 2: Online Reports + Real-time Queries
Requirement: During working hours, multiple business personnel/analysts simultaneously start business queries through the APP or BI, requiring low latency for query results and short waiting queues. To improve resource utilization efficiency, it is hoped that the resource consumption of the computing cluster can dynamically scale with the usage scale of the business personnel, and the cluster can automatically shut down when there is no business, saving costs. Solution:
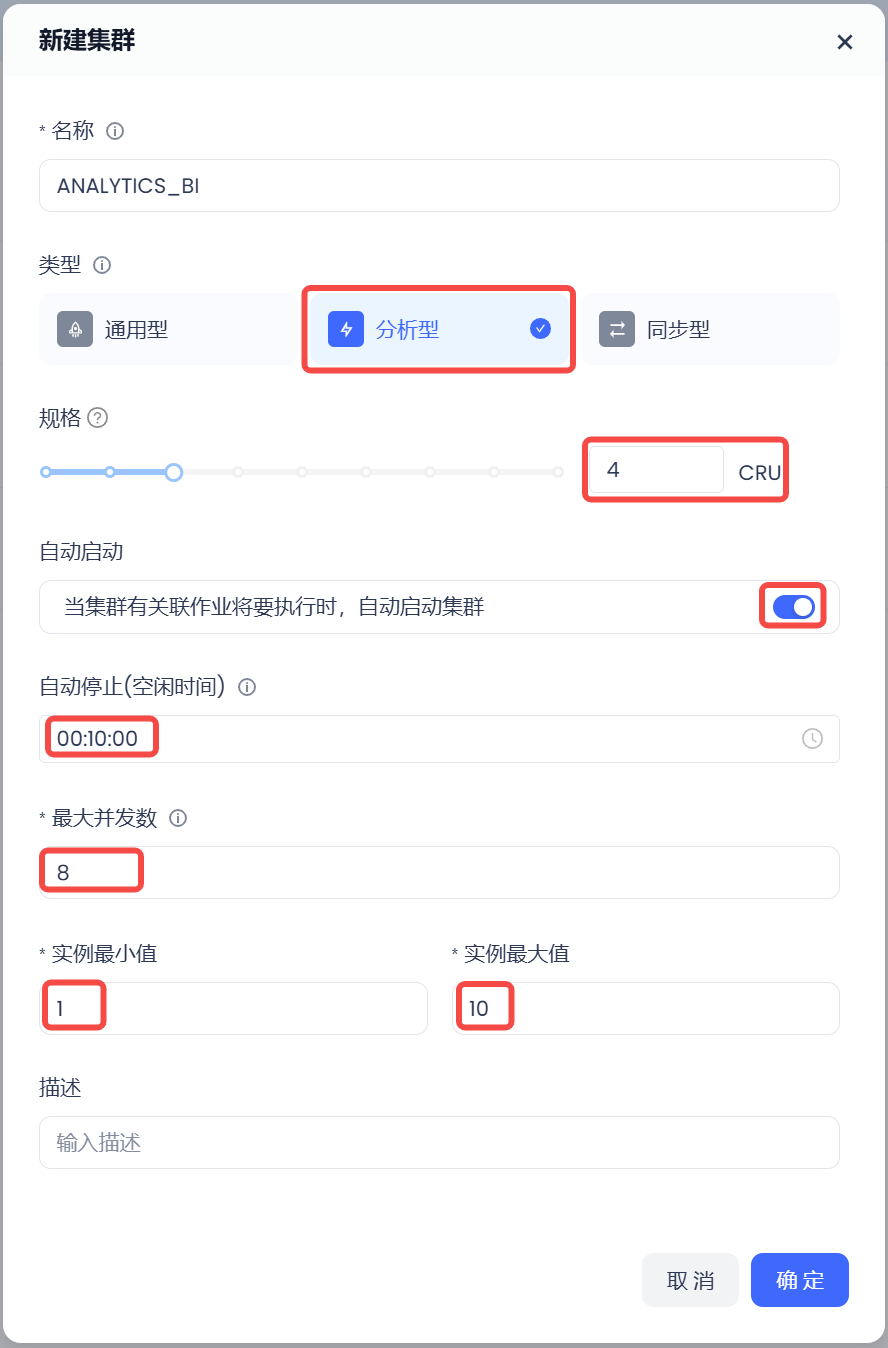
- Create an analytical computing cluster and set:
Instance specification to 4 CRU;
Minimum instance value to 1, maximum value to 10;
Maximum concurrency per instance to 8;
Enable Auto Start;
Automatic stop time to 10 minutes.
This way, complex queries with an expected data volume of 100GiB can return query results within 3 seconds. When the computing cluster is running, it can support 8 concurrent queries at the minimum scale and up to 80 concurrent queries at the maximum scale. When the concurrency exceeds 80, new concurrent requests will start queuing. After being idle for more than 10 minutes, the computing cluster will automatically shut down, stopping the computation cost. Extending the shutdown time to 10 minutes instead of 1 minute can minimize the impact of frequent restarts on the query experience and retain the cache for faster response to subsequent queries, balancing cost and query performance.
- When executing query jobs in the APP or BI linked to Lakehouse, configure the use of the ANALYTICS_BI computing cluster to execute query tasks. For example, the connection string for JDBC is as follows:
以virtualCluster=ANALYTICS_BI参数指定执行查询任务的计算集群为ANALYTICS_BI。
Effect:
High real-time query processing efficiency, automatically scaling new instances when user query volume surges to avoid queuing. Ensures good performance under high concurrency. Scales down when idle to save costs.
Scenario 3: Temporary Analysis/Data Exploration
Requirement: Data scientists perform exploratory analysis on large-scale data, including repeated multi-table joins and advanced aggregations. Need to quickly return query results for complex queries. Solution:
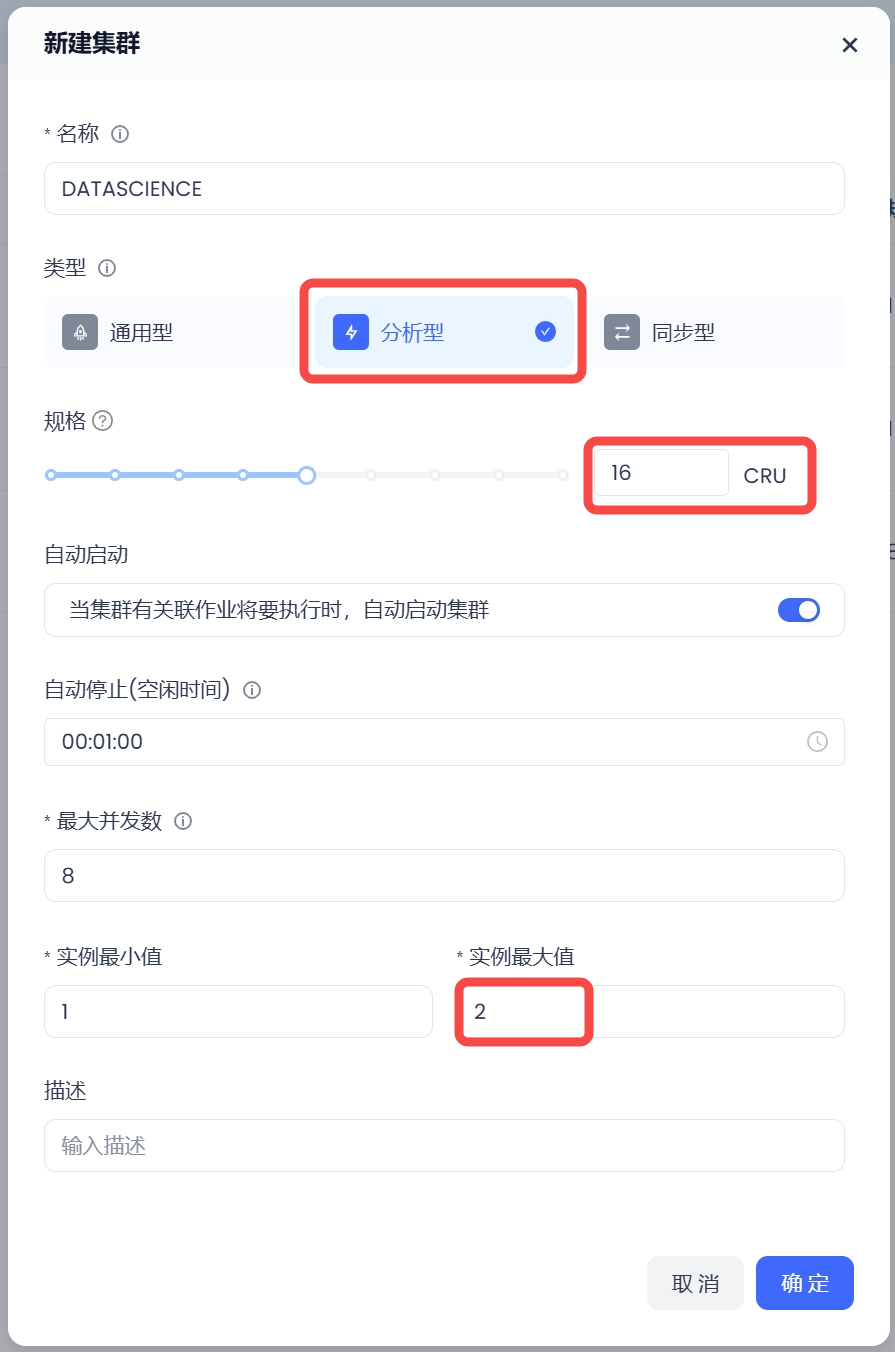
1. Create a large-scale analytical computing cluster, such as 16CRU, to enhance computing parallelism and shorten query time. Minimum instance count is 1, maximum instance count is 2, to control costs.
2. During the analysis phase, disable auto-stop or set the auto-stop time to more than 30 minutes to retain cache, significantly improving speed during repeated queries.
3. Manually stop or reset the auto-pause duration to 1 minute after the analysis is complete to save costs.
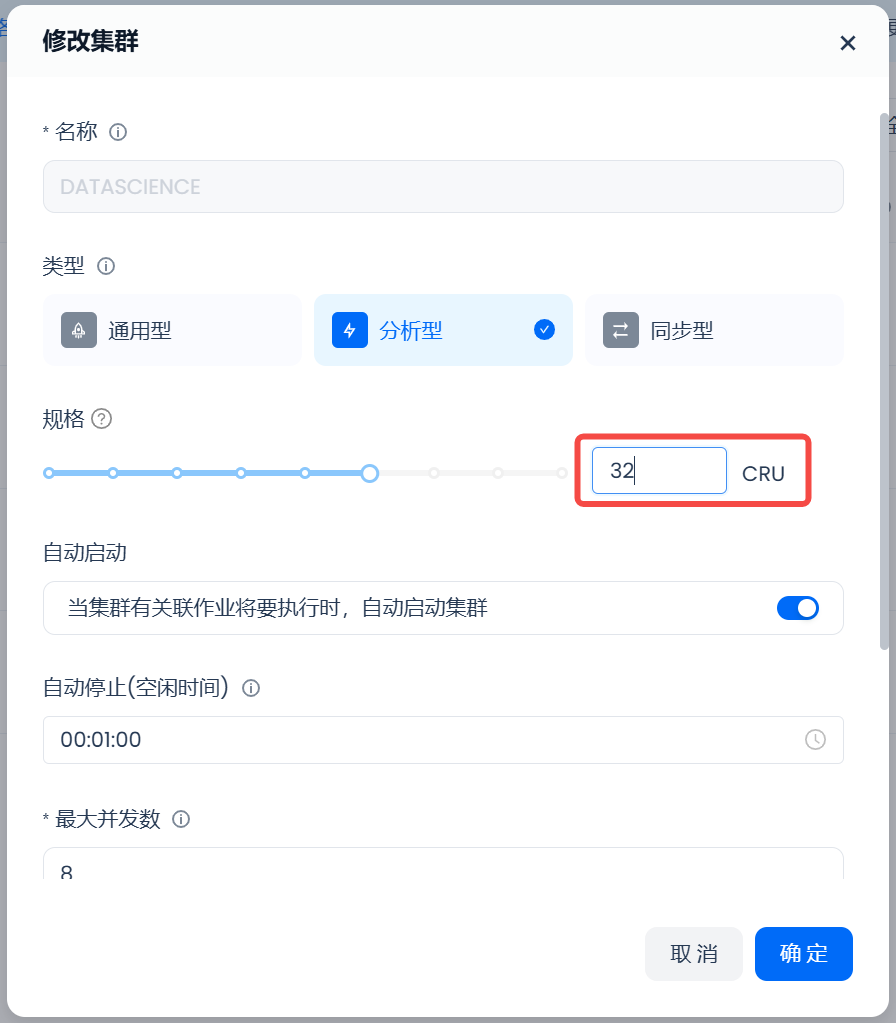
4. If performance is found to be insufficient during use, you can "manually adjust" the computing specifications at any time to achieve better query performance.
Effect:
- Large-scale analytical computing clusters process large volumes of complex SQL faster, shortening the analysis cycle.
- No need to always occupy large-scale resources, you can manually adjust cluster specifications and auto-start/stop times at any time without affecting ongoing analysis tasks.
Scenario 4: Multi-task Isolation
:-: Requirement: Within the same department, there are periodic ELT tasks, Ad-Hoc analysis, and online report requests. Resources should not compete with each other, and resources should not be wasted.
Solution:
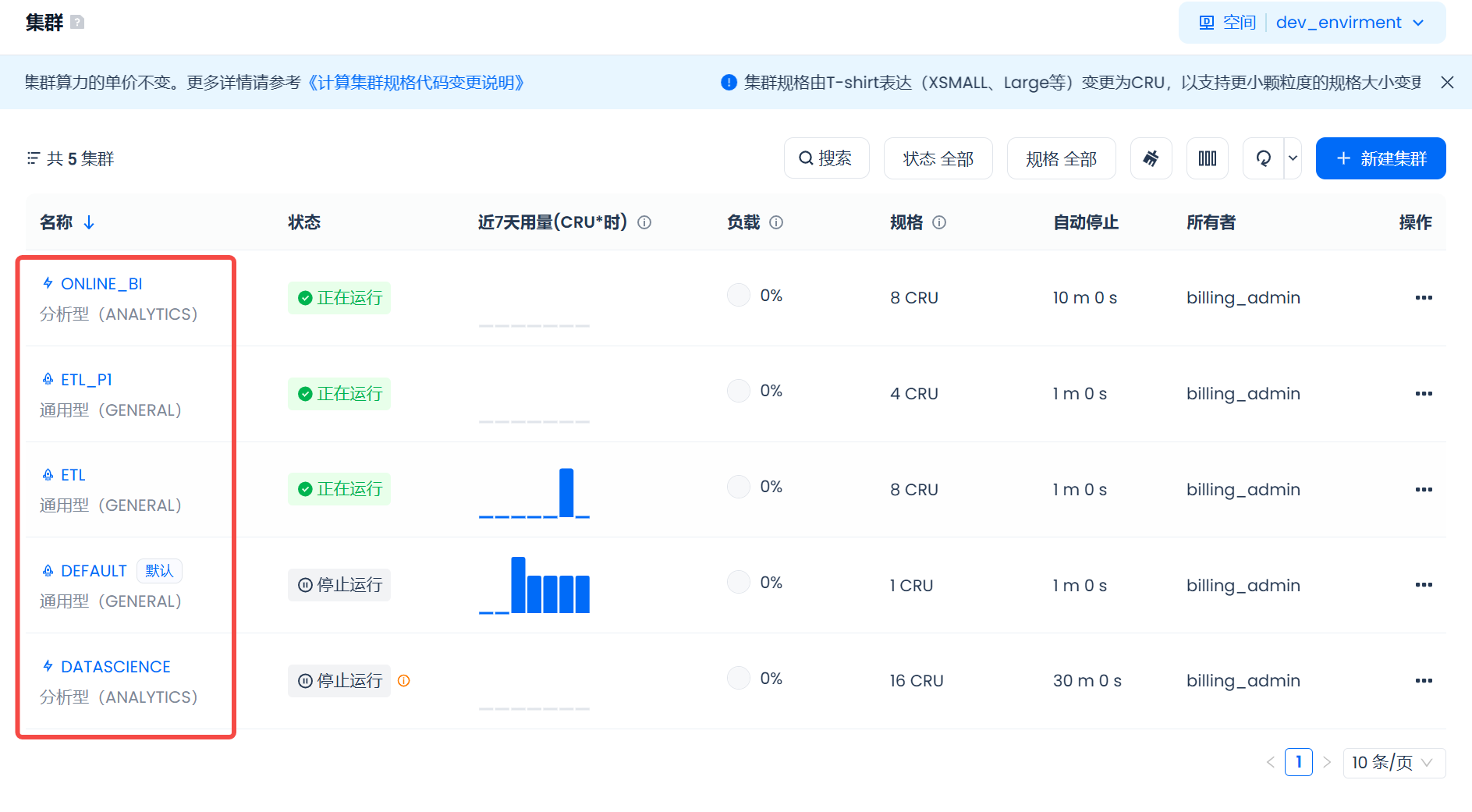
- Create multiple clusters:
- ETL dedicated cluster: Use a general-purpose computing cluster, configure specifications that meet job SLA expectations based on business needs, and set a short auto-pause time to promptly shut down the cluster after job completion to reduce costs. Multiple ETL dedicated clusters can be created to assign ETL tasks with different SLA requirements to different clusters, avoiding resource competition within the same cluster that could affect important task SLAs.
- Online report cluster: Use an analytical computing cluster, enable multi-instance mode, allowing the computing cluster to automatically scale up or down with the number of concurrent users, and appropriately extend the auto-stop time to utilize cache and improve response speed, providing stable online services.
- Ad-Hoc analysis cluster: Use an analytical computing cluster, configure larger specifications to provide better query performance for complex queries. Manually adjust cluster specifications during use based on actual query needs. Set a longer auto-stop time to retain cache and further enhance query performance.
- Configure dedicated clusters for different scheduling tasks, analytical queries, and online reports to isolate the load of different tasks.
Effect:
- Workloads do not interfere with each other, maximizing resource utilization.
- SLAs for different scenarios are guaranteed, avoiding situations where "one large job slows down all other queries" or "online queries crowd out offline tasks."