Redefining ELT: A New Approach to ELT with Singdata Lakehouse
Issues and Challenges
In many data projects, especially those closely related to ML and AI, development often requires a mix of Python and SQL. For example, Python code development is done through Jupyter Notebook, while SQL code development is done using data management and development tools like DBV and VS Code. This approach often leads to issues such as lack of version control and a unified scheduling service, making development and operations complex and troublesome.
With the development of the modern data stack, new-generation BI and AI analysis products like Metabase and MindsDB have also seen rapid growth. How data platforms can closely integrate into the modern data stack and provide a complete solution has become crucial.
For the increasing amount of semi-structured data and vector data, such as CSV and JSON, relying on client-side parsing severely impacts overall processing speed. This requires a data platform capable of efficiently handling both structured data in tables and JSON and vector data. For example, the hourly event archive dataset provided by GH Archive is available in JSON format.
In data engineering tasks involving data cleaning and transformation, many intermediate tables often need to be developed to achieve the desired result table. Improving efficiency in this area has become an important topic for enhancing the productivity of data engineers.
A New Approach to ELT with Singdata Lakehouse
Today, the author attempts to use Singdata Lakehouse to find new solutions to the above problems through the following three aspects.

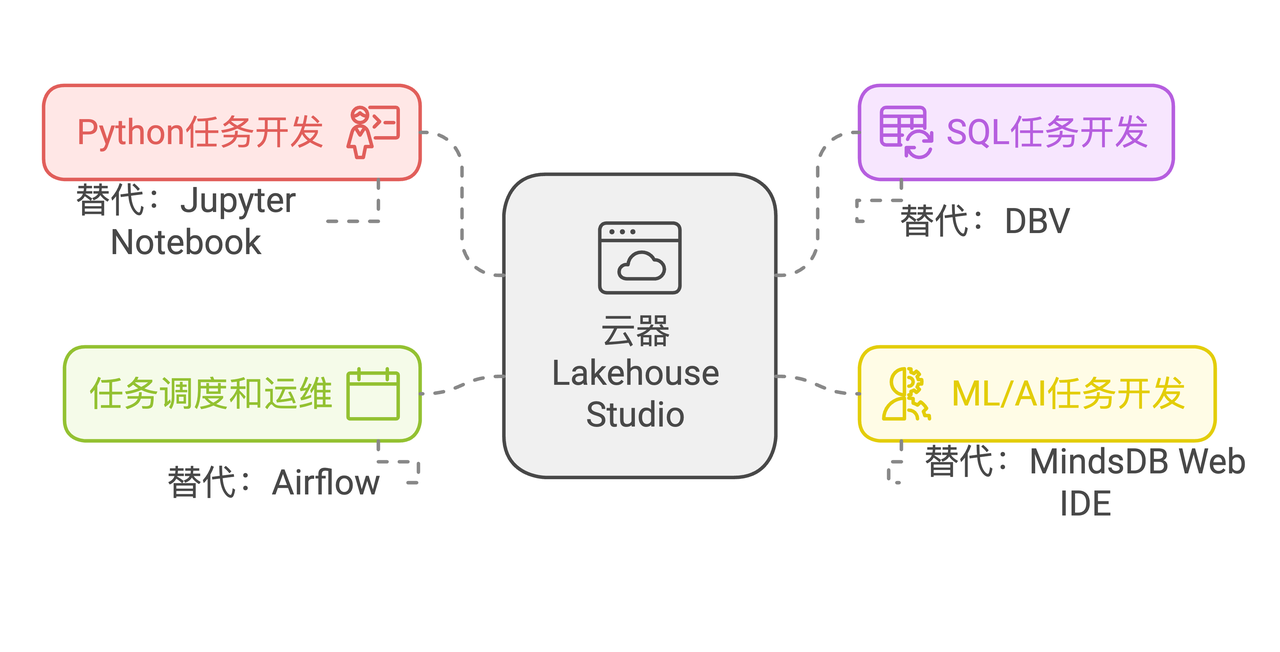
Unified Data Task Development and Scheduling
Simplify data task development and operations environment with Singdata Lakehouse, achieving unified task version management:
-
Python Task Development: From Jupyter Notebook development to Python task development in Singdata Lakehouse Studio.
-
SQL Task Development: From DBV SQL task development to SQL task development in Singdata Lakehouse Studio.
-
ML/AI Task Development: From MindsDB Web IDE to JDBC task development in Singdata Lakehouse Studio.
-
Task Scheduling and Operations: From Airflow to task scheduling and operations in Singdata Lakehouse Studio.
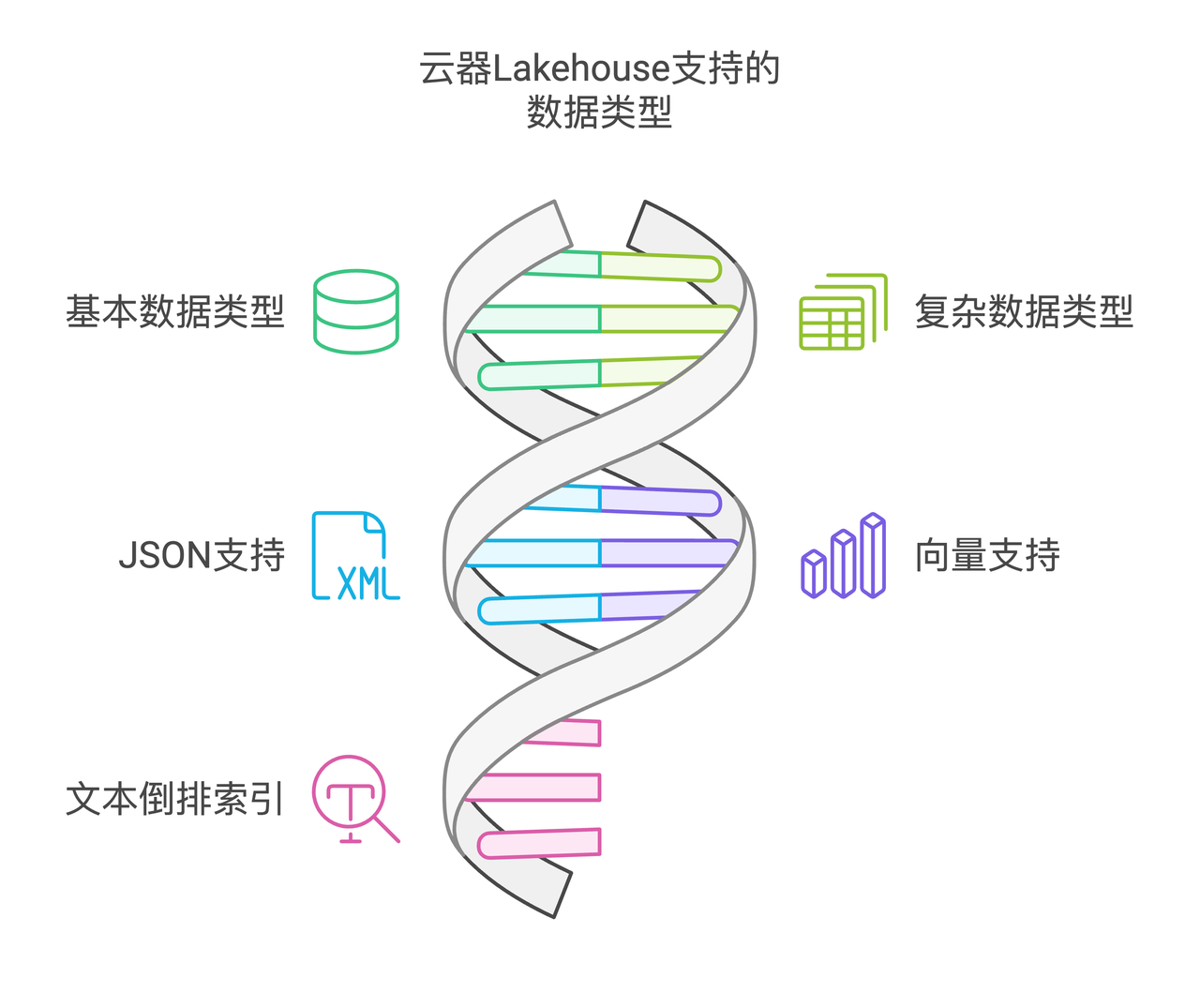
Support for Multiple Data Types
Singdata Lakehouse supports efficient storage and access for the following data types:
-
Common basic data types in tables
-
Common complex data types in tables
-
JSON
-
Vector
-
Text inverted index
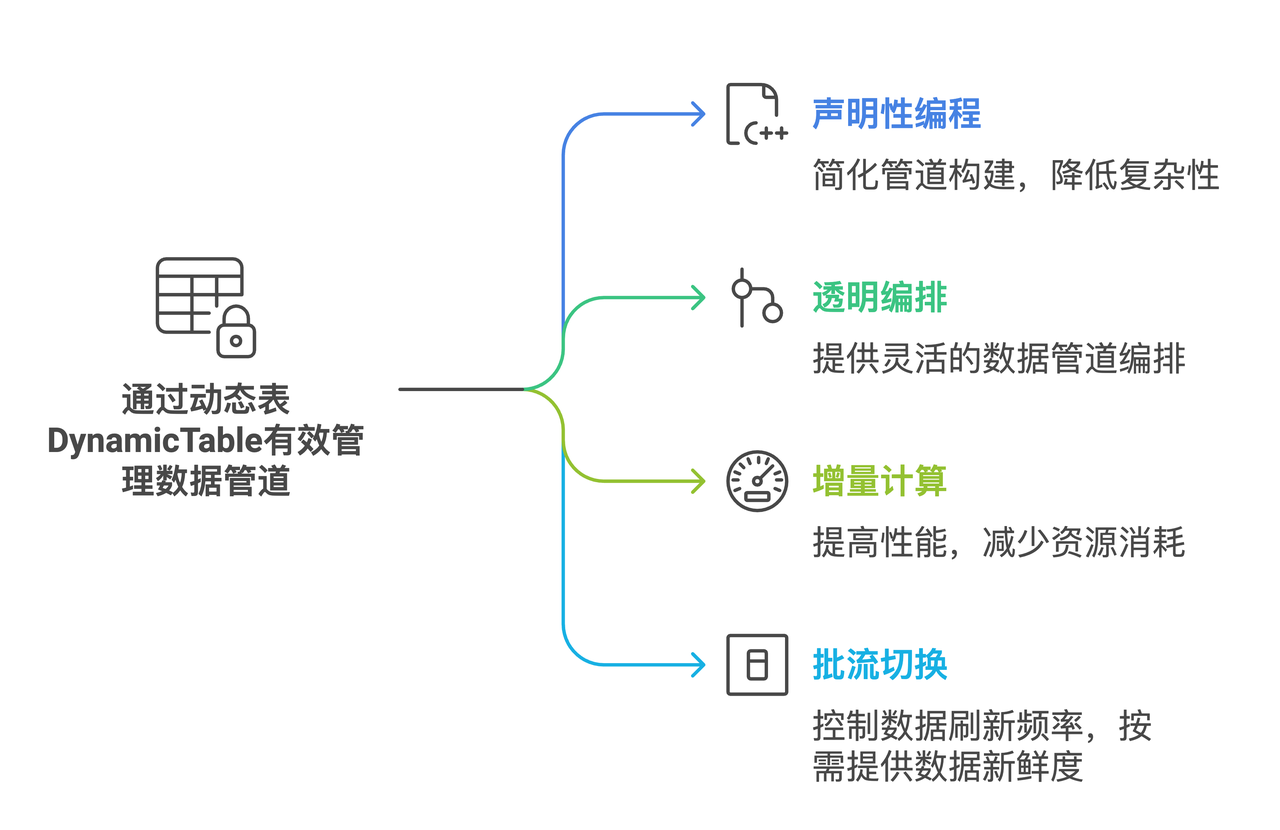
Dynamic Table
Dynamic Table provided by Singdata has the following typical features:
-
Declarative Programming: Define pipeline results with declarative SQL, eliminating the need to consider intermediate table logic, reducing complexity.
-
Transparent Orchestration: Manage refresh orchestration scheduling by linking dynamic tables and regular tables together.
-
Incremental Processing: Suitable for incremental workloads, dynamic tables perform well.
-
Easy Switching: Transition from batch processing to stream processing with a single command, balancing cost and freshness.
-
Observability: Dynamic tables can be managed through the Singdata Lakehouse Web console Studio, enhancing observability.
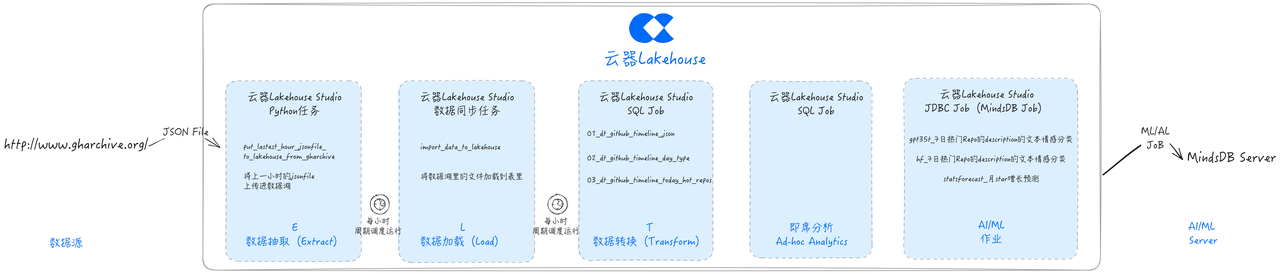
Application Case: Implementing GHArchive Data ELT Process
Data Source Introduction: GHArchive
Open source developers worldwide are engaged in millions of projects, covering activities such as writing code and documentation, fixing bugs, and making commits. The GH Archive project records public GitHub event data, providing over 13 years of GitHub event data since February 12, 2011, archiving it, and making the data more accessible for further analysis.
GitHub has over 15 types of events, such as new commits and fork events, opening new issues, comments, and adding members to projects. These events are aggregated into hourly archive files, accessible with any HTTP client. Each archive file contains events reported by the GitHub API encoded in JSON. Users can download the raw data and process it themselves, such as writing custom aggregation scripts or importing it into a database!
An example of GitHub event data is as follows:
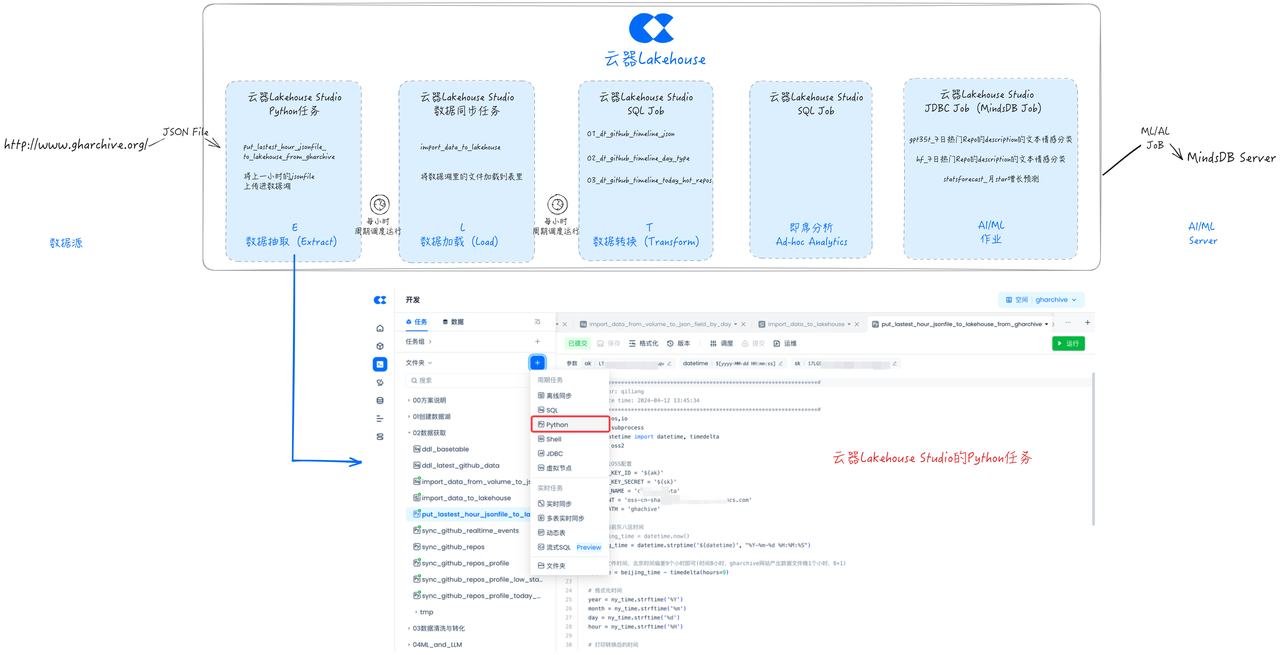
Development Task: Data Extraction (Extract)
Next, we will develop a Python task using Singdata Lakehouse Studio to extract data from the GH Archive website to the data lake storage (in this solution, Alibaba Cloud OSS).
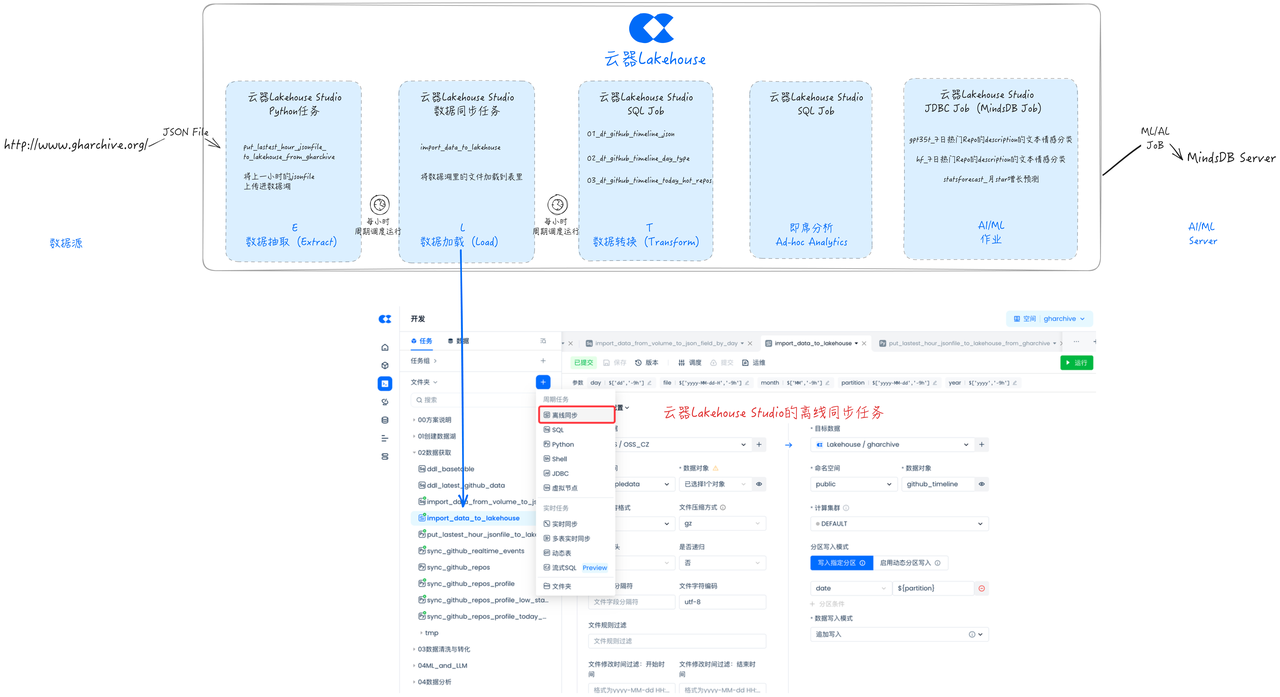
Development Task: Data Loading Task (Load)
Singdata Lakehouse Studio supports loading data from the data lake into the Lakehouse Table through offline synchronization tasks, storing it in an optimized format, and facilitating fine-grained permission management.
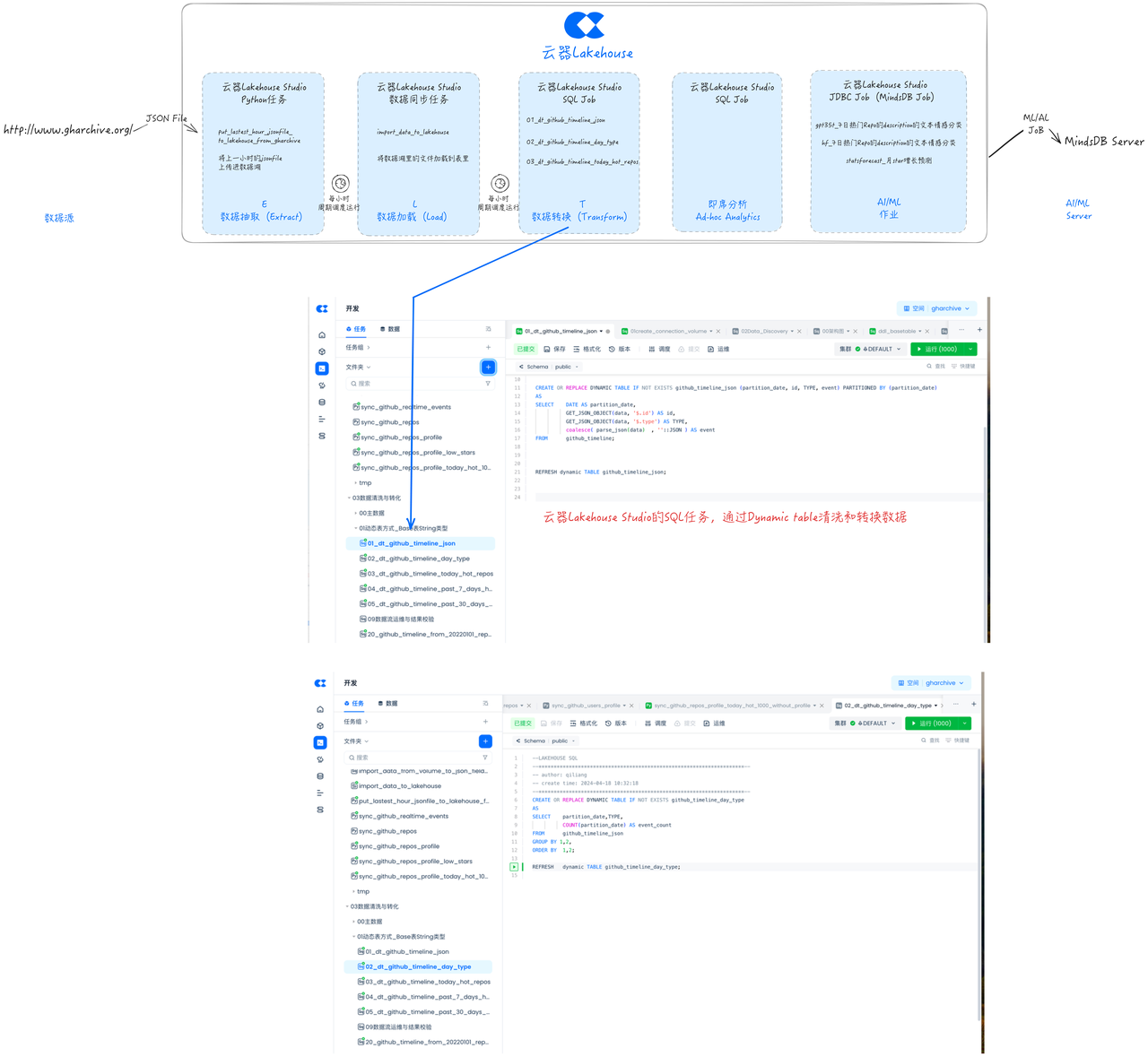
Development Task: Data Cleaning and Transformation (Transform)
Singdata Lakehouse Dynamic Table is a table that supports processing only incremental data changes, with incremental refresh optimization capabilities. Compared to traditional ETL tasks, dynamic tables do not require full data computation or specifying incremental logic (such as aligning by partition or using max(system/event_time)). Users only need to directly declare and define business logic, and the dynamic table can automatically optimize incremental calculations.
This article uses dynamic tables for data cleaning and transformation.
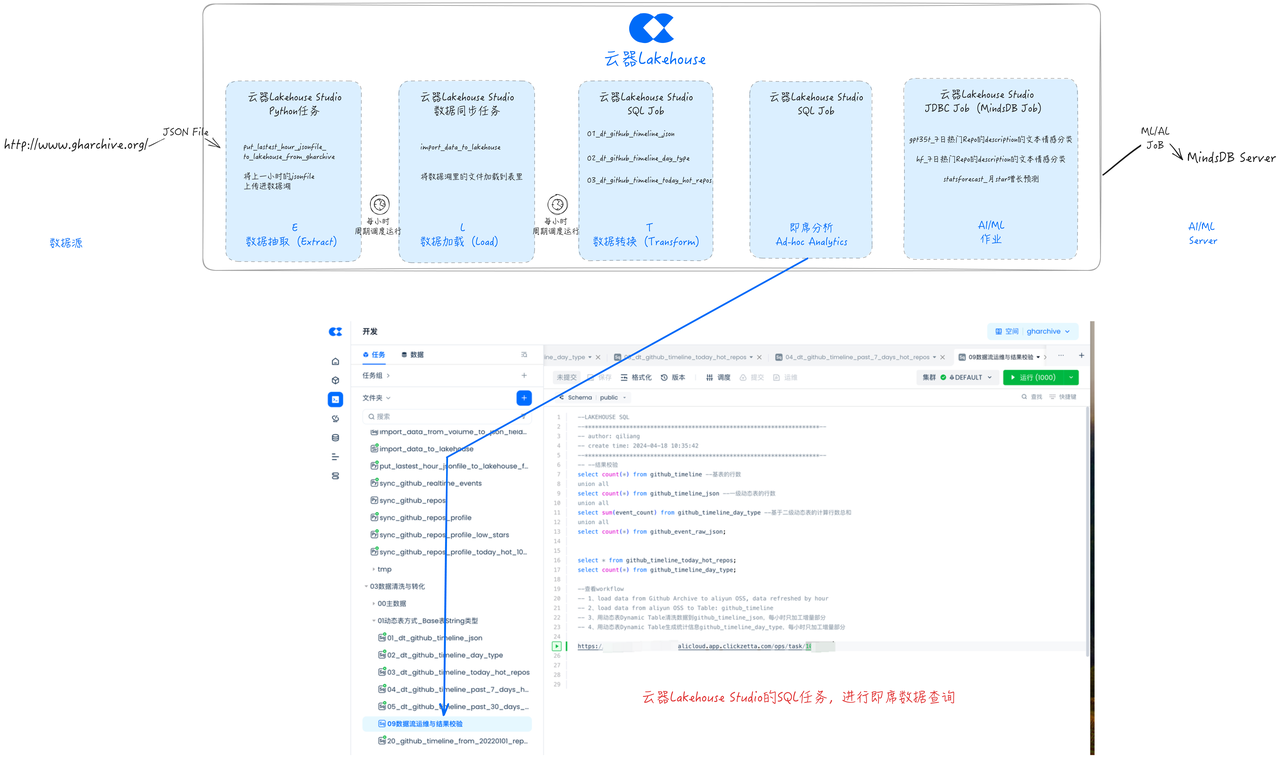
Ad Hoc Data Analysis
Singdata Lakehouse has a built-in convenient SQL query interface, allowing users to freely write SQL code, use variables, select clusters, and perform flexible ad hoc data analysis. It is also convenient for debugging and running.
Development Task: AI/ML Enhanced Analysis
Based on the JDBC task node provided by Lakehouse Studio, it is easy to connect to MindsDB for enhanced data analysis.
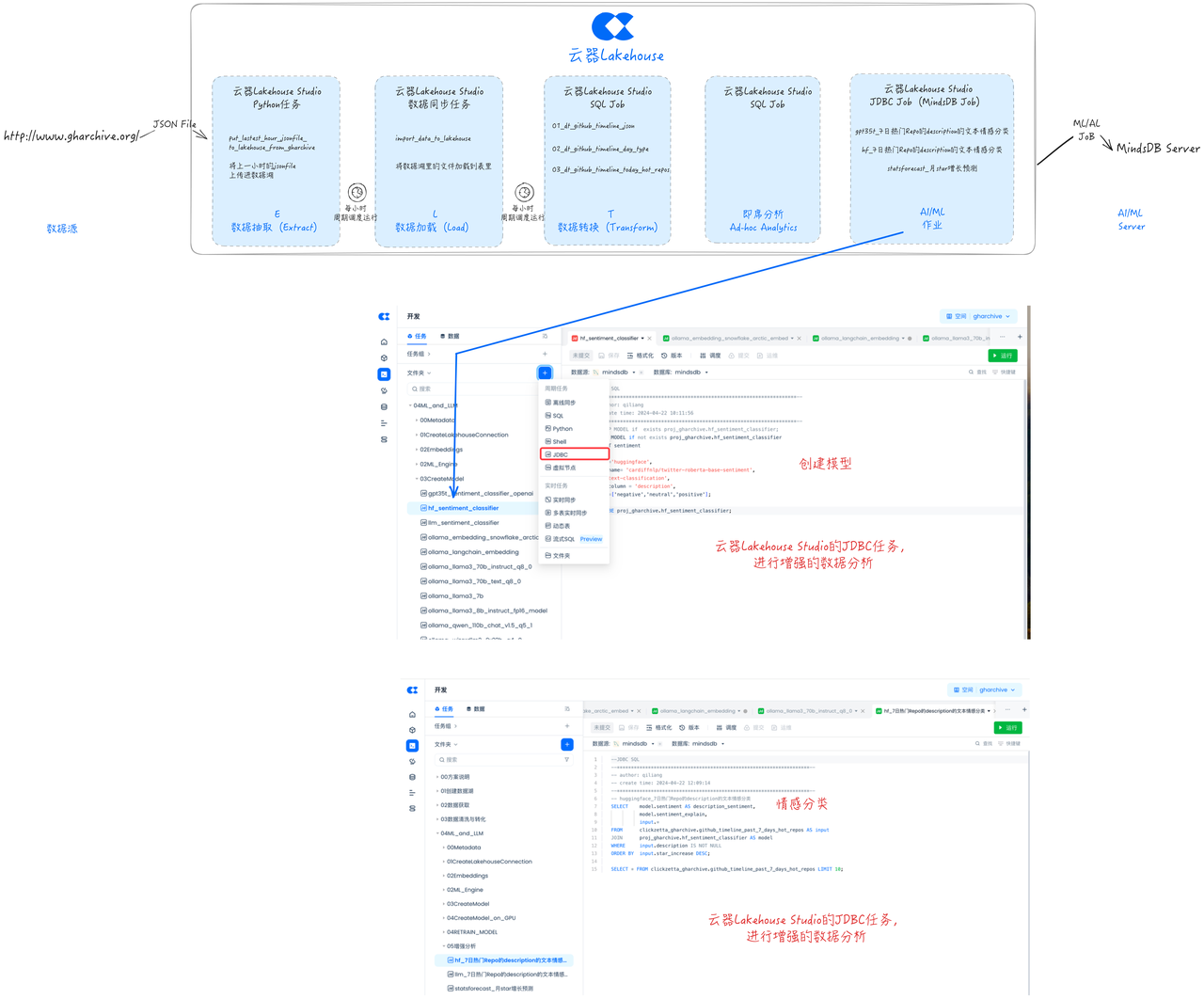
Incremental Synchronization Task Scheduling
Schedule and configure dependencies for the previously developed ELT tasks to ensure that the tasks run on an hourly cycle. Submit the task for publishing, so that data from GHArchive can be synchronized to the Github event data from one hour ago on an hourly basis, and then cleaned and transformed.
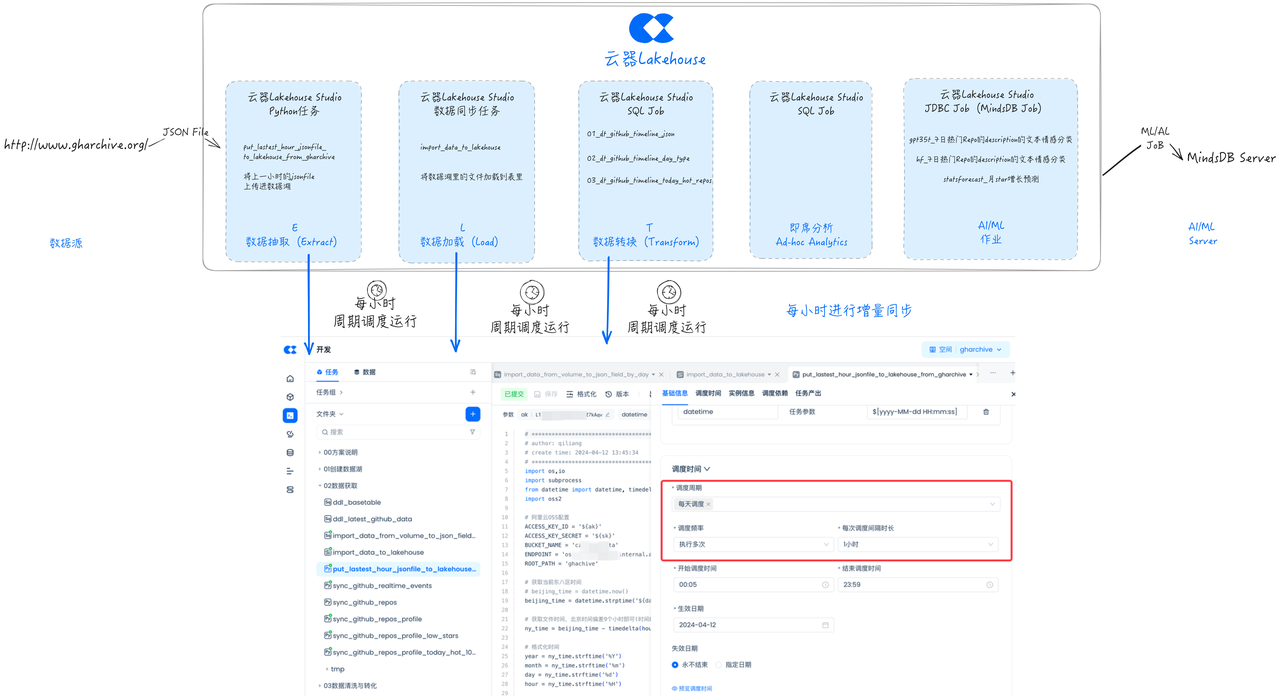
Full Data Supplementation
For data supplementation tasks in Singdata Lakehouse Studio, they can be fully reused with incremental tasks. You only need to configure and execute the supplementation task according to the start and end dates of the full data to brush historical stock data back and forth.
Taking GHArchive data as an example, at http://www.gharchive.org/, the data start date is February 12, 2011. Configure the supplementation task as shown below and run it to achieve full data synchronization. It can be performed simultaneously with incremental data synchronization tasks without developing new full synchronization tasks.
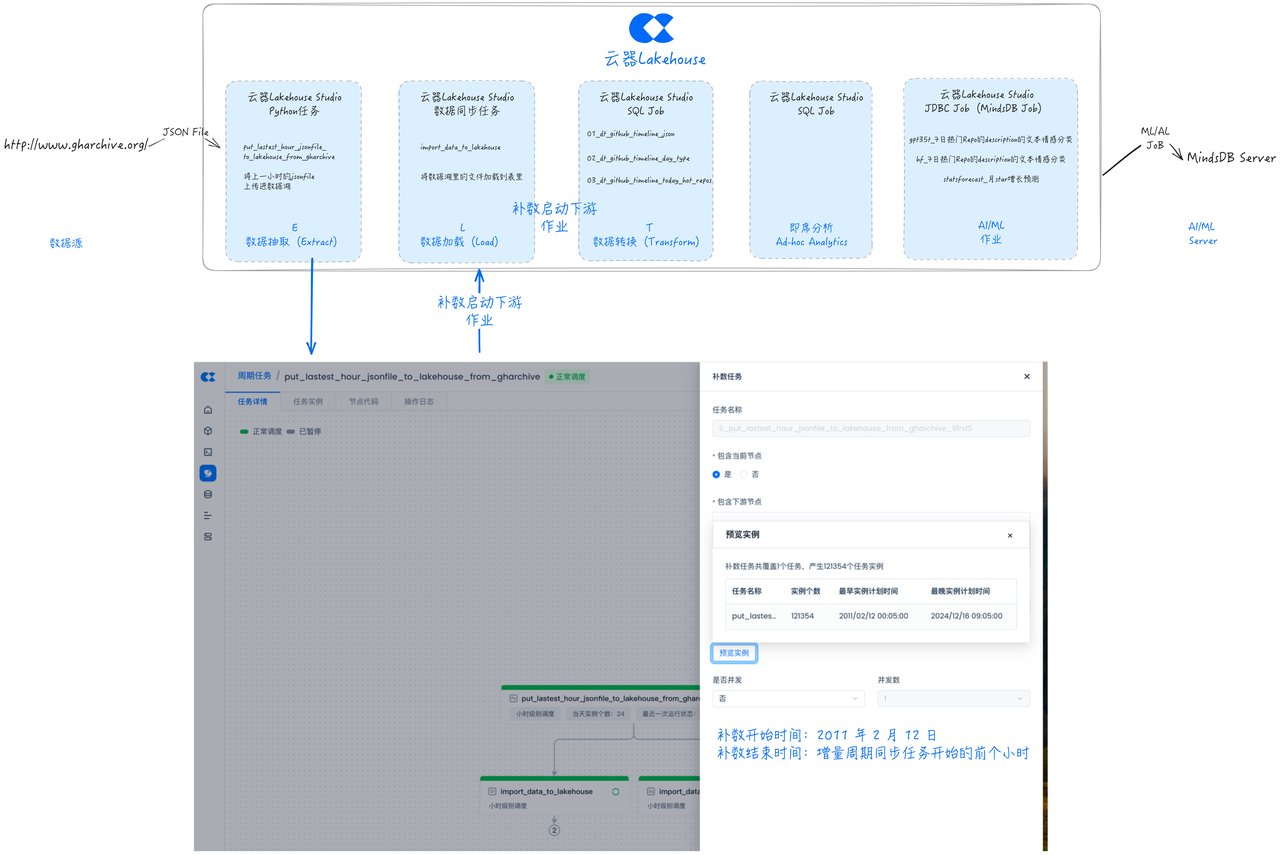
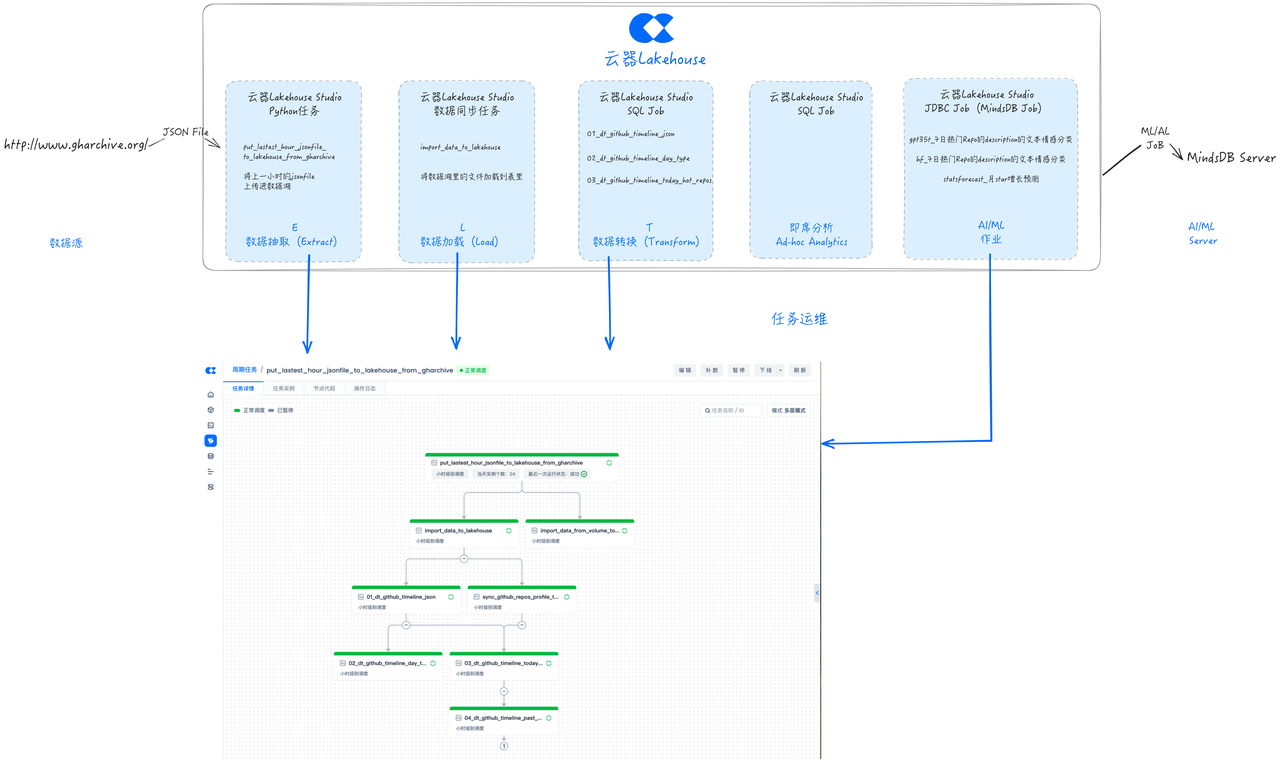
Task Operations and Maintenance
Singdata Lakehouse Studio also provides a comprehensive operations and maintenance interface, such as displaying the upstream and downstream DAG relationships of tasks, running status, and performing rerun operations.
Summary
This article discussed the problems and challenges of traditional development methods in data projects, especially those closely related to ML and AI, and how to achieve a new way of GHArchive ELT through Singdata Lakehouse, enabling unified development, scheduling, and operations and maintenance, significantly simplifying the solution's product components, and helping to greatly improve efficiency and save management costs. Key points include:
- Unified Data Task Development and Scheduling: Simplify development and operations environments, achieve consistent task version management, covering Python, SQL, ML/AI task development, and unified task scheduling orchestration and operations control.
- Support for Multiple Data Types: Efficient storage and access of common basic data types, complex data types, JSON, Vector, text inverted index, etc.
- Dynamic Table: Features declarative programming, transparent orchestration, incremental processing, easy switching, and observability.
- Application Case: Using GHArchive data as an example, it demonstrates data extraction, loading, cleaning and transformation, ad hoc data analysis, AI/ML enhanced analysis, incremental synchronization task scheduling, full data supplementation, and task operations and maintenance.