Migrate Spark Data Engineering Best Practices Project to Singdata Lakehouse
New Solution Highlights
- Fully Cloud-Based, Focus on Data: Migrate all offline managed environments to the cloud, eliminating non-data-related tasks such as resource preparation and system maintenance.
- Easy to Migrate: Singdata Lakehouse SQL, Zettapark, and Spark SQL, pySpark are highly compatible, making code migration very low in difficulty and cost.
- Reduce Overall Cost and Complexity: Singdata Lakehouse has built-in workflow services and data quality control services, eliminating the need for separate Airflow and Great Expectations. This greatly simplifies the system architecture, reducing overall cost and complexity.
- Openness: It is also possible to retain Airflow and Great Expectations in the architecture, using Airflow to schedule Python tasks and continuously calling Great Expectations in Python code for data quality checks.
- Resource Management and Task Queue Management: Use different Virtual Clusters to handle ETL, BI, and data quality tasks separately, achieving resource isolation and task queue management.
Introduction to Spark Data Engineering Best Practices Project
Background of Spark Data Engineering Best Practices Project
Building data pipelines without sufficient guidance can be overwhelming. It is difficult to determine whether you are following best practices. If you are a data engineer looking to understand the development of your technical skills in building data pipelines but are unsure if you are following industry standards or can compare to data engineers at large tech companies, the Spark Data Engineering Best Practices project on Github is tailored for you. This article reviews best practices for designing data pipelines, understanding industry standards, considering data quality, and writing maintainable and operable code. After completing this project, you will understand the key components and requirements of designing data pipelines and be able to quickly familiarize yourself with any new codebase.
Scenario of Spark Data Engineering Best Practices Project
Assume we extract customer and order information from upstream sources and create hourly reports of order quantities.

The components, tools, and environment used are as follows:
- Data Storage: MinIO with Delta Table Format
- Data Processing: Spark
- Code Language: PySpark + Spark SQL
- Data Quality: Great Expectations
- Workflow: Airflow
- Runtime Environment: Local Docker (Spark, Airflow)
Best Practices of Spark Data Engineering Best Practices Project
Gradually Transform Data Using Standard Patterns
Following established data processing workflows helps address common potential issues, and you can refer to a wealth of resources. Most industry-standard patterns follow a three-layer data warehouse architecture, as follows:
- Raw Layer: Store data in its original state from the upstream source. This layer sometimes involves changing data types and standardizing column names.
- Transformation Layer: Transform data from the raw layer based on selected modeling principles to form a set of tables. Common modeling principles include dimensional modeling (Kimball), Data Vault modeling, entity-relationship data models, etc.
- Consumption Layer: Combine data from the transformation layer to form datasets that directly correspond to end-user use cases. The consumption layer usually involves joining and aggregating transformation layer tables to facilitate end-user analysis of historical performance. Business-specific metrics are usually defined in this layer. We should ensure that a metric is defined in only one place.
- Interface Layer [Optional]: Data in the consumption layer usually confirms the naming/data types of the data warehouse. However, data presented to end-users should be user-friendly and easy to understand. The interface layer is usually a view that serves as an interface between warehouse tables and their consumers.
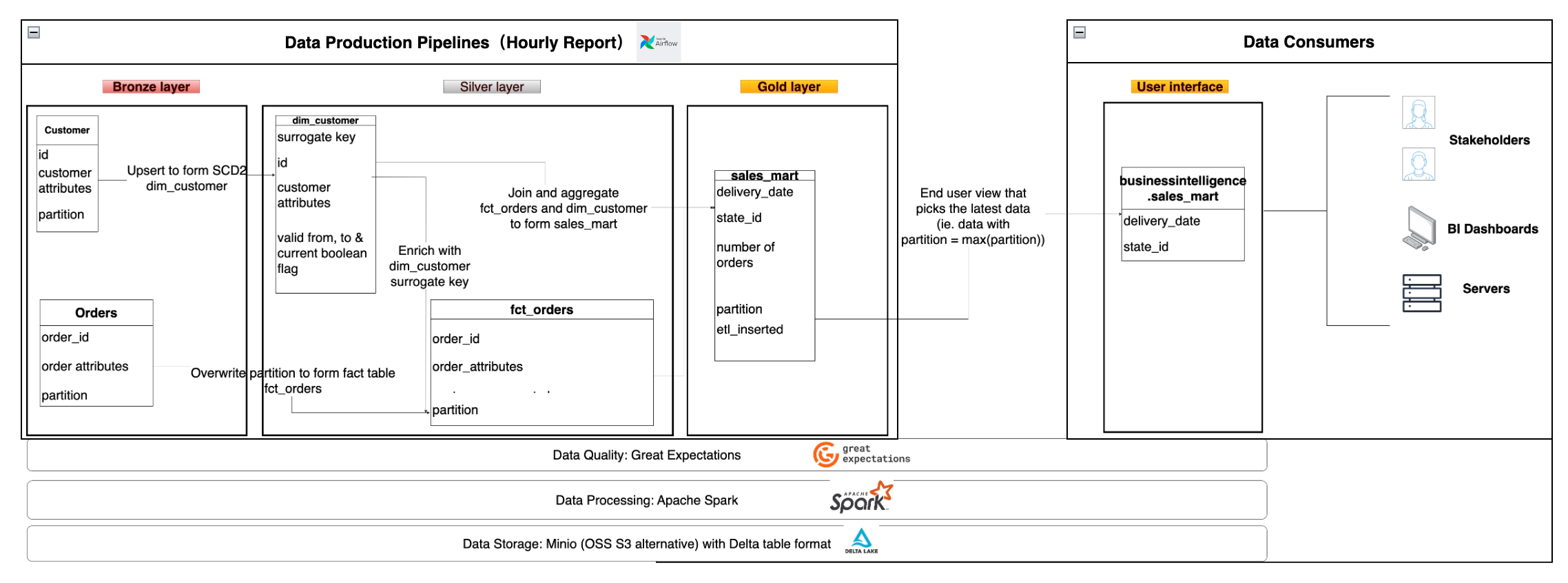
In the above diagram, the Bronze Layer, Silver Layer, Gold Layer, and User Interface Layer correspond to the raw layer, transformation layer, consumption layer, and interface layer, respectively. We use dimensional modeling for the Silver Layer. For pipelines/transformation functions/tables, the input is referred to as "upstream," and the output is referred to as "downstream" consumers. In larger companies, multiple teams work at different levels. The data collection team may import data into the Bronze Layer, while other teams can build their own Silver Layer and Gold Layer tables based on their needs.
Ensure Data Validity Before Providing It to Consumers (Also Known as Data Quality Checks)
In constructing datasets, it is crucial to clearly define expectations for the data. These expectations can be as simple as ensuring columns meet requirements or as complex as satisfying more intricate business needs. The consequences of downstream consumers using poor data can be disastrous. For example, sending incorrect data to customers or making financial expenditures based on inaccurate data. Correcting the use of poor data often requires a significant amount of time and re-running all affected processes!
To prevent consumers from inadvertently using poor data, we should inspect the data before making it available for use.
This project uses the Great Expectations library to define and run data checks.
Using Idempotent Data Pipelines to Avoid Data Duplication
Re-running, or re-executing data pipelines, is a common operation. When re-running data pipelines, we must ensure that the output does not contain duplicate rows. The characteristic of a system that always produces the same output given the same input is called idempotency.
The following demonstrates two techniques to avoid data duplication when re-running data pipelines:
- Overwrite based on Run ID: Used for append-only output data. Ensure that your output data has a run ID as a partition column (e.g., the partition column in our gold table). The run ID indicates the time range to which the created data belongs. When reprocessing data, overwrite based on the given run ID.
- UPSERTS based on Natural Keys: Used when the pipeline performs inserts and updates on output data using natural keys. This is used when dimension data of existing rows needs to be updated (e.g., SCD2 adopts this method). Duplicates generated by re-running the pipeline will result in updates to existing rows (rather than creating new rows in the output). We use this method to populate the dim_customer table.
Migration Plan
New Architecture Based on Singdata Lakehouse
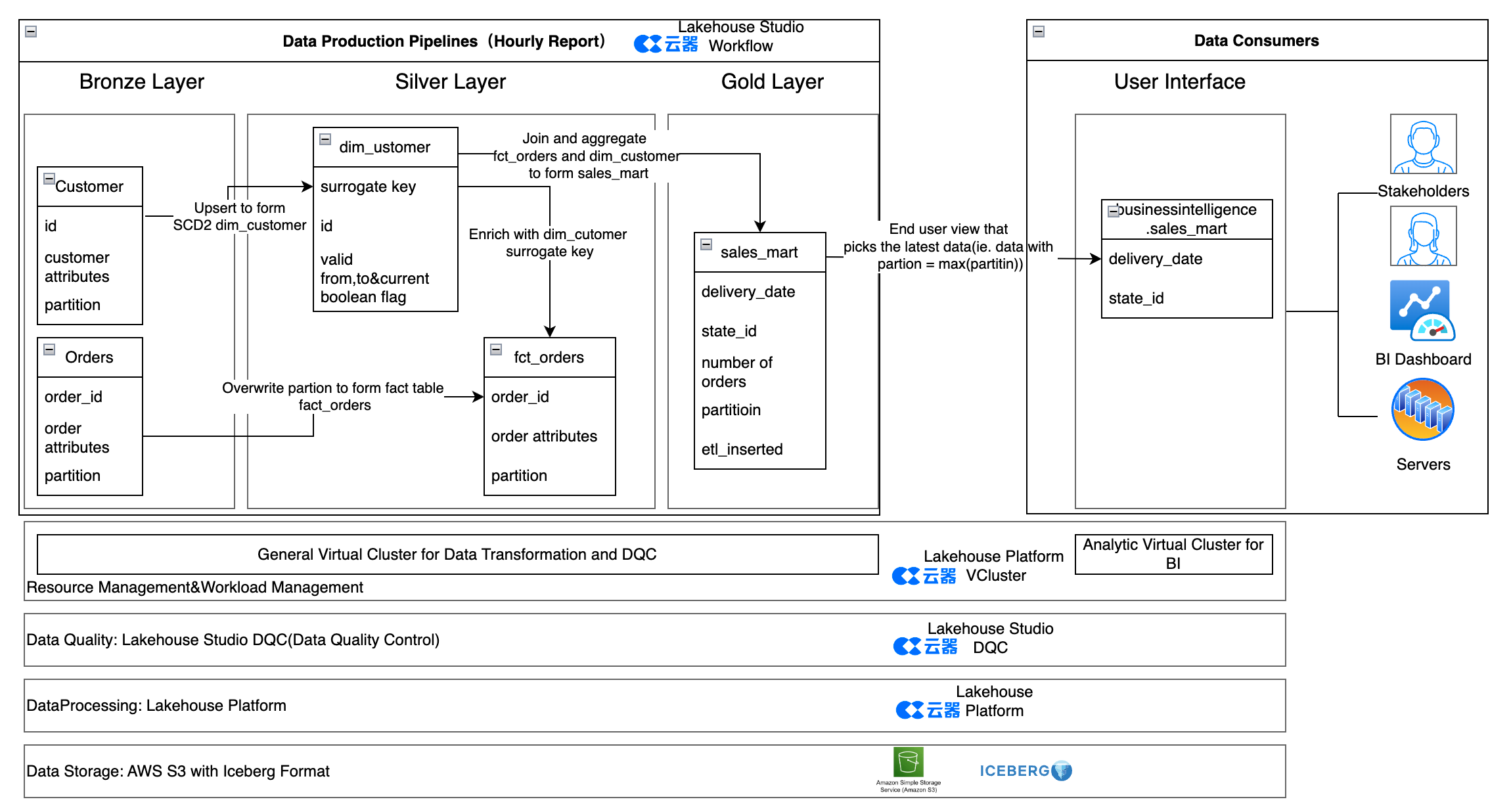
Component Comparison of the Two Solutions
| Component | Spark Solution | Singdata Lakehouse Service |
|---|---|---|
| Data Storage | MinIO with Delta Table Format | Alibaba Cloud OSS (or AWS S3, etc) with Iceberg Table Format |
| Data Processing | Spark | Singdata Lakehouse |
| Code Language | PySpark + Spark SQL | ZettaSpark + Lakehouse SQL |
| Data Quality | Great Expectations | Singdata Lakehouse DQC (Data Quality) |
| Workflow | Airflow | Singdata Lakehouse Workflow |
| Runtime Environment | Local Docker (Spark, Airflow) | Cloud Serverless Service |
Syntax Differences
| Function | Spark Syntax | Singdata Lakehouse Syntax |
|---|---|---|
| 建表DDL | CREATE TABLE ... USING DELTA ... LOCATION '{path}/customer' | CREATE TABLE, no need for USING DELTA and LOCATION '{path}/customer' |
| 创建Session | SparkSession.builder.appName | Session.builder.configs(connection_parameters).create() |
Features of the New Solution
- Fully Cloud-based, Data-focused: Migrate all offline managed environments to the cloud, eliminating non-data-related tasks such as resource preparation and system maintenance.
- Easy to Migrate: Singdata Lakehouse SQL, Zettapark, and Spark SQL, pySpark are highly compatible, making code migration low in difficulty and cost.
- Reduced Overall Cost and Complexity: Singdata Lakehouse has built-in workflow services and data quality control services, eliminating the need for separate Airflow and Great Expectations. This greatly simplifies the system architecture, reducing overall cost and complexity.
- Openness: It is also possible to retain Airflow and Great Expectations in the architecture, using Airflow to schedule Python tasks and continuously calling Great Expectations in Python code for data quality checks.
- Resource Management and Task Queue Management: Use different Virtual Clusters to handle ETL, BI, and data quality jobs separately, achieving resource isolation and task queue management.
Migration Steps
Task Code Development
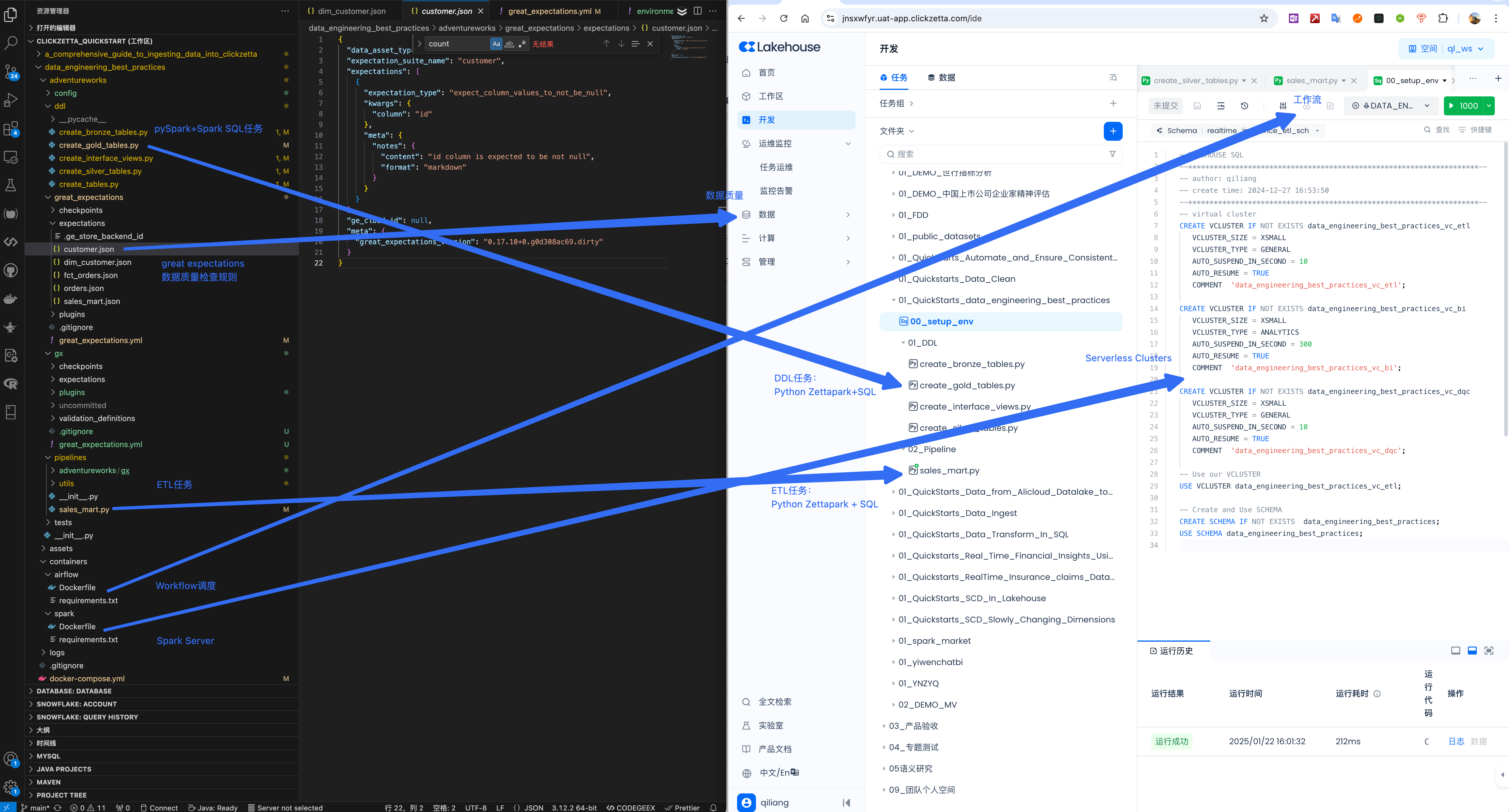
Navigate to Lakehouse Studio Development -> Tasks, and build the following task tree:
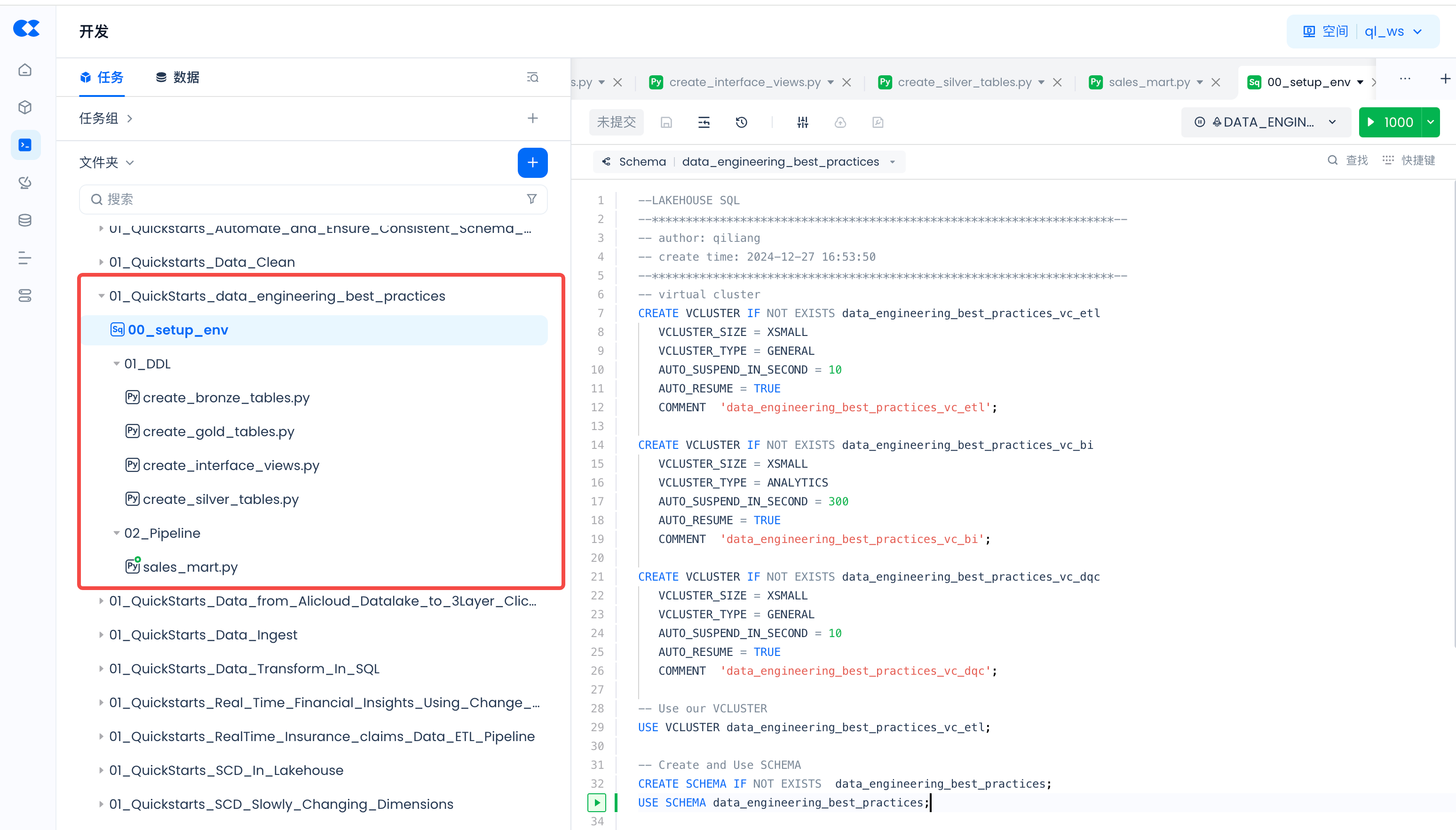
Click "+" to create the following directories:
- 01_QuickStarts_data_engineering_best_practices
Click "+" to create the following SQL tasks:
- 00_setup_env
Click "+" to create the following Python tasks:
- 01_DDL
- create_bronze_tables.py
- create_gold_tables.py
- create_interface_views.py
- create_silver_tables.py
- 02_Pipeline
- sales_mart.py
Visit the Github repository of this migration project and copy the code into the corresponding tasks.
Resource Management and Task Queue Management
In the set_env task, create three Virtual Clusters to run different tasks:
Task Parameter Configuration
01_DDL Task Parameter Configuration
Configure parameters for the following four tasks respectively:
- create_bronze_tables.py
- create_gold_tables.py
- create_interface_views.py
- create_silver_tables.py
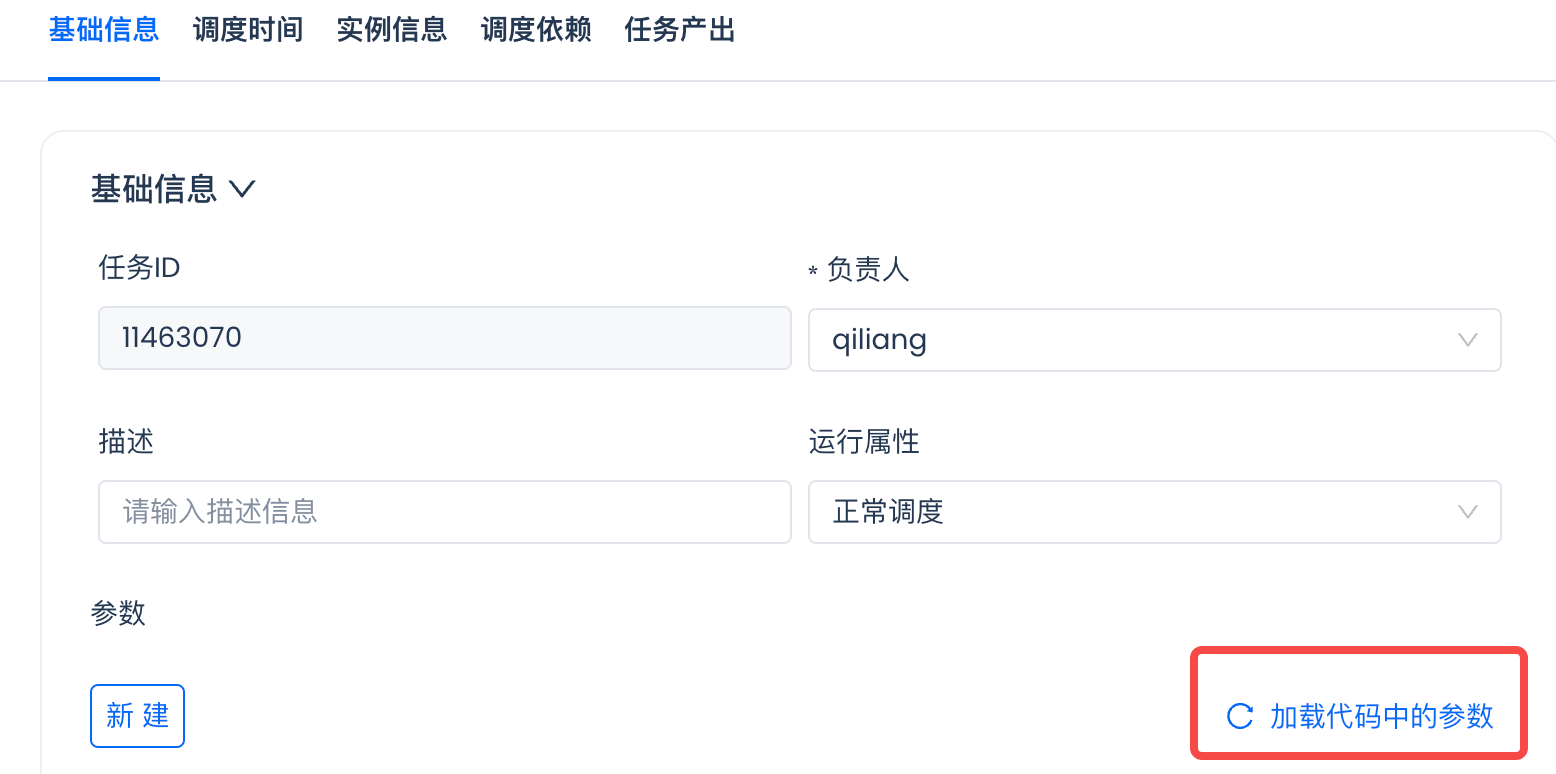
Open the task and click "Schedule":

In the pop-up page, click "Load Parameters from Code":
Set the value for each parameter:
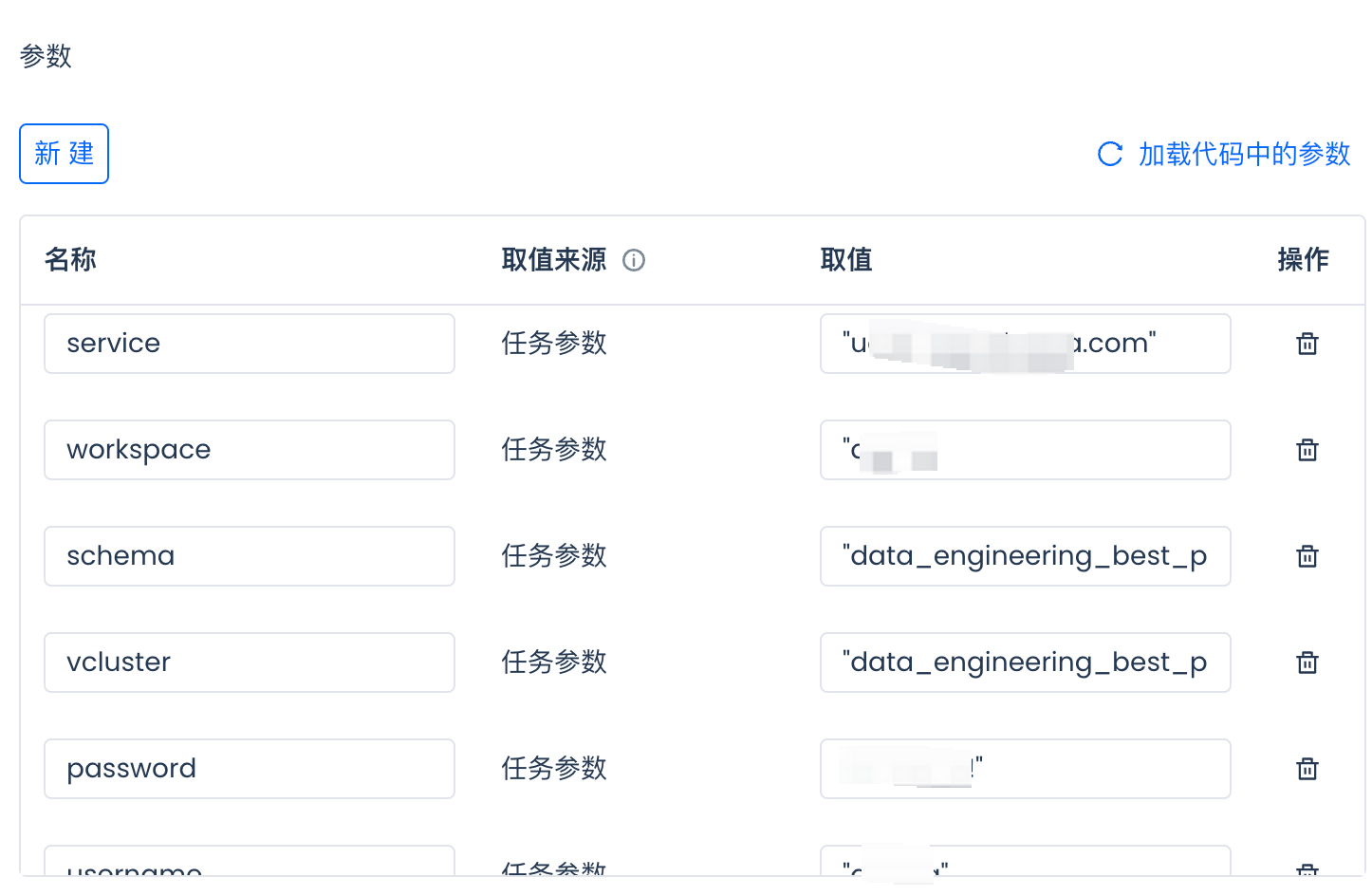
For how to obtain parameter values, please refer to this article.
02_Pipeline ETL Task Parameter Configuration
Configure parameters for the following task, the method of parameter configuration is the same as above.
- sales_mart.py
Create Environment
Run setup_env and DDL temporary tasks to create the virtual compute cluster, database Schema, and Tables required for operation. Create the virtual compute cluster and database Schema required for operation:
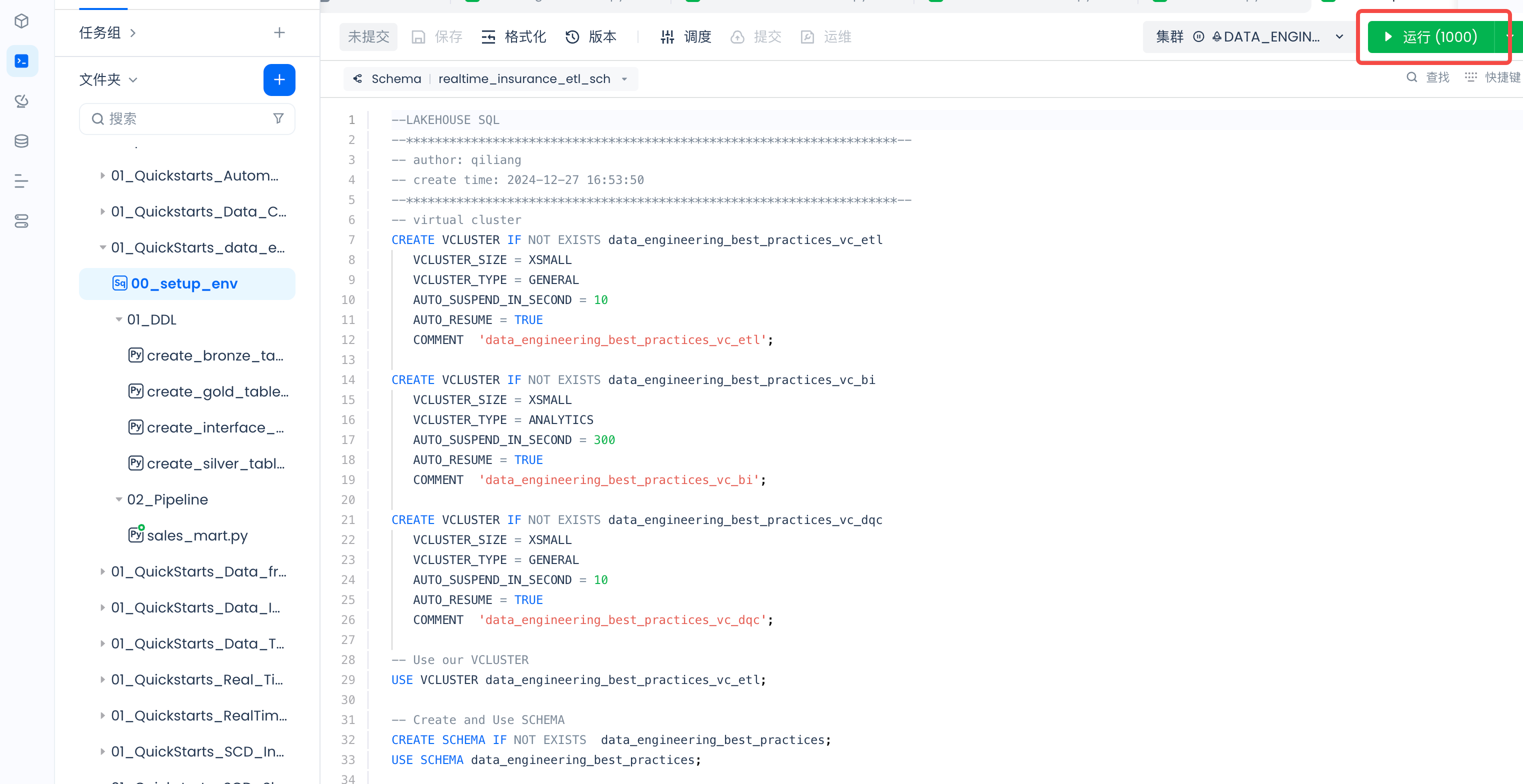
Create Tables:
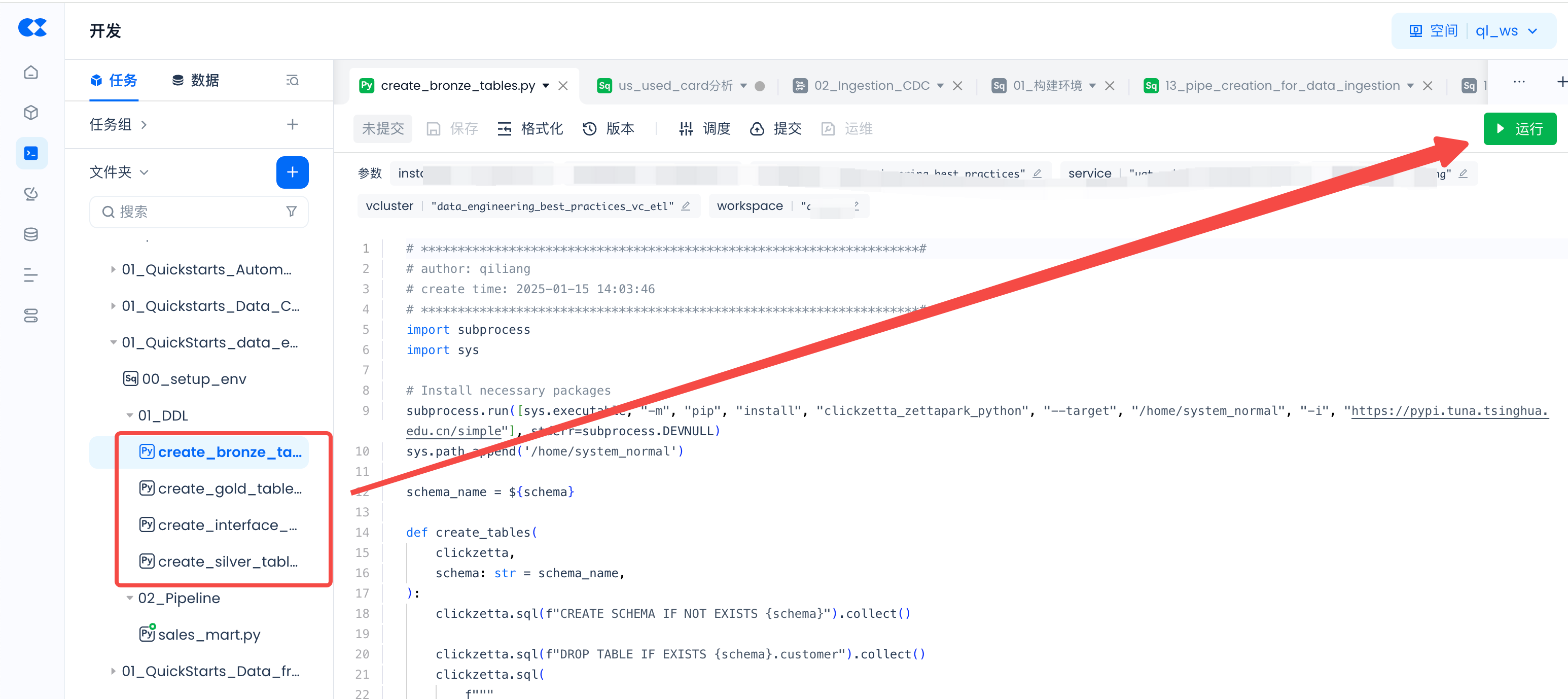
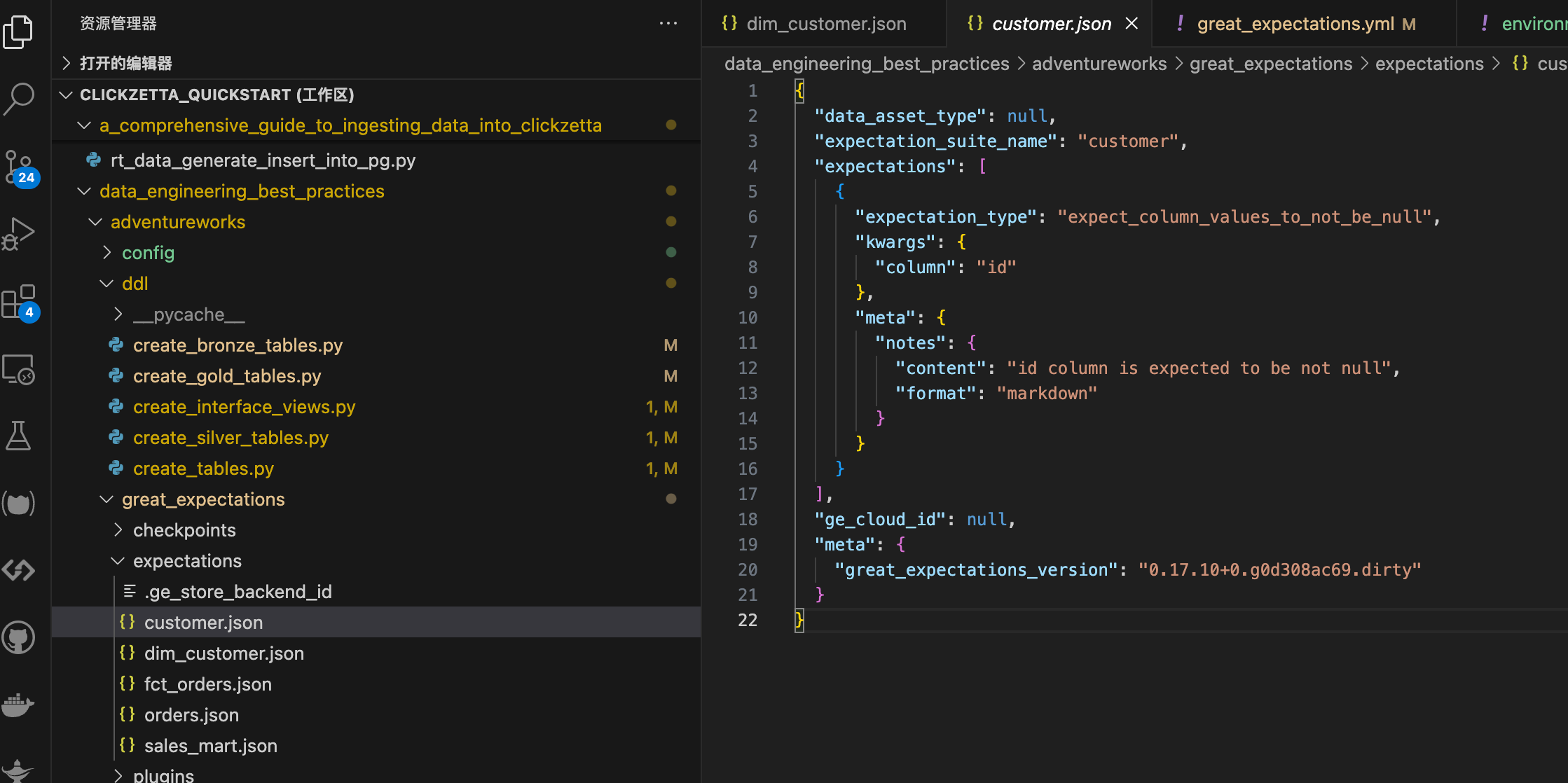
Configure Data Quality Monitoring Rules
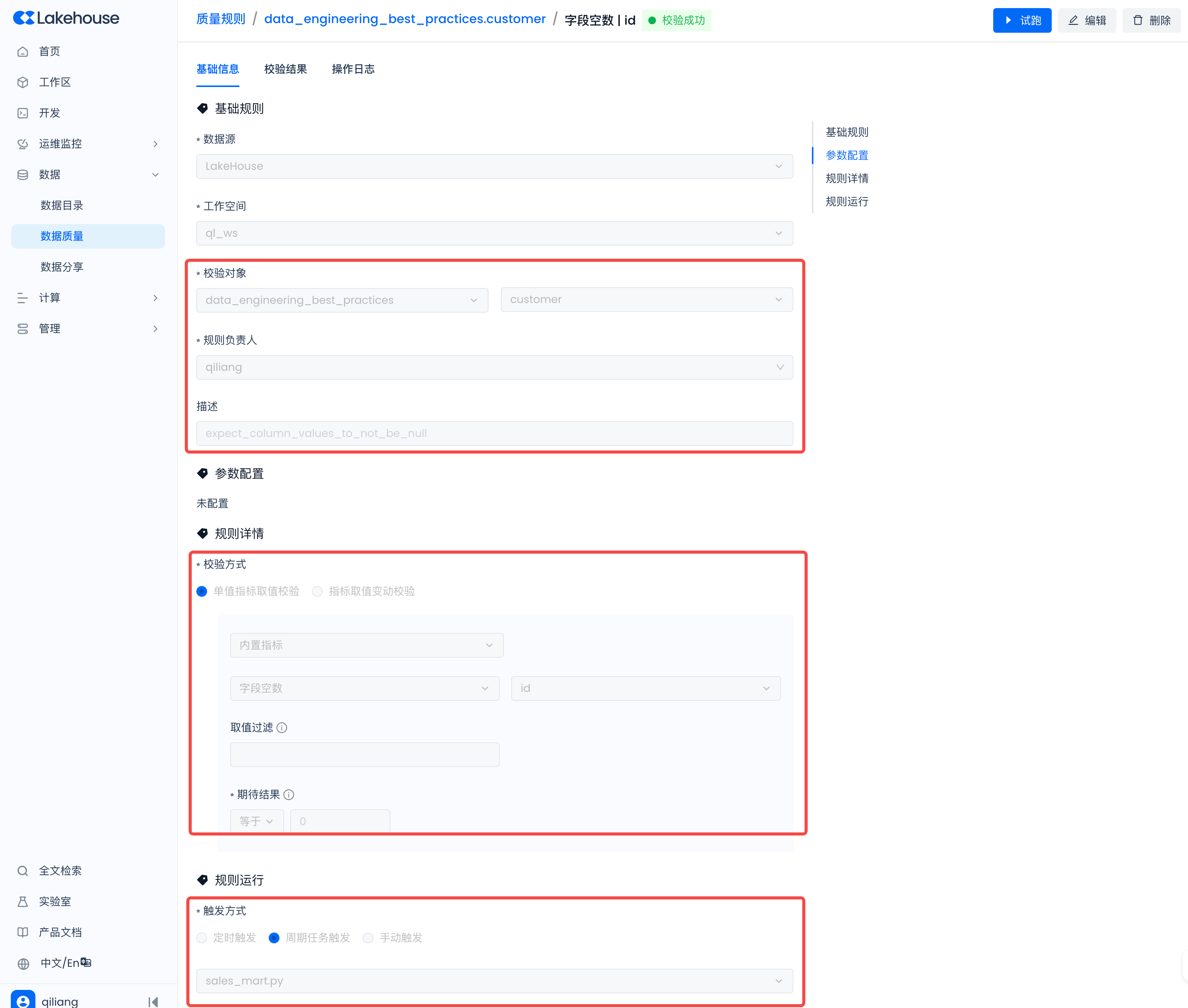
Navigate to Lakehouse Studio -> Data -> Data Quality -> Quality Rules, and create the following rules:

Take expectation_suite_name as customer for example
Configure the following rules:
Workflow Scheduling
Navigate to Lakehouse Studio -> Development -> Tasks, configure the scheduling for the sales_mart.py ETL task:
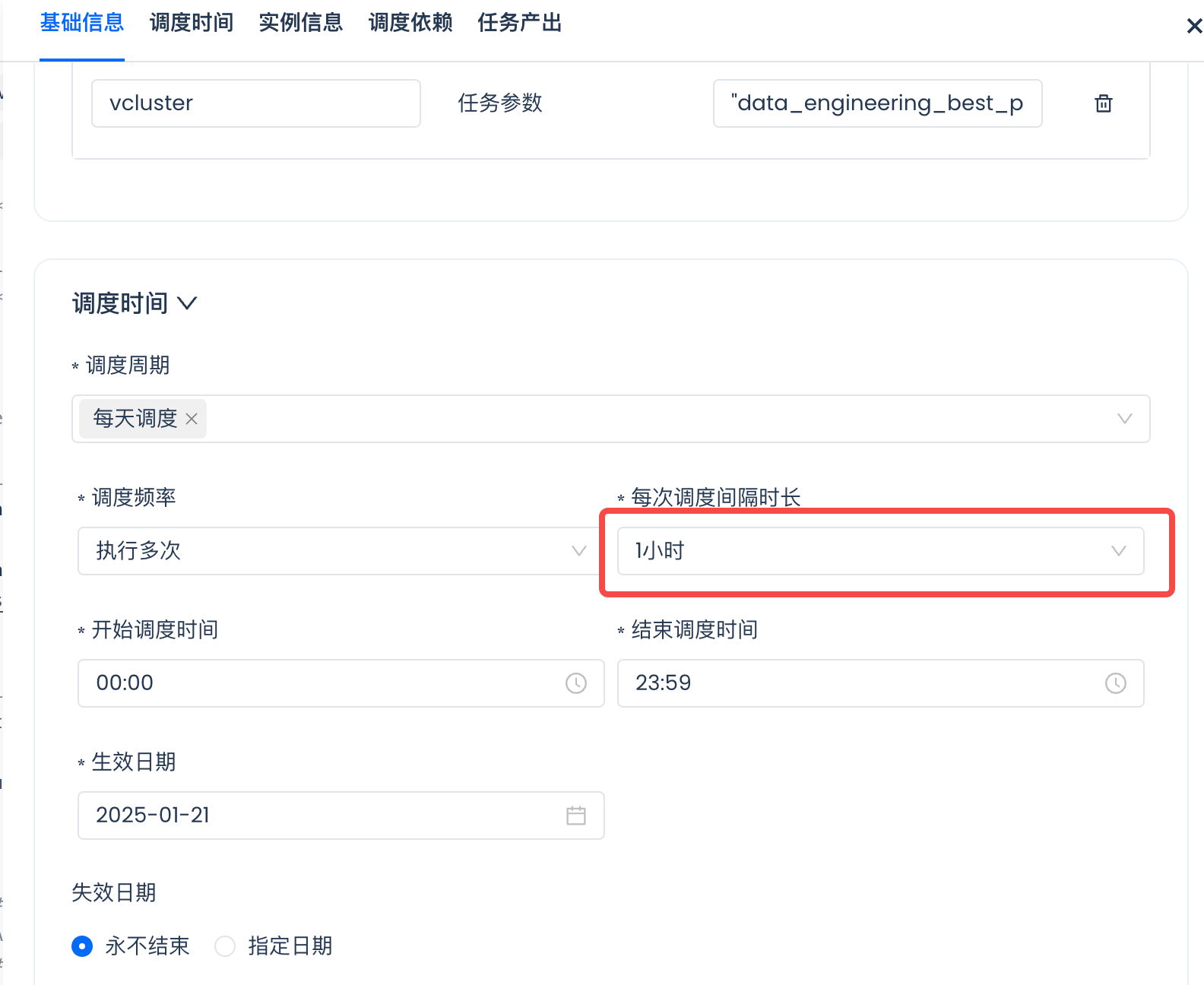
To achieve hourly report data refresh.
Then click "Submit" to execute the ETL task periodically:

Task Operations and Maintenance
ETL Task Operations and Maintenance
Navigate to Lakehouse Studio -> Operations Monitoring -> Task Operations and Maintenance, to view task status, execution logs, instance management, etc.

Data Quality Control
Navigate to Lakehouse Studio -> Data -> Data Quality, where you can configure quality rules to monitor whether the output of data tables is normal.
View validation objects:
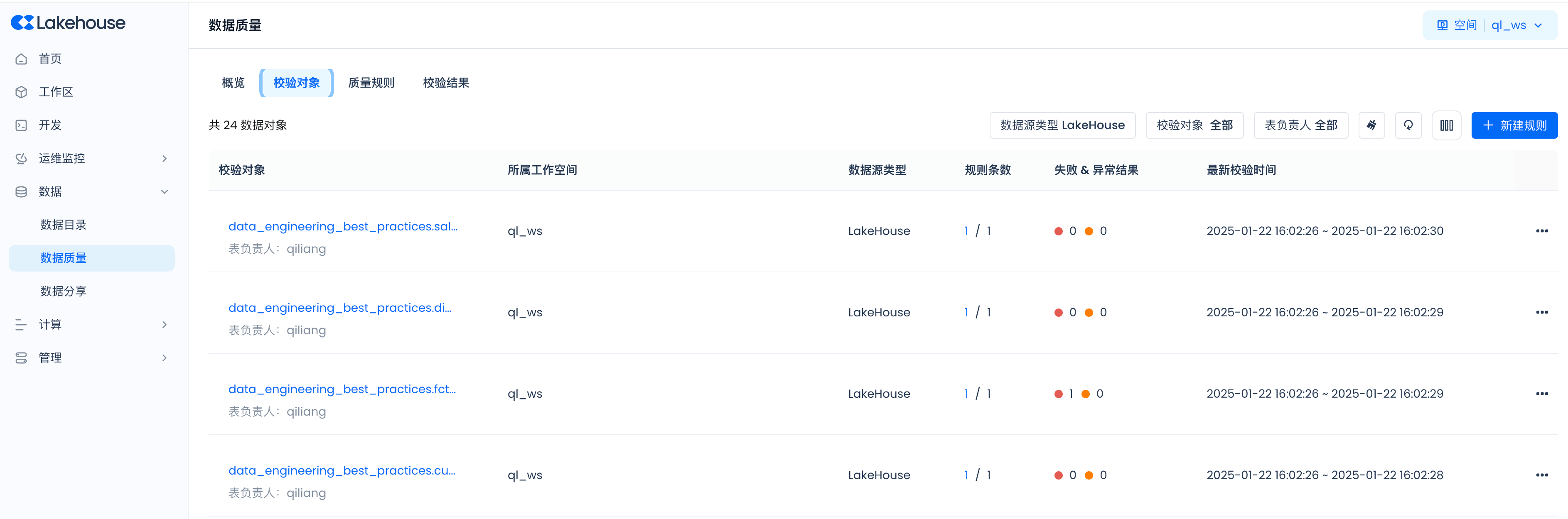
View validation results:
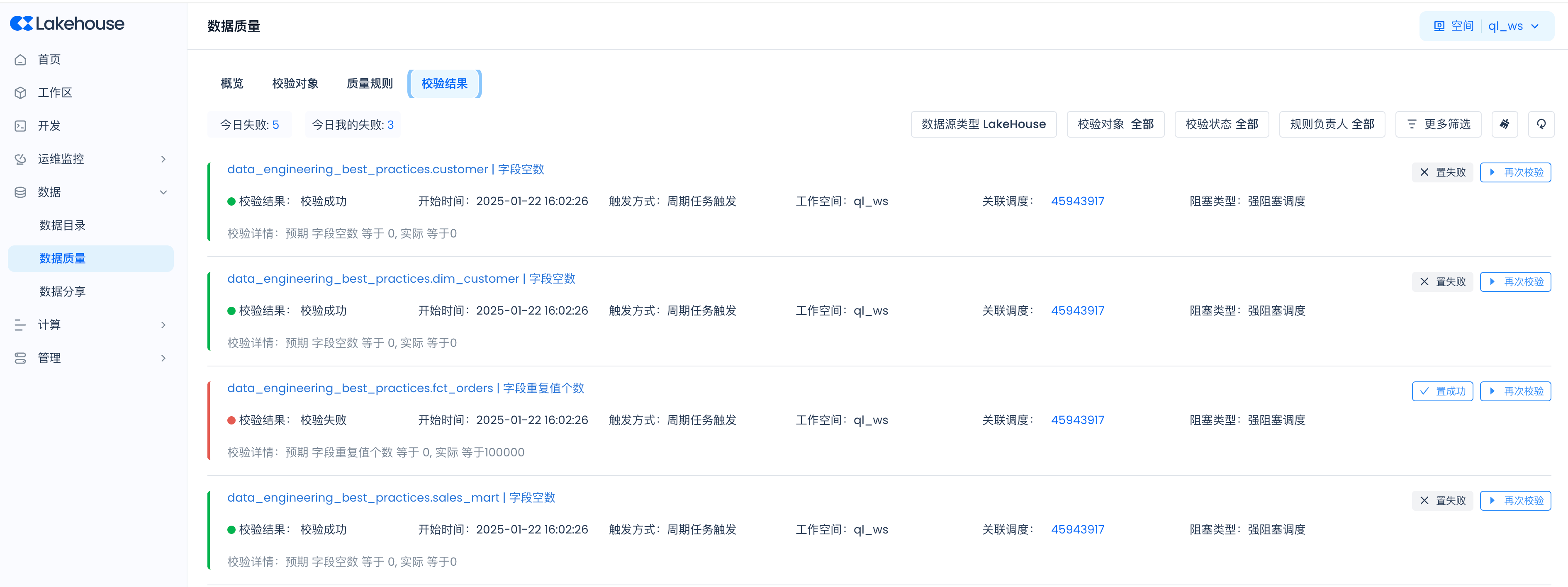
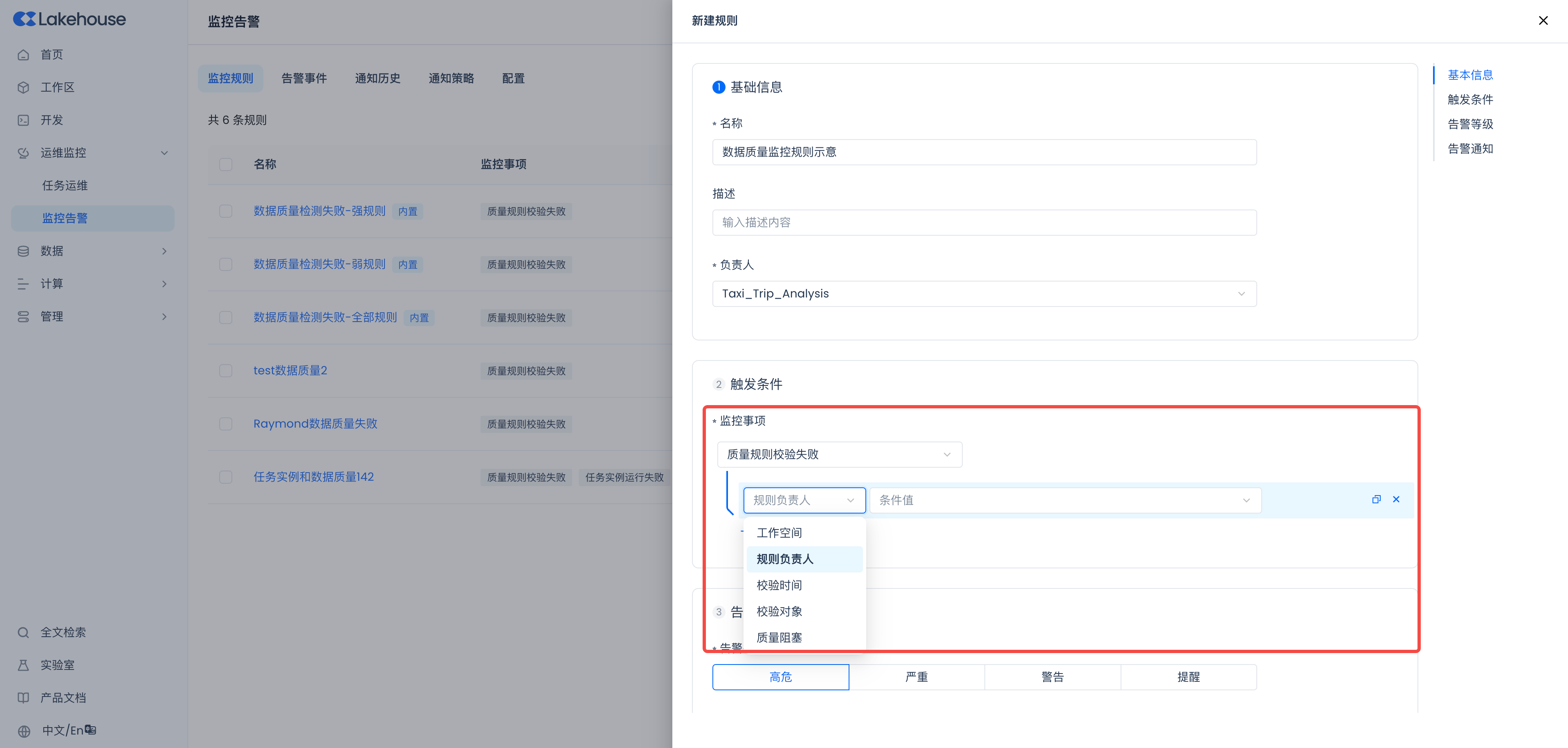
Monitoring and Alert Configuration
Next, you can navigate to Operations Monitoring -> Monitoring and Alerts, add alert rules to achieve real-time alerts for ETL tasks and data quality control.
Using Built-in Monitoring and Alert Rules:
Within the system, the following general monitoring and alert rules are built-in. When data quality validation fails, alerts such as emails, SMS, and phone calls will be triggered according to the specific configuration in the rules.
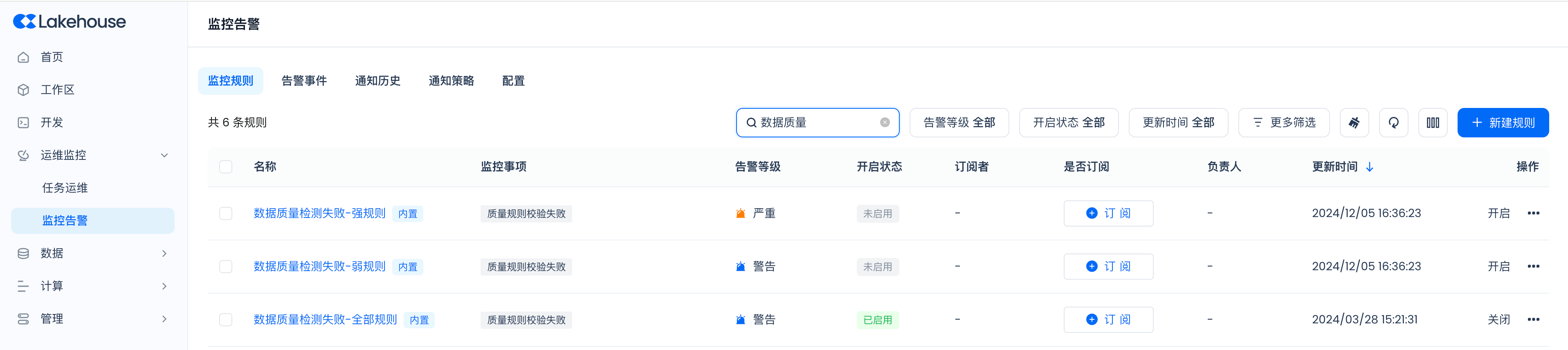
Using Custom Monitoring and Alert Rules:
The above built-in monitoring and alert rules apply to the validation results of all global quality monitoring rules. If you want to further refine the control of the monitoring scope and alert strategy, you can also create custom rules. As shown in the figure below, select the monitoring item "Quality Rule Validation Failure" and provide filtering conditions for the restricted scope. For detailed guidelines on monitoring and alert configuration, please refer to theMonitoring and Alerting user guide document.