Connect to MindsDB for Data Analysis Based on ML and LLM
Step Overview:
- Add a MySQL type data source in the "Data Source" section of Singdata Lakehouse, and connect to MindsDB via the MySQL protocol.
- Create a new "JDBC Script" task type in Singdata Lakehouse, and select the MindsDB data source created in the first step.
- This allows you to operate and manage MindsDB using MySQL syntax in Singdata Lakehouse, and perform various predictive analyses on the data in Singdata Lakehouse through models managed by MindsDB (including traditional machine learning models and LLM).
- Similar to SQL tasks, you can directly schedule and maintain JDBC tasks periodically and achieve workflow orchestration with other tasks by setting task dependencies.
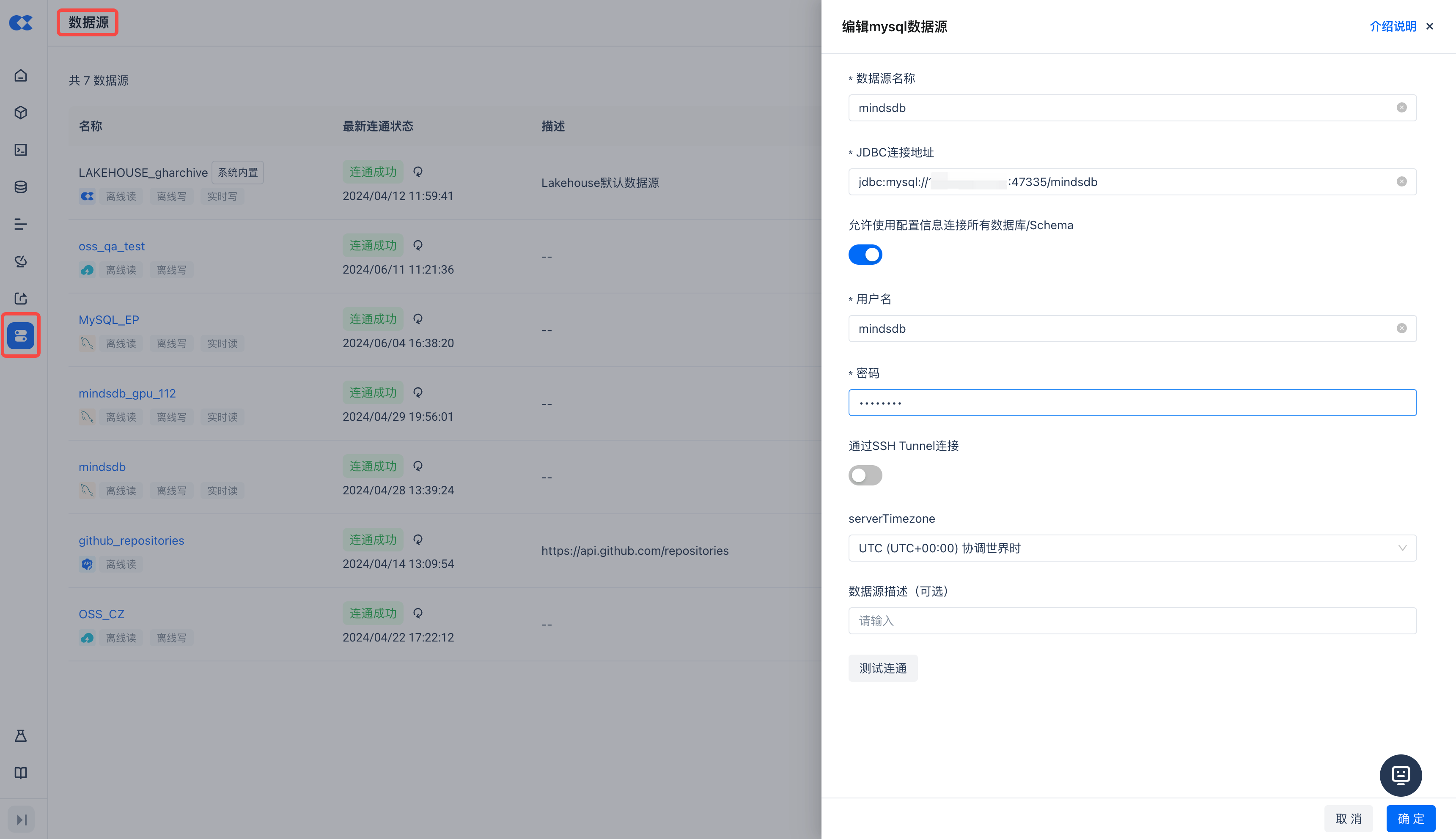
Create a New MindsDB Connection
Before creating a new connection, please ensure that your MindsDB has opened the MySQL service port 47335.
Create a New JDBC Script Task and View MindsDB Metadata
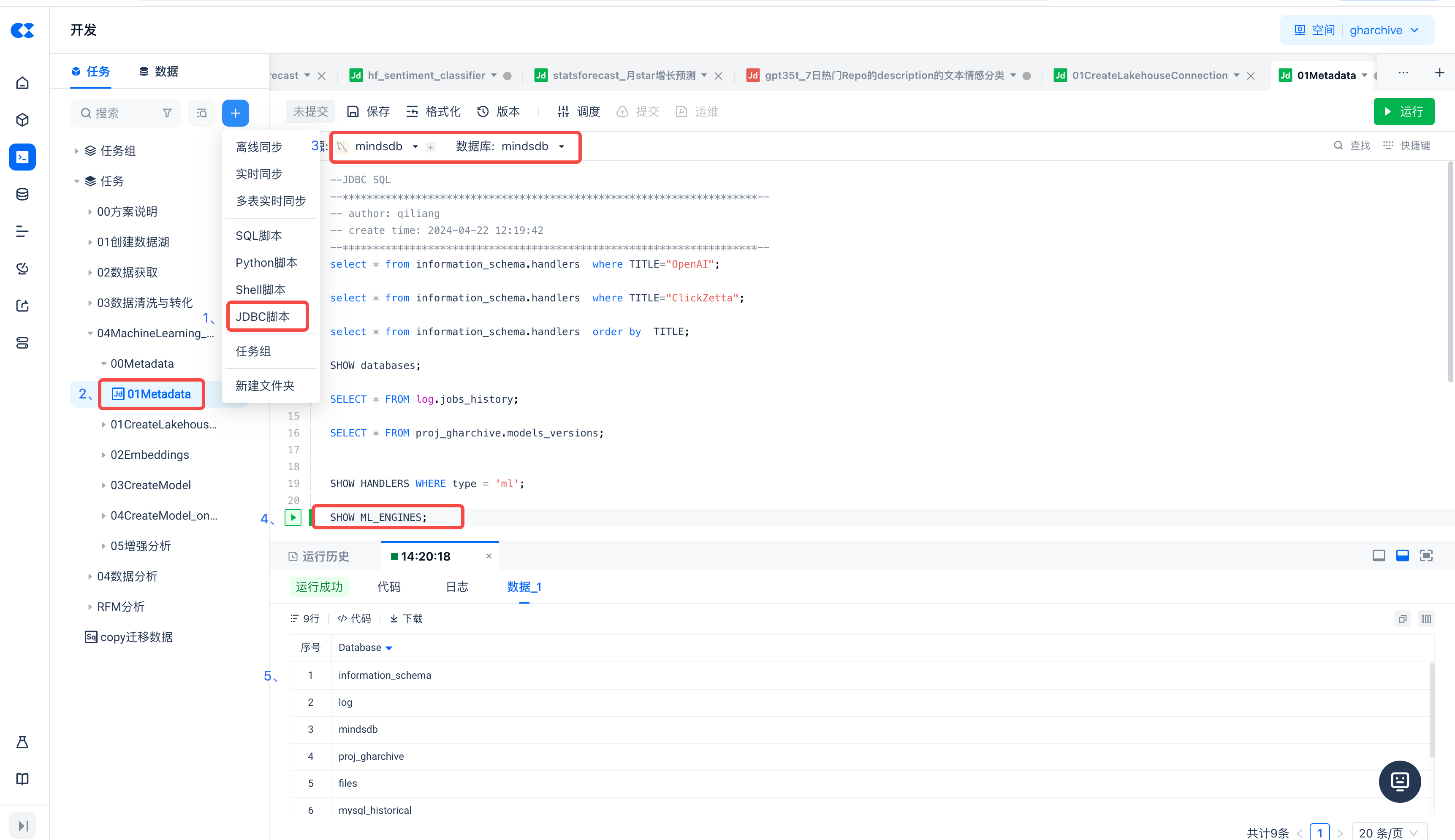
Execute the following command to view the ML ENGINES deployed in MindsDB:
List models deployed in MindsDB
Make predictions using MindsDB model
Execute the following command to make predictions using a deployed model in MindsDB:
Task Scheduling and Maintenance
Similar to SQL tasks, JDBC tasks can be scheduled and maintained on a periodic basis. You can orchestrate workflows with other tasks by configuring task dependencies.
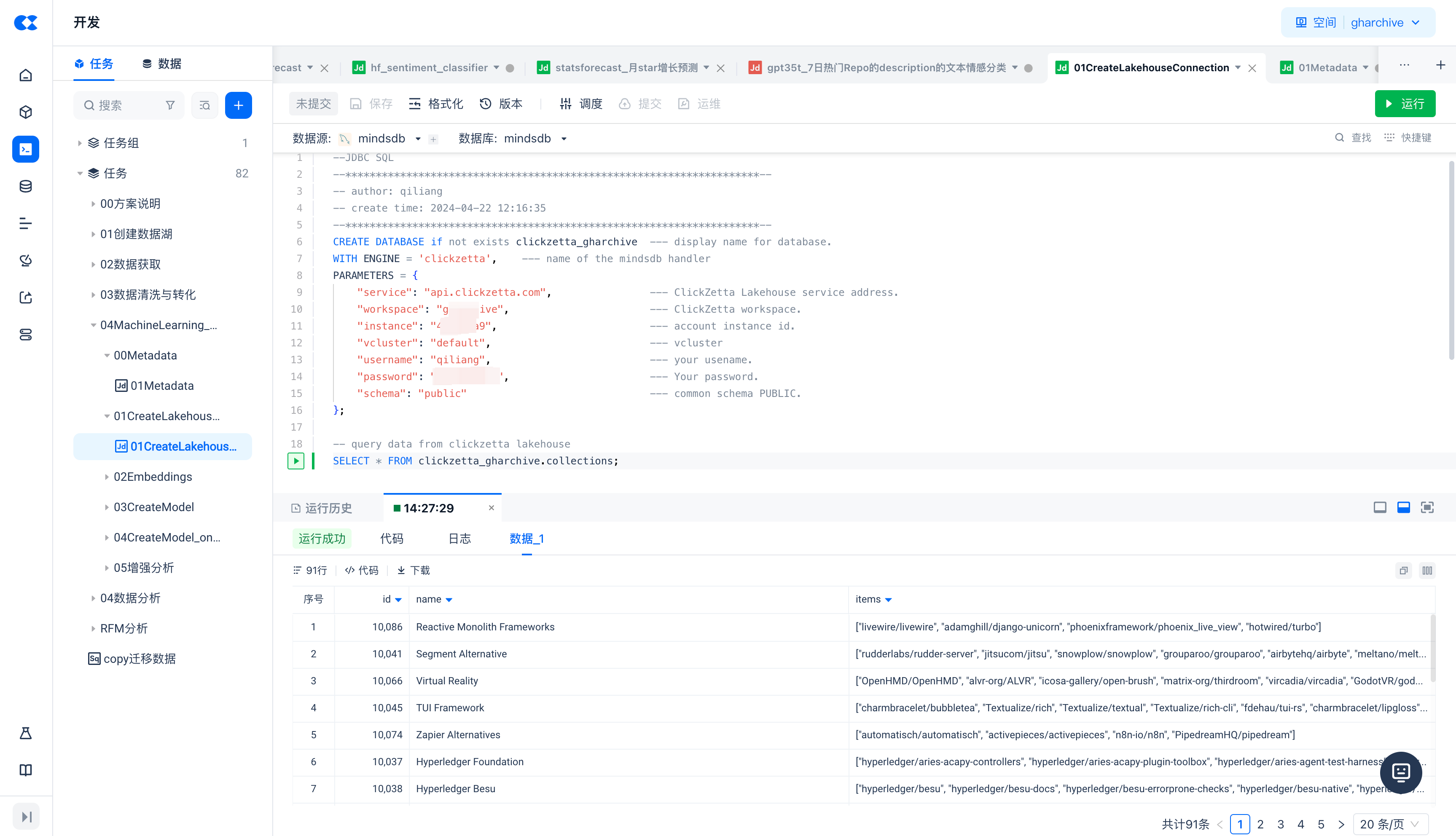
Create a new JDBC script task to connect MindsDB to Singdata Lakehouse
Create a new JDBC script task to perform sentiment classification on text data in the Lakehouse table using the Huggingface sentiment classifier model
Create a new model
By executing the DESCRIBE proj_gharchive.hf_sentiment_classifier command, you can see that the hf_sentiment_classifier model has been deployed and activated.
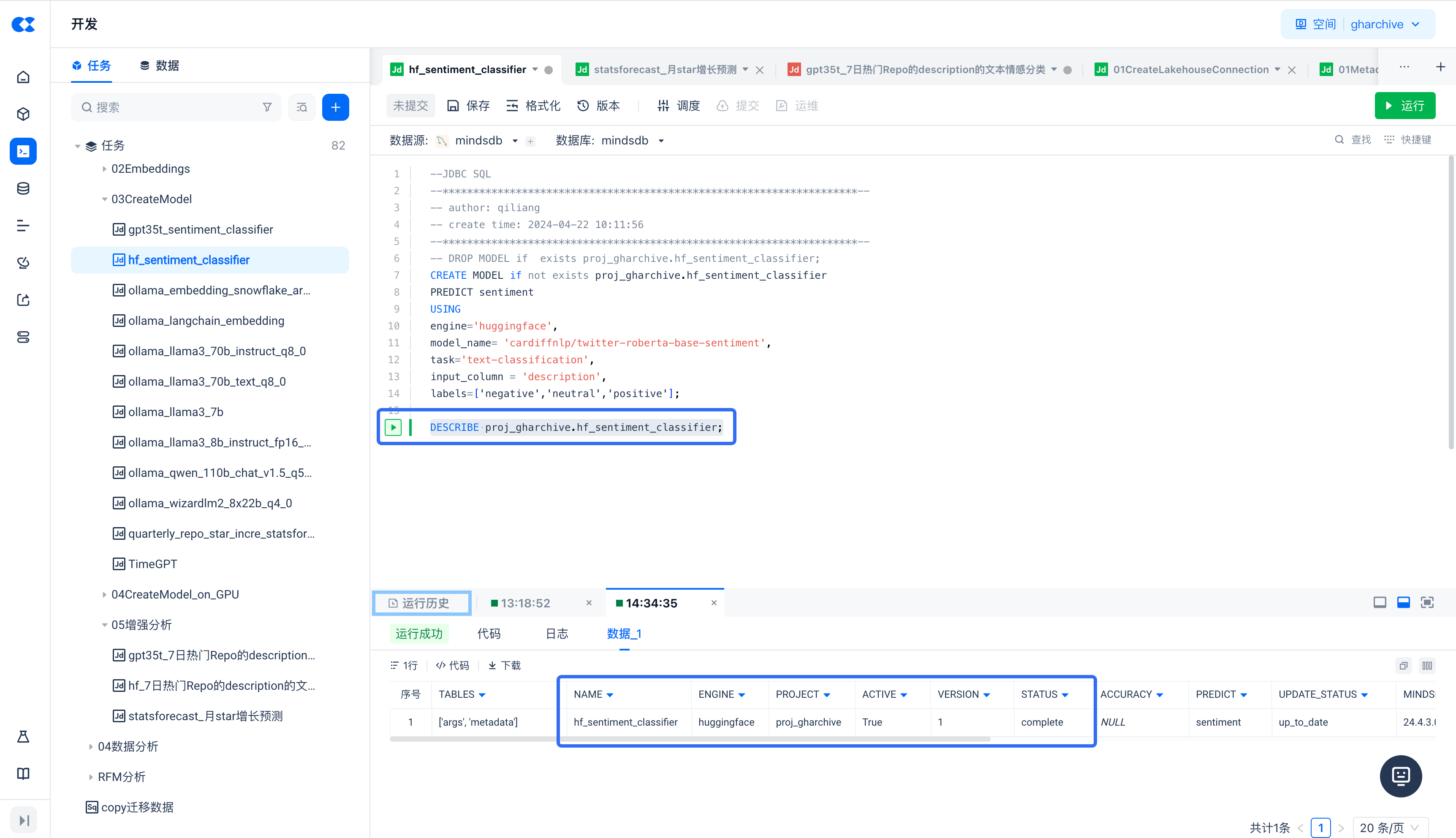
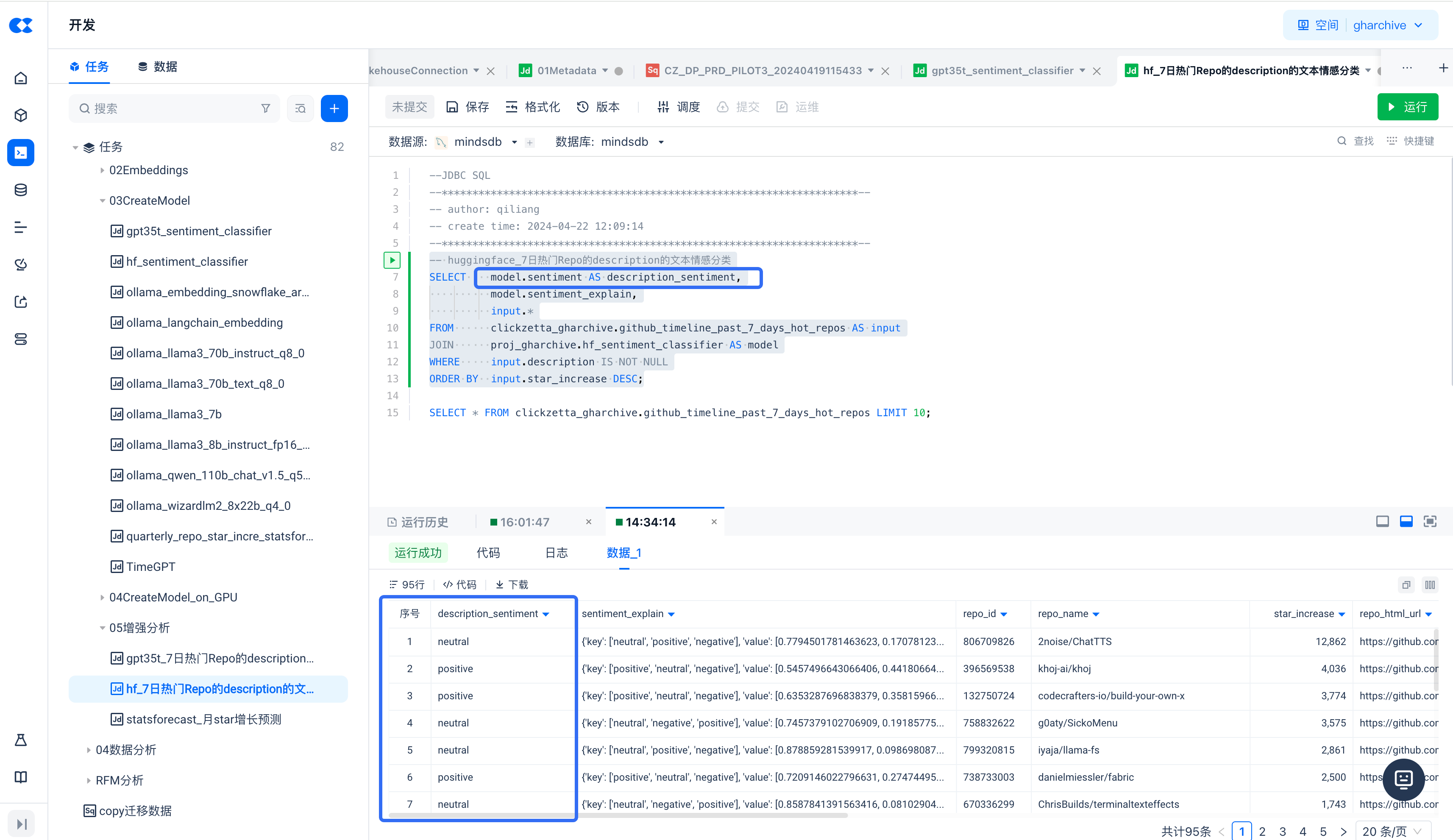
Batch Prediction (Sentiment Classification) on Data in Singdata Lakehouse
Running the above SQL, check the query result's description_sentiment field, and you can see the different classification results for the input_column = 'description' column, including neutral, positive, or negative (the labels value in the model).
Create a new JDBC script task to classify the sentiment of text data in the Lakehouse table using the OpenAI large model
In this section, we will classify the sentiment of text with the help of the OpenAI GPT-3.5 model.
Create a new model
Batch Prediction on Data in Singdata Lakehouse (Sentiment Classification)
Create a New JDBC Script Task to Forecast Lakehouse Time Series Data Using the StatsForecast Model
Create a New Model
StatsForecast provides a set of widely used univariate time series forecasting models, including ARIMA using exponential smoothing and automated modeling optimized for high performance with numba.
Batch Prediction on Data in Singdata Lakehouse
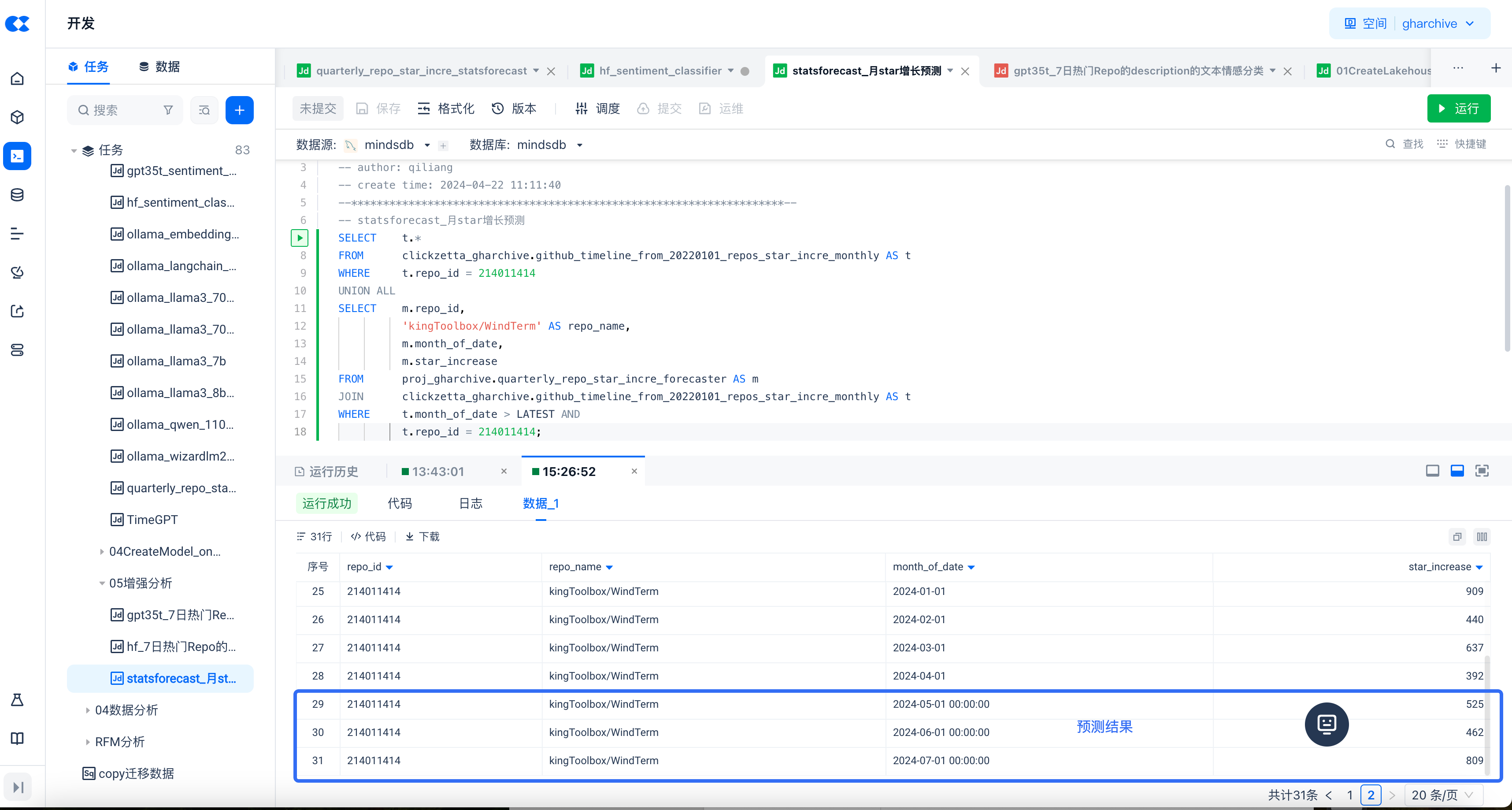
Task Scheduling and Workflow Orchestration
Similar to SQL tasks, JDBC tasks can be directly scheduled and maintained periodically. Workflow orchestration with other tasks can be achieved by setting task dependencies.