How TUNGEE Unified Offline and Real-Time Data on Singdata Lakehouse

Introduction
TUNGEE ran its sales-intelligence business on two data pipelines — one offline, one real-time — for the same logic. The result was inconsistent data, double the maintenance, and timeliness that couldn’t keep up with the business. This case study shows how TUNGEE collapsed both pipelines into one on Singdata Lakehouse, cutting resource consumption by 17x along the way.
If your team is wrestling with a Lambda architecture, you’ll find practical answers here to four problems:
- Data inconsistency caused by the gap between offline and real-time pipelines
- The high maintenance cost of running two codebases for the same business logic
- Low-cost real-time processing of large-scale, high-frequency data with complex logic
- Slow, manual investigation of data anomalies
1. About TUNGEE
TUNGEE is a pioneer in intelligent sales SaaS. Built on a knowledge graph covering 180 million+ market entities, it delivers end-to-end intelligent sales services — from lead mining and opportunity engagement to customer management and deal analytics — helping enterprises acquire precise sales leads and lower customer acquisition costs. By processing and analyzing data at massive scale, and combining large language models, NLP, and machine learning, TUNGEE turns raw market data into intelligent information services. It’s a company whose core competitiveness is data itself.
Founded in 2016, TUNGEE has earned honors including “Specialized and Innovative,” “High-Tech High-Growth Enterprise,” and “Global Unicorn,” and serves over 30,000 customers — including Alibaba, Microsoft, Amazon, and Dell.
Data processing is the core competitive advantage of TUNGEE Sales Cloud.
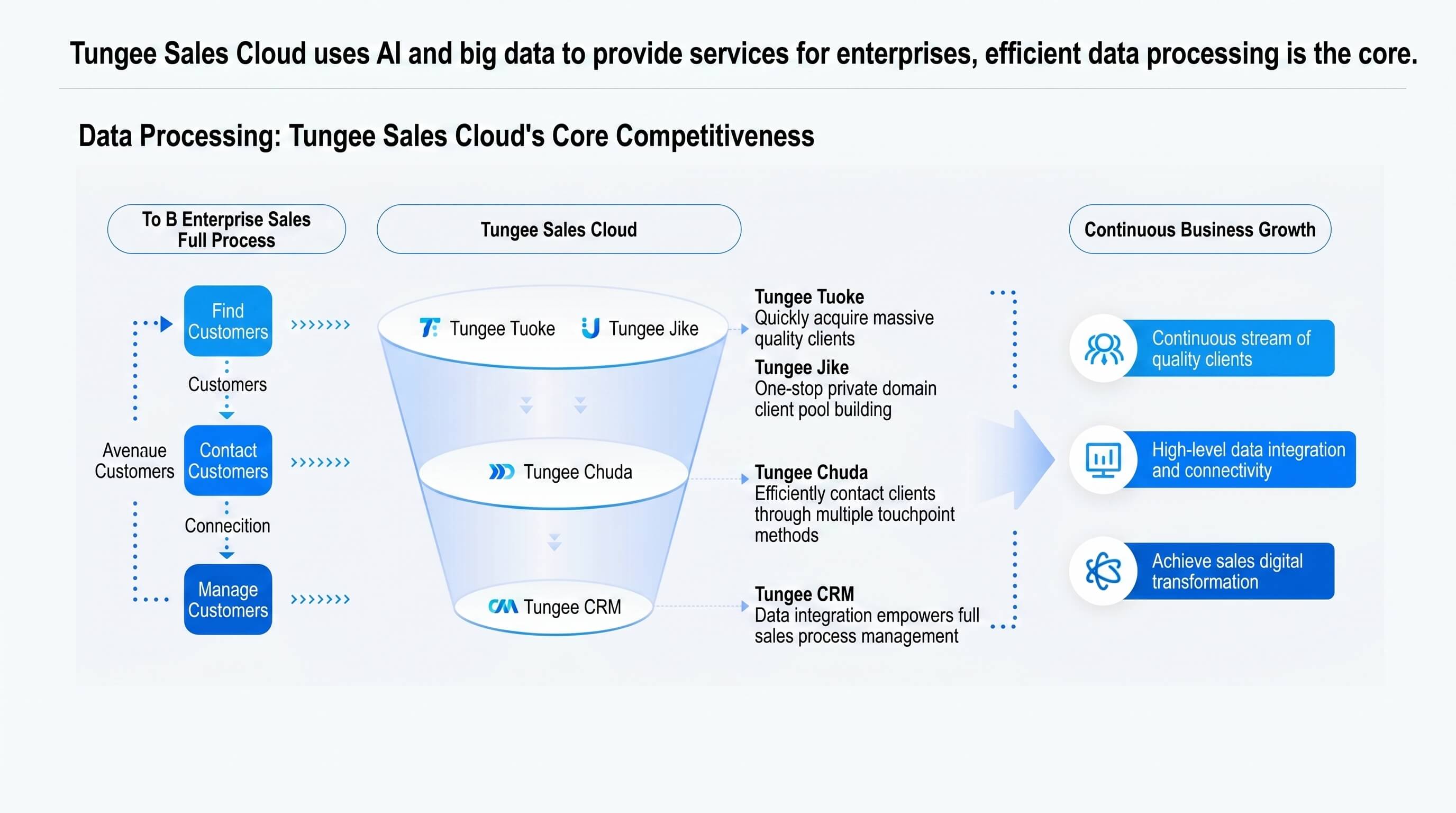
TUNGEE Sales Cloud uses AI and big data to serve enterprises — efficient data processing is the core
A data-driven intelligent sales SaaS platform.

TUNGEE data scale: 180M+ market entities, 8M+ factories, 50M+ online stores, 13M+ channels, 200M+ bid announcements
TUNGEE Sales Cloud runs on data processing at scale. Its edge comes from turning massive volumes of data into deep insights and value-added information services for enterprises.
- B2B Data as a Service: Refined processing delivers real-time, accurate information services, extracting the signals enterprises need to make informed decisions in B2B markets.
- Data timeliness is increasingly critical: In a fast-moving market, freshness wins. Customers need up-to-date data and deeply processed results to act quickly.
2. Current State Analysis
2.1 Existing Architecture
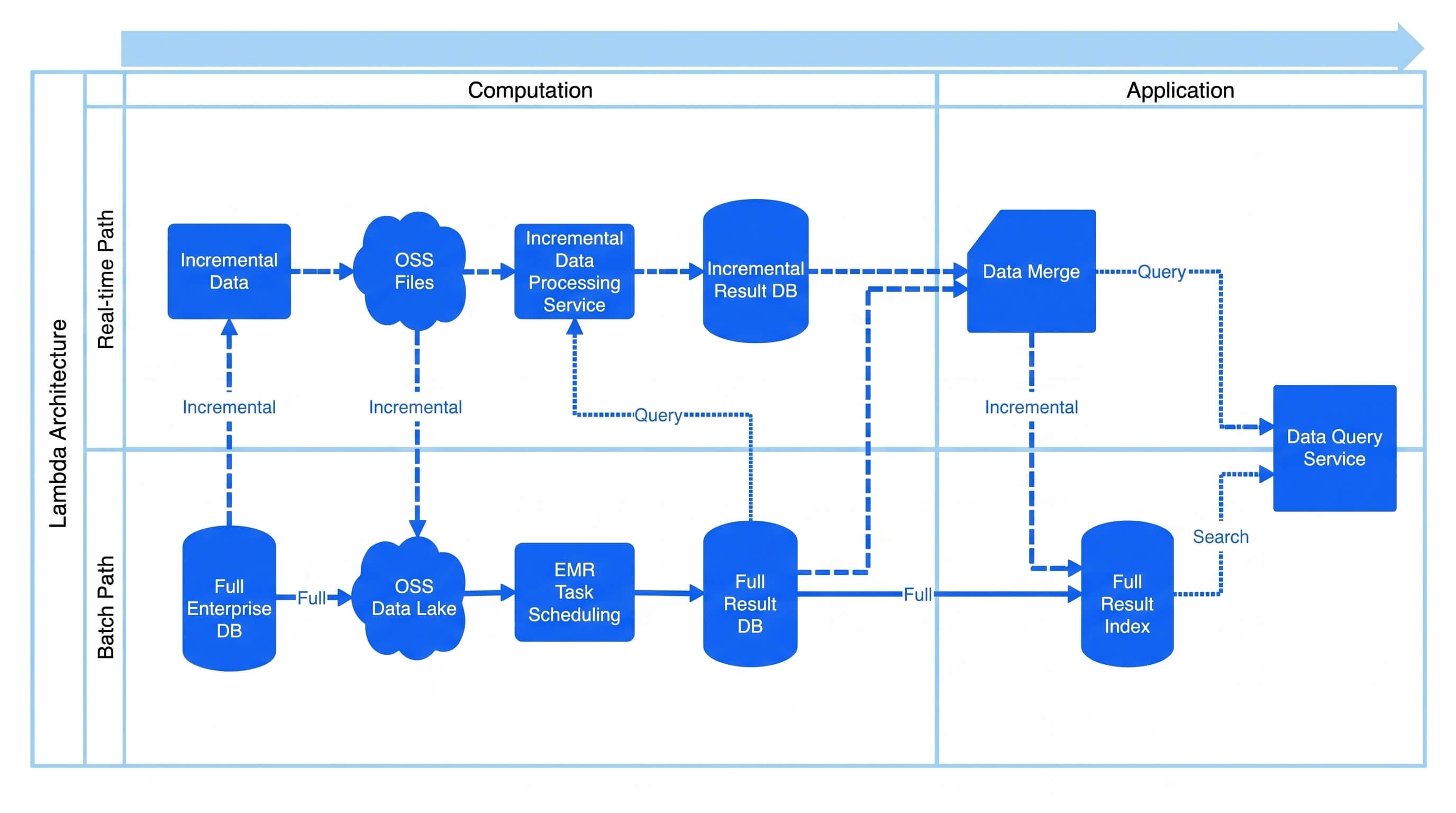
TUNGEE’s Lambda architecture: a real-time path and a batch path feeding a data merge and query service
TUNGEE’s data architecture followed a hybrid offline/real-time design (Lambda architecture):
- Offline pipeline: full data + complete logic. Full batch computation at daily/weekly/monthly granularity on Spark, implementing the complete business logic, with results stored in OSS to guarantee completeness.
- Real-time pipeline: core incremental data + simplified logic. Python-based tasks process a subset of core data with simplified logic, reaching minute-level latency.
- Idempotent partial recomputation for data issues. When anomalies occur, the affected subset is recomputed and updated in production.
- Application layer merges incremental and full data at query time.
- Real-time incremental data updates the online incremental table every few minutes.
- Offline results update the online offline table on daily/weekly/monthly cycles.
- The merged result of incremental and offline data serves production applications.
- Data is versioned. When offline data is published, version release happens via a MongoDB primary/standby switchover.
2.2 Architecture Pain Points
This architecture flexibly supported rapid early growth. But as the business scaled — data volumes grew, logic became more complex, and the bar for timeliness and quality rose — it hit clear bottlenecks:

Challenges facing TUNGEE’s big data platform as the business grows
Challenge 1: Two codebases for one business — data inconsistency.
The same logic is implemented two ways: the offline pipeline processes full data with complete logic, while the real-time pipeline processes a subset with simplified logic. Different data and different logic inevitably drift apart. Periodically refreshing offline full-batch results to production (daily, weekly, or monthly) only eases the symptom — it never eliminates it.
Challenge 2: Two codebases for one business — high maintenance cost.
The dual-pipeline setup carries its own ops model, development model, and usage model, driving up operational and learning costs. Incremental merging, offline publishing, and the related glue work add up.
Challenge 3: Partial real-time — not enough for the business.
TUNGEE’s workloads involve high-frequency updates of large-scale data with complex logic. Converting all data and all logic to real-time on the old stack would have been prohibitively expensive — so only part of the data was real-time, and that no longer kept pace with growth.
Challenge 4: Slow anomaly investigation.
Data quality management leaned on manual, experience-driven investigation: slow to locate issues, slow to resolve them, and with no effective lifecycle management of data.
2.3 Transformation Goals
After working through these pain points, TUNGEE set four goals for the technical transformation:
- Goal 1: Merge two codebases into one — cut maintenance cost and resolve data inconsistency.
- Goal 2: Move from partial-data, partial-logic real-time to full-data, complete-logic real-time.
- Goal 3: Keep total cost controllable after timeliness improves.
- Goal 4: Replace manual investigation with productized tooling.
With these goals set, TUNGEE evaluated many products on the market — none met the bar:
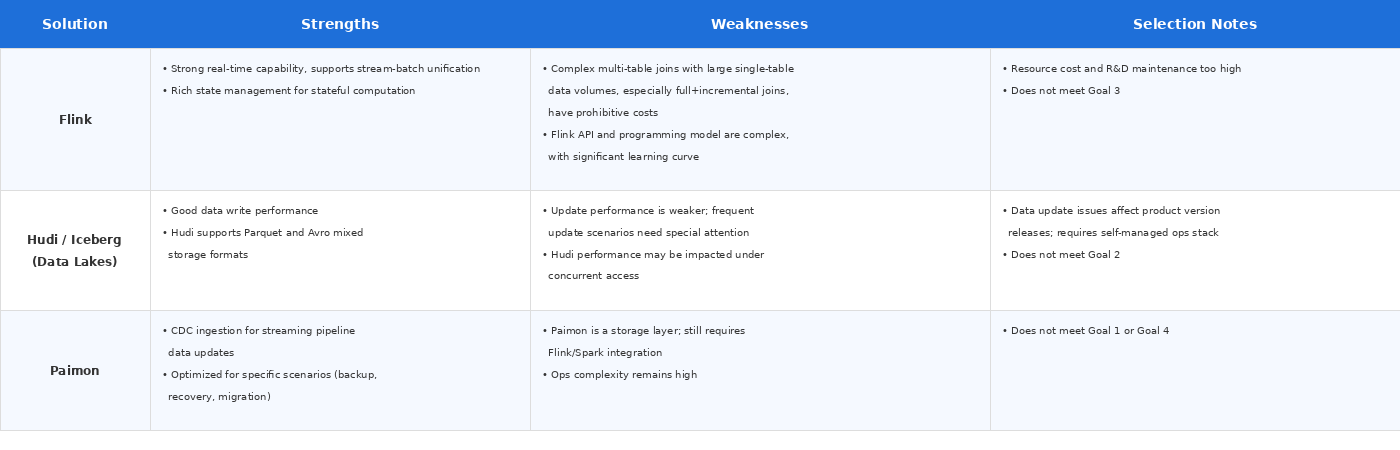
Evaluation of Flink, Hudi/Iceberg, and Paimon against TUNGEE’s selection criteria
The search ran for over a year without a fit — until TUNGEE attended Singdata’s product launch and learned about incremental computation. Singdata was building a stream-batch unification solution on incremental computation, aligned with TUNGEE’s own direction. After the launch, TUNGEE ran a POC, validated the results, and migrated a complete pipeline to production.
3. The Singdata Lakehouse Solution
3.1 New Architecture
The solution, at a glance:
- Upgrade the offline + real-time Lambda architecture to a stream-batch unified Kappa architecture.
- Replace Spark + OSS + Python + EMR + scheduling systems with the Singdata Lakehouse unified platform.
- Process the entire pipeline in real time using Singdata Lakehouse incremental computation.
- Export results in real time to business systems as complete data — no merging required.
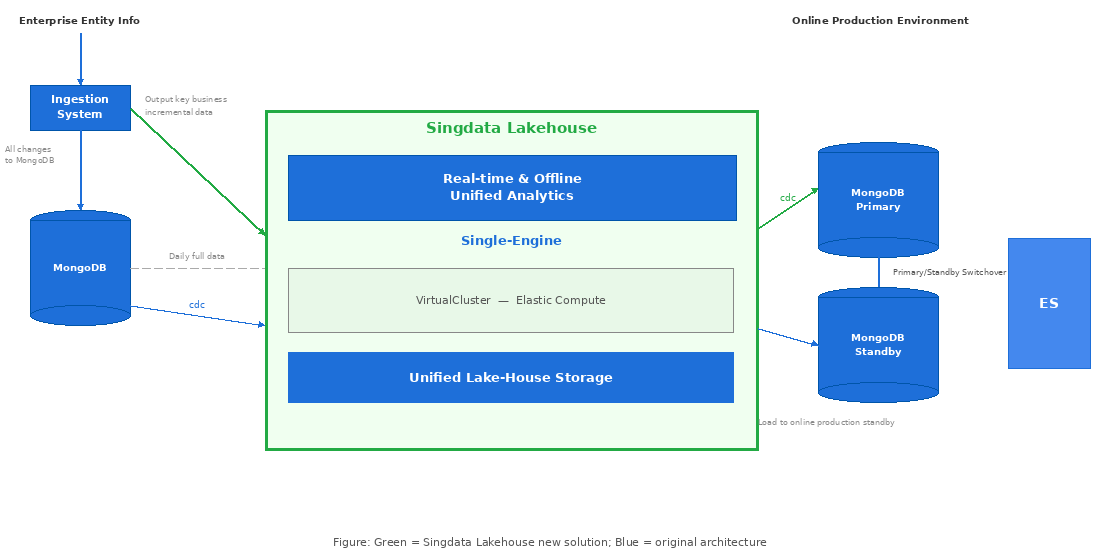
New architecture: Singdata Lakehouse (green) replaces the original Spark/OSS/EMR stack (blue)
Singdata Lakehouse is a next-generation lakehouse platform built on a Single-Engine philosophy, unifying batch, streaming, and interactive analytics in one engine. It handles both structured data processing and AI capabilities for unstructured data. Four capabilities did the heavy lifting in the TUNGEE migration:
Capability 1: Code-level unification of offline and real-time pipelines via Dynamic Tables.
- Dynamic Tables (with incremental computation) remove the need to maintain two implementations of the same logic. The complete offline logic becomes a single set of incremental computation tasks that satisfy both timeliness and completeness.
- Incremental computation supports complex join analysis and partition-level task logic. Incremental tables support full or incremental updates and async refresh at partition granularity, and historical partitions can be written back via DML — which greatly simplifies migration and development.
- The general-purpose incremental processing mode offers the broadest operator coverage, so complex logic — multi-stream joins, UDFs, window functions — can be incrementalized.
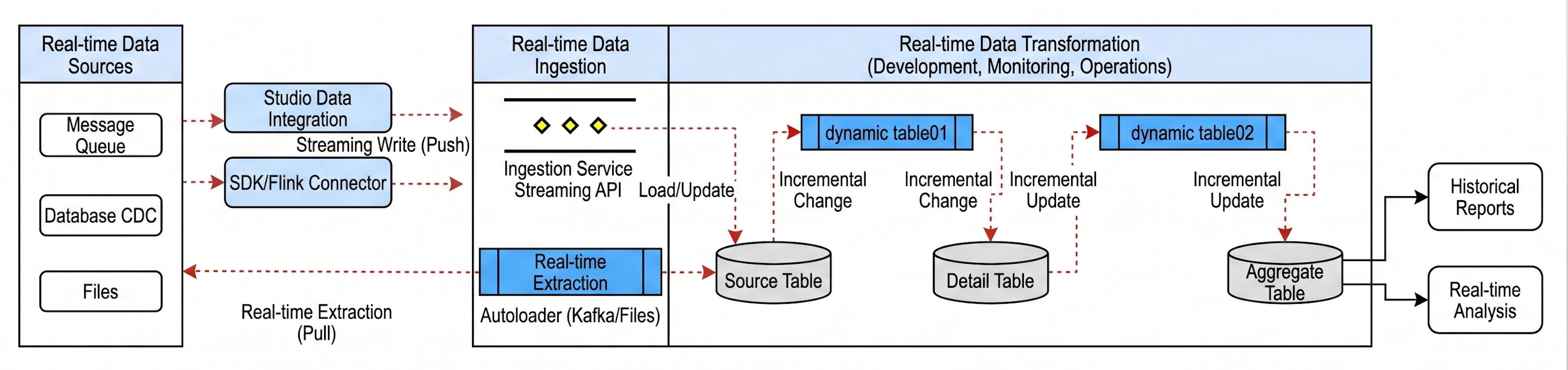
Real-time data transformation pipeline built on Dynamic Tables in Singdata Lakehouse
Capability 2: Low-cost real-time processing.
Incremental computation, top-tier engine performance, and elastic resources together deliver real-time processing across every data domain while sharply cutting compute cost.
Capability 3: A lean balance between freshness and cost.
Incremental computation tasks let you tune data freshness to the business — no code changes, just adjust the scheduling interval. Lower the freshness, and cost drops in proportion.
Capability 4: Productized anomaly investigation and recovery.
- Singdata Lakehouse Time Travel gives access to data at any point within a time window — including updated or deleted rows — and can recover dropped or expired tables. Historical versions are easy to view and restore:
- View version history:
DESCRIBE HISTORY <table> - One-click rollback:
RESTORE TABLE <table> TO <time_travel_version> - Access delta data:
table_changes
Example: As shown below, when an error surfaces in c5, these capabilities trace the full error chain back to its origin at a3, then retrieve a3’s delta data to repair it.
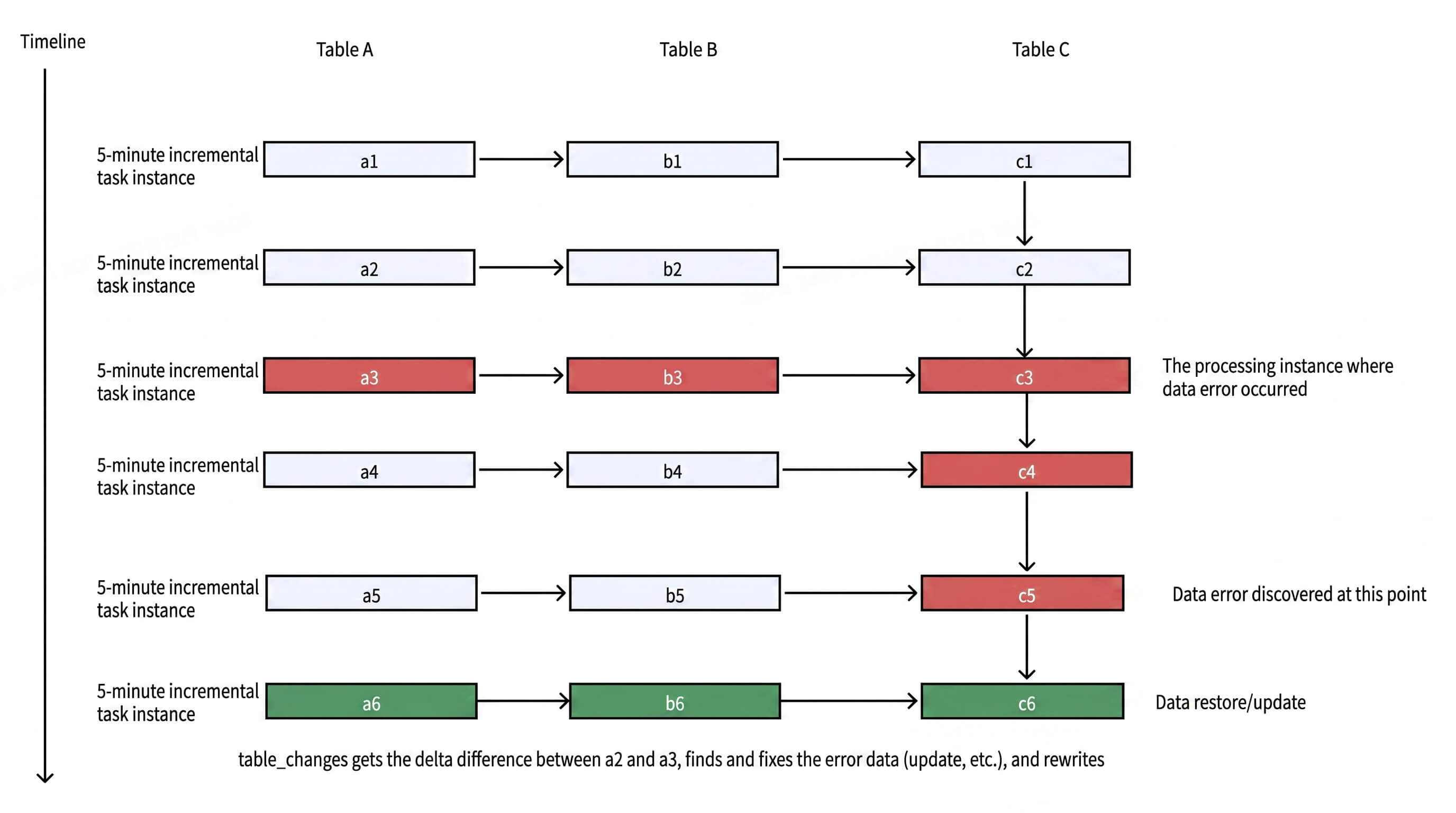
Time Travel traces a data error from c5 back to its root at a3 for targeted repair
4. Results After the Upgrade
4.1 Migration Results at a Glance
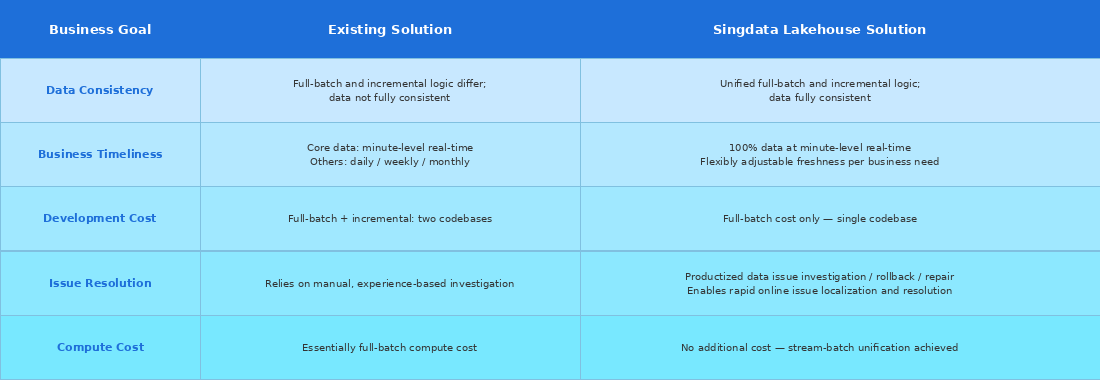
Before/after summary across data consistency, timeliness, development cost, issue resolution, and compute cost
4.2 Production Results in Detail
4.2.1 A simpler architecture — two pipelines become one.
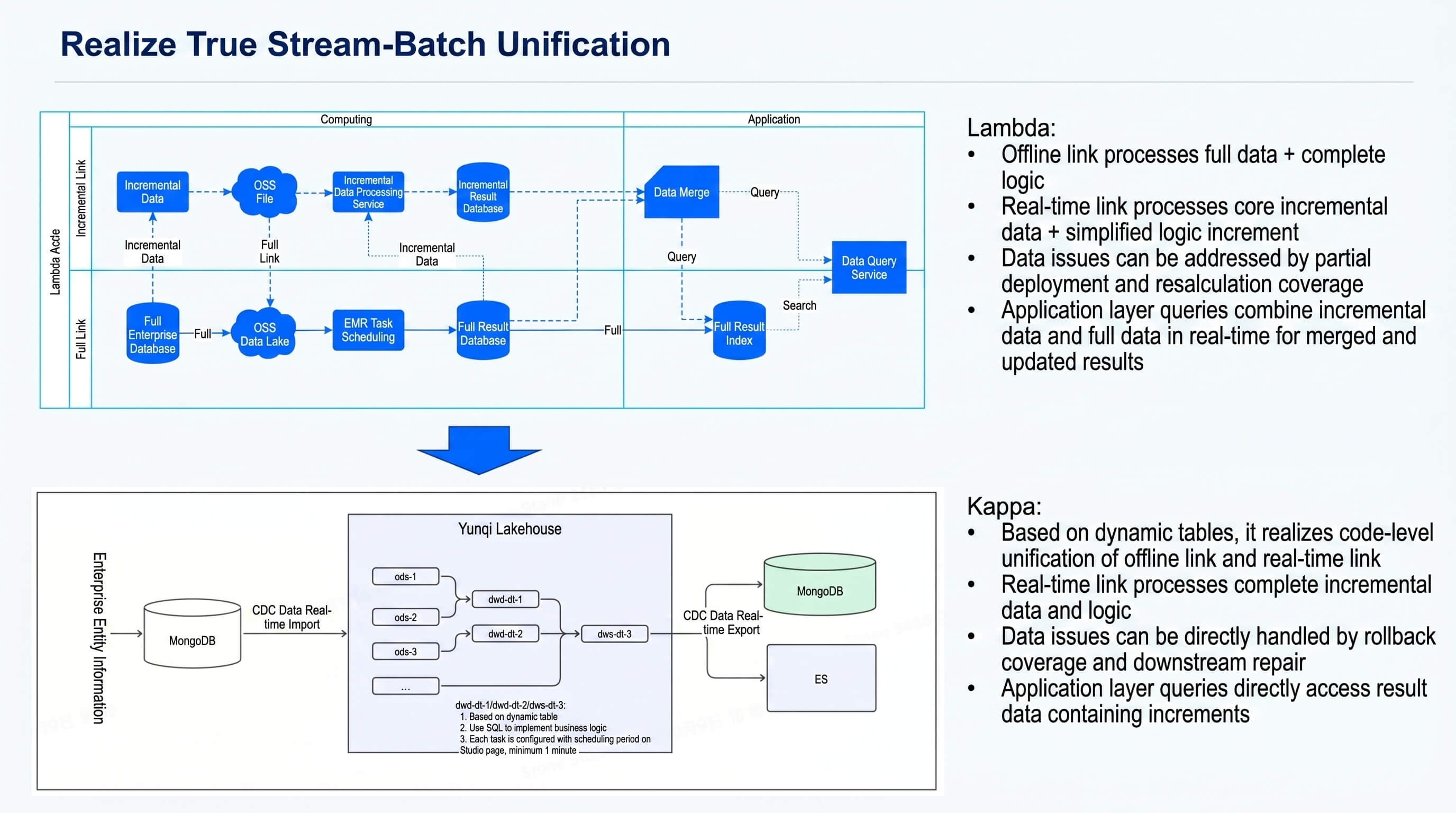
Stream-batch unification: the Lambda offline + real-time pipelines collapse into a single Kappa pipeline on Singdata Lakehouse
- The offline + real-time dual pipelines become a single real-time pipeline on Singdata Lakehouse — one codebase, processing complete data with complete logic.
- A single codebase resolves data inconsistency at the root.
- MongoDB CDC data syncs in real time to Singdata Lakehouse, which processes the incremental stream.
- Pipeline results are exported as CDC data to downstream application systems.
4.2.2 Resource consumption cut by 18x.
- Same business scenario, same input, same output:
- Singdata Lakehouse cut resource consumption by 18x, a dramatic reduction in offline full-batch compute.
- Note: 1 CRU = 8 cores, 32 GB memory, for 1 hour.
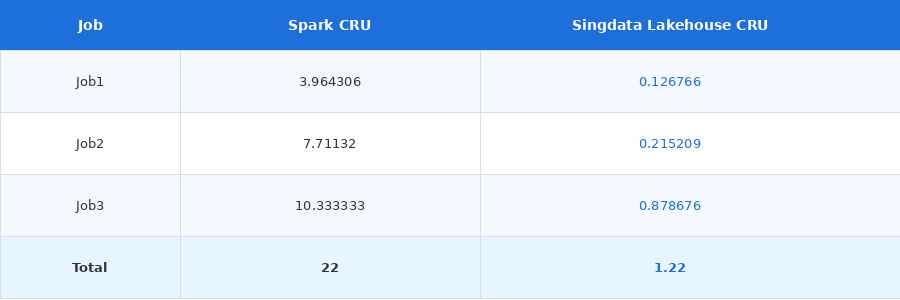
Spark vs Singdata Lakehouse compute: 22 CRU down to 1.22 CRU across three jobs
4.2.3 Data consistency and accuracy, both guaranteed.
Lossless incremental computation under complex business logic — with no simplification — supporting joins across 10+ tables, UDFs, and more. The result is a full-data, complete-logic incremental pipeline that improves timeliness while preserving accuracy.
4.2.4 A lean balance between freshness and cost.
Cost and freshness are tunable to the business. The minimum data refresh interval is 1 minute, so decisions always run on the latest data.
4.2.5 Faster investigation and one-command recovery.
- Every table change is recorded:
DESC HISTORY birds - Query data at any historical timestamp:
SELECT * FROM birds TIMESTAMP AS OF '2024-10-14 01:26:29.644' - Restore after deletion with one command:
RESTORE TABLE birds TO TIMESTAMP AS OF '2024-10-14 01:26:29.644'
Taken together, these results address TUNGEE’s core pain points. The Lambda architecture became a Kappa architecture — securing data timeliness while resolving inconsistency and removing the cost of maintaining multiple codebases — a solid foundation for TUNGEE’s continued growth.
Summary and Outlook
By rebuilding its architecture on Singdata Lakehouse, TUNGEE moved past the limits of traditional data warehouses and analytics tools for large-scale, real-time data. High performance, low-cost storage, and strong analytical capabilities give TUNGEE an efficient, reliable platform for data development, management, and analytics.
Next, TUNGEE will keep improving data timeliness and full-domain insight, and tap Singdata Lakehouse’s AI capabilities to unlock the value of unstructured data — stronger support for every enterprise decision.

Outlook: timeliness upgrades, unstructured data value mining, search cost optimization, and AI application exploration