How Shumei Technology Went from 1-Day Response to "Define-and-Query" — Big Data Platform Practice at Hundreds-of-TB Scale

📌 Introduction:
Big data platforms face a fundamental tension: the need for flexibility in defining analytical fields versus the need for performance in data processing and analysis.
Spark queries JSON with flexibility but is slow (tens of minutes); ClickHouse queries wide tables at speed (sub-second) but has a rigid, fixed schema. Every time a business team requires a new query dimension, the platform team must develop ETL pipelines, flatten JSON, and write to ClickHouse — a process that takes at least one full day.
Shumei Technology processes over 10 billion risk-control requests per day, generating 2 PB of semi-structured logs that require high-frequency ad-hoc analysis. When analysts detect anomalies, they need to drill down across multiple dimensions immediately — yet the traditional architecture stretched "second-level needs" into "day-level responses."
Starting in August 2024, we adopted Singdata Lakehouse to break through this paradox: enabling JSON semi-structured data to achieve wide-table-level query performance. The result is what we call "define-and-query" — analysts can write SQL and query directly against 500 TB of raw JSON data at sub-second speed, with no ETL and no waiting.
This article shares Shumei's technical journey:
- How we achieved sub-second queries on hundreds of terabytes of JSON semi-structured data
- How we transformed business analysts from "submit a request, wait one day" to "define and query instantly"
- How Singdata Lakehouse resolved the "flexibility vs. performance" technical dilemma
1. Business Background and Original Architecture
1.1 10 Billion Requests per Day: Data Challenges in Risk Control
Founded in 2015, Shumei Technology focuses on providing full-stack business security solutions for internet companies. Leveraging advanced AI and big data analytics, Shumei has built strong technical capabilities in content safety, anti-fraud marketing, account security, and device fingerprinting.
Today, Shumei's services cover finance, e-commerce, social media, live streaming, gaming, and more — providing risk control services to over 1,000 enterprises, including ICBC, UnionPay, Xiaohongshu, and iQIYI. Processing more than 10 billion requests per day reflects both Shumei's industry leadership and the extreme demands placed on the underlying data architecture.
1.2 Five Coexisting Systems: The Challenge of Managing 2 PB of Scattered Data
Shumei's core business depends on real-time analysis and decision-making over massive volumes of risk data. Under 2 PB of storage and hundreds of TBs of daily incremental data, the platform needed to support four critical use cases:
Use Case 1: Ad-hoc Query Analysis on Raw Detailed Logs
- Data characteristics: semi-structured JSON logs, 10+ levels of nesting, thousands of fields
- Query requirements: business analysts need multi-dimensional analysis on single tables at the hundreds-of-TB scale
- Reality: limited by Spark query performance, only platform engineers could extract data by targeting specific columns, flatten and denormalize the JSON, and write it to ClickHouse — a single request took at least 1 full day to fulfill
Use Case 2: Offline Processing and Feature Extraction
- Feature extraction via HBase
- T+1 batch offline processing with Spark
Use Case 3: AI Training Data Sampling
- Sampling from raw detailed logs
- Providing data to the AI platform for algorithm and model training
Use Case 4: Full-Text Search
- Log retrieval and data extraction via Elasticsearch
- Supporting rapid issue localization and anomaly analysis
To support these use cases, the team built a complex architecture based on the traditional Hadoop ecosystem:
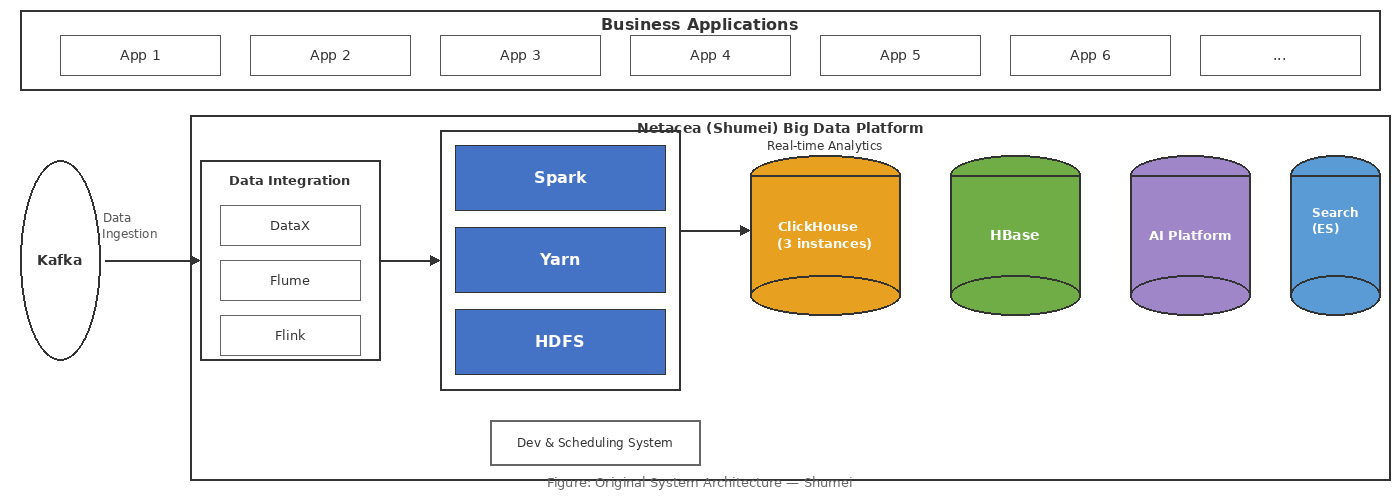
Figure: Original System Architecture — five specialized systems running in parallel: Spark for offline compute, HBase for feature extraction, ClickHouse for ad-hoc analytics, ES for log search, and an AI platform for model training.
As shown, five systems each handled their own domain: Spark for offline compute, HBase for feature extraction, ClickHouse for ad-hoc analytics, ES for log search, and the AI platform for model training. This architecture met functional requirements in the early days, but as data volumes exploded, the drawbacks became increasingly severe.
2. Architectural Conflicts and Technical Breakthrough
2.1 The Core Conflict: Flexibility vs. Performance
As data scaled from terabytes to petabytes, the traditional architecture became trapped in a fundamental dilemma between flexibility and performance.
Risk control operations require high-frequency ad-hoc analysis on raw JSON logs: query by user_id today, by device_fingerprint tomorrow — dimensions are unpredictable, with 10+ levels of nesting and thousands of fields that cannot be pre-defined. Spark's JSON queries are flexible, but scanning hundreds of TBs takes tens of minutes. ClickHouse is fast (sub-second) on wide tables, but the schema is rigid — every new field requires ETL development, creating a workflow of: submit request → flatten JSON → write to CK → analyze the next day. Flexibility meant sacrificing performance; performance meant sacrificing flexibility.
To balance this tradeoff, Shumei built five separate specialized systems. This created a cascade of secondary problems: data scattered across multiple platforms required constant context-switching; the same data was stored redundantly across all five systems; five independent clusters shared no resources, with overall utilization below 30%; and five separate technology stacks with their own monitoring made operations extremely complex. But these were all symptoms — the root cause was that no single architecture could simultaneously deliver flexibility and performance.
2.2 Redefining the Evaluation Criteria
Facing an architectural overhaul, the team crystallized a core requirement: the platform must enable JSON semi-structured data to deliver both flexibility and performance simultaneously.
The traditional selection approach of "split by function" could not meet the business need of "flexible AND fast." The new platform had to deliver:
- Flexibility: analysts query directly on raw JSON logs, with no need to pre-define schemas or develop ETL pipelines
- High performance: sub-second query performance on a single 500 TB JSON table, on par with ClickHouse wide tables
- Reduced complexity: support more use cases while eliminating data redundancy and operational overhead from multi-system architectures
Additional considerations included: simplified operations (fully managed service) and global expansion support (multi-cloud deployment capability).
2.3 Singdata Lakehouse: The Technical Breakthrough
After POC validation, Singdata Lakehouse's core capabilities delivered the breakthrough:
Key Technologies: Native JSON Optimization + Generated Columns + Automatic Indexing
- Singdata Lakehouse supports native JSON-typed fields with deep optimizations at the storage and compute layers
- Flexible generated columns can be custom-defined on nested keys within JSON structures via SQL — simply append and go
- Automatic indexing on generated columns enables better data pruning and dramatically improves performance
Result: JSON semi-structured data now delivers both flexibility and wide-table-level performance:
- JSON flexibility preserved: analysts can query any field they need, even 10 levels deep, directly
- Wide-table performance achieved: automatic indexing brings query response times to sub-second levels
This means analysts can define a SQL query and get results directly from raw JSON in seconds — no "submit request → wait for ETL → query the next day." Platform engineers no longer need to build custom ETL for every request. This is true "define-and-query."
Other Key Capabilities:
- Unified architecture: compute-storage separation with a single copy of data supporting offline processing, real-time analytics, full-text search, and more — eliminating data redundancy and resource silos.
- Enterprise-grade features: fully managed service reduces operational complexity; 7×24 support ensures stability; complete task management, data lineage, and access control meet enterprise requirements.
2.4 Upgrade Goals
Based on Singdata Lakehouse's capabilities, the team set clear targets:
- Core technical breakthrough: enable analysts to run sub-second queries directly on 500 TB of raw JSON logs — achieving "define-and-query"
- Business value: reduce request response time from 1 day to seconds; enable self-service analytics for business users
- Architecture goal: replace Spark + ClickHouse + ES with a single platform; progressively consolidate HBase and AI platform data
- Cost goal: reduce overall storage + compute cost by 50%+ (a downstream benefit of unified architecture)
3. Validated in Production: Cost Halved, Performance Doubled
After a 3-month POC (August–September 2024) and phased rollout, Singdata Lakehouse is running stably in production and all targets have been validated.
3.1 From "Five Systems" to a Unified Platform: The Architecture Evolution
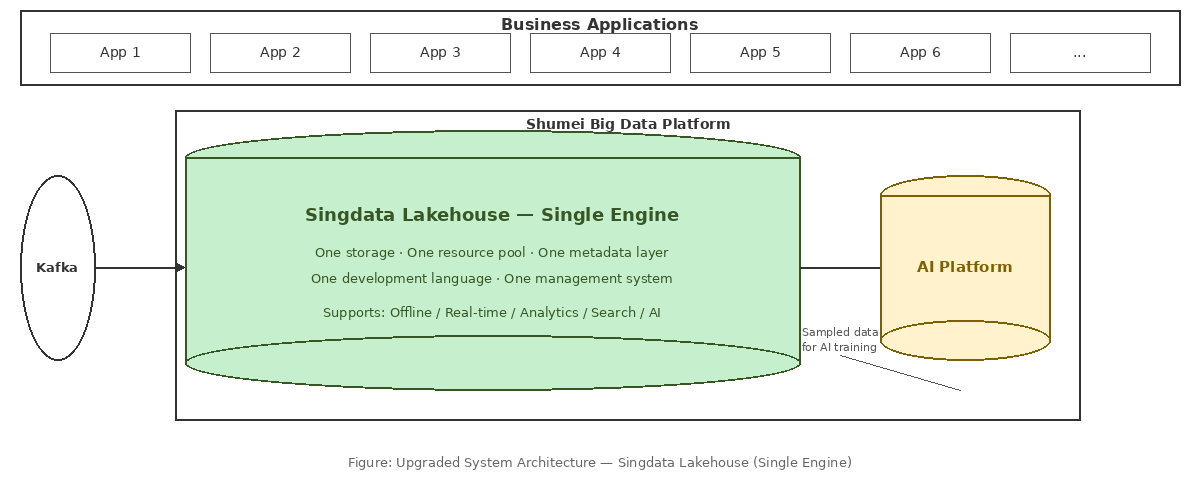
Figure: Upgraded System Architecture — Singdata Lakehouse (Single Engine) replaces the five-system stack. One storage layer, one resource pool, one metadata layer, one development language, one management system — supporting offline, real-time, analytics, search, and AI use cases.
The upgraded architecture delivered fundamental transformation:
| Dimension | Before | After |
|---|---|---|
| Storage | Separate copies in Spark HDFS, HBase, ClickHouse, and ES | Unified storage in Singdata Lakehouse |
| Compute | 5 isolated clusters, no resource sharing | Unified resource pool with elastic scheduling |
| Data Analysis | Analyst submits request → platform extracts data → next-day analysis | Analysts run self-service queries directly |
| Platform Team Role | Constantly fielding data extraction requests | Focused on platform capability development |
Core value of unification:
- Data stored once, supporting offline processing, real-time analytics, full-text search, point lookups, and more
- Business users complete all analytical work within a single platform — no cross-system context switching
- Platform team shifts from "request fulfillment" to "platform development," unlocking greater value
3.2 Storage Down 68%, Compute Down 66%: The Cost Optimization Deep Dive
Overall cost improvement:
Overall storage + compute costs reduced by 50%, broken down as:
- Storage costs: total storage footprint reduced by 68% (100 TB → ~32 TB)
- Offline processing compute: compute resources reduced by 66%
- Real-time analytics compute: compute resources reduced by 30%
Technical breakdown:
| Area | Contributing Factors | Details |
|---|---|---|
| Storage | Unified platform eliminates redundant copies across offline/real-time/analytics/search; higher compression ratio; compute-storage separation enables independent scaling | HDFS ×2 + CK ×1 → Singdata Lakehouse ×1; HDFS ×2 + ES ×1 → Singdata Lakehouse ×1; overall storage footprint reduced ~68% (down to 32% of original); ~20–30% additional size reduction vs. HDFS single copy compression; stored on COS for unlimited independent scaling; native tiered storage on object storage — no data migration required |
| Compute | Next-generation vectorized incremental compute engine delivers higher performance per resource unit; compute-storage separation eliminates over-provisioning | 3× performance improvement vs. open-source Spark in Shumei's workloads; ~30% query performance improvement vs. ClickHouse, with larger gains on complex joins; compute resources can scale independently, eliminating the waste of coupled scaling in shared-storage architectures |
| Operations | Fully managed service — users focus only on their business logic | Dedicated fully managed deployment for Shumei; all infrastructure operations handled by Singdata; 7×24 service coverage |
| Development | Unified platform reduces data import/export; single SQL language replaces multi-language stack | All data stays within Singdata Lakehouse, serving multiple use cases without export pipelines; one SQL dialect replaces Scala/Java/Python/SQL across different systems |
| Long-term Cost Reduction | Platform continuously improves performance year over year | Each year's performance optimizations enable ~30% resource growth to support ~70% business growth; ongoing storage optimization through better compression, storage strategies, and indexing |
3.3 The Paradigm Shift: "Define-and-Query" for JSON Semi-Structured Data
This is the most critical technical validation in the entire practice — enabling JSON semi-structured data to simultaneously deliver flexibility and wide-table-level performance, giving analysts "define-and-query" capability: eliminating the ETL development step and replacing it with instant, high-performance complex queries to support flexible business analysis.
Singdata Lakehouse automatically indexes nested keys within JSON-typed fields, giving semi-structured data wide-table-level query performance. Comparison:
| Approach | Flexibility | Performance | Business Workflow |
|---|---|---|---|
| Spark on JSON | ✅ Flexible (query any field) | ❌ Slow (tens of minutes) | No real-time analysis possible |
| ClickHouse Wide Table | ❌ Rigid (pre-defined schema required) | ✅ Fast (sub-second) | Submit request → ETL development → next-day query |
| Singdata Lakehouse | ✅ Flexible (raw JSON) | ✅ Fast (sub-second) | Define SQL, query instantly — no ETL |
This is not a compromise — it's a paradigm shift. Analysts define a SQL query and get results directly from raw JSON logs in seconds, without waiting for ETL development or data transformation. This truly enables the "detect anomaly → define query → immediate analysis → rapid response" agile loop.
3.3.1 Ad-hoc Query Analysis on Hundreds-of-TB JSON Logs
Test scale:
- Data volume: hundreds of TB in a single table, 1,000 production query SQLs
- Query distribution: 50% querying data within 1-day range; 50% querying 3-day to 1-month range
- Resource configuration: 16 CRU (128 Cores), 1 replica AP cluster
Performance test results:
| Scenario | Avg QPS | Avg Response Time | Median Response Time | P95 |
|---|---|---|---|---|
| Single concurrency (today's SQL : other-period SQL = 5:5) | 1 | 517 ms | 174 ms | 1,984 ms |
| Multi-concurrency (all current-day queries) | 30.8 | 254.6 ms | 119 ms | 888.8 ms |
| Multi-concurrency (today's SQL : other-period SQL = 8:1) | 18 | 410.97 ms | 192 ms | 1,370.8 ms |
Key findings:
- Median response times in the 100–200 ms range; the majority of queries achieve millisecond-level response
- P95 within 1–2 seconds, even for complex queries
- Under multi-concurrency load, the system maintains high throughput (QPS 18–30) and low latency
This means analysts running ad-hoc queries against hundreds of TBs of data get a performance experience comparable to traditional OLAP databases like ClickHouse.
3.3.2 Replacing ES: Performance Validation for Text Misclassification Analysis
Business scenario: In content moderation, auditors investigating text misclassifications need to batch-query thousands of requestIds to quickly locate false positives. The original Spark-based computation took 30+ minutes; the business team set a target of under 10 minutes.
Singdata Lakehouse performance:
| Cache State | Execution Time | Business Requirement Met? |
|---|---|---|
| Cold start (no cache) | 1.4 minutes | ✅ Well within the 10-minute target |
| Warm query (cached) | 2.8 seconds | 🚀 Sub-second response |
Analysis:
- Cold start: query time reduced from 30 minutes to 1.4 minutes — a 20× improvement, exceeding expectations
- Warm queries: direct sub-second response
- This validates that Singdata Lakehouse can fully replace ES for search use cases, with superior performance
3.3.3 Replacing ClickHouse: Full Validation of Consolidating 3 CK Instances
Migration goal: Consolidate three independent ClickHouse instances (ae/fp/main) into a single Singdata Lakehouse platform — reducing resource costs while breaking down data silos to enable cross-source join analytics.
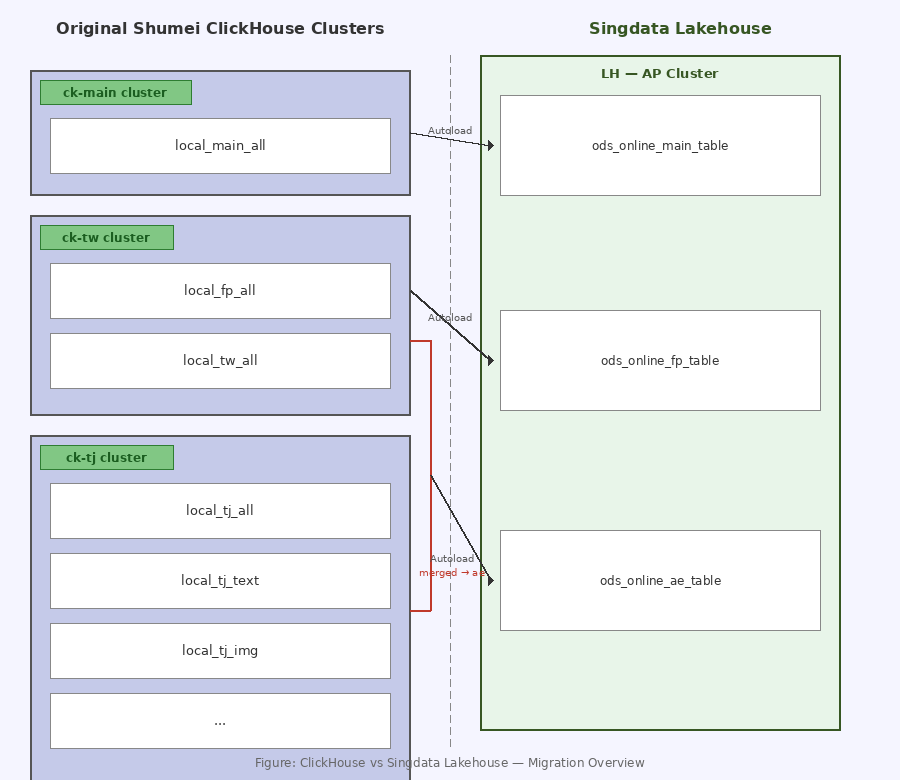
Figure: Three ClickHouse clusters (ck-main, ck-tw, ck-tj) consolidated into Singdata Lakehouse's AP Cluster via Autoload, with the ae-related tables merged into a single wide table.
Data ingestion results:
- Full historical data from ae/fp/main ingested with near-real-time ongoing sync; 30+ TB daily incremental (pre-compression)
- Data freshness: within 10 minutes
- Post-ingestion single-replica storage size reduced by 50%+
- Ingestion resource costs predictable and linearly scalable
Query performance comparison:
With 40% fewer resources compared to the largest CK cluster:
- P99 query performance across ae/fp/main data maintained at sub-second levels
- All business query requirements fully met
- Complex join queries show 30%+ performance improvement over ClickHouse
4. The Value and Lessons of a Paradigm Shift
4.1 Resolving the "Flexibility vs. Performance" Dilemma
Traditional data architectures contain a fundamental conflict: pursue flexibility and sacrifice performance (Spark on JSON), or pursue performance and sacrifice flexibility (ClickHouse wide tables). Every data platform has been forced to make tradeoffs within this constraint.
Singdata Lakehouse's technical breakthrough is that it eliminates this dilemma entirely.
By automatically indexing nested keys within JSON fields, semi-structured data gains both:
- JSON flexibility: analysts query any field they want, with no need to pre-define schema
- Wide-table performance: query response times at sub-second levels, on par with traditional OLAP databases
This isn't finding a balance between the two — it's breaking through the constraints of traditional architecture and opening up new possibilities.
4.2 Business Value: From "Day-Level Response" to "Define-and-Query"
Core value: transforming business analysts from "submit request → wait for ETL → next-day analysis" to "define-and-query instantly"
What is "define-and-query"?
- An analyst defines a SQL query and gets results directly on raw JSON in seconds
- No waiting for the platform team to develop ETL or transform data
- From "definition" to "query result" — zero waiting in between
Technical validation:
- Sub-second queries on a 500 TB JSON single table
- Replacement of Spark, ClickHouse, and ES — three separate systems
- Storage + compute costs reduced 50% (downstream benefit of unified architecture)
Business-level value:
- After detecting a risk anomaly, analysts can immediately define query logic and drill down across dimensions — response time compressed from 1 day to seconds
- Business users no longer depend on the platform team for data extraction — full self-service analytics achieved
- Platform team freed from repetitive ETL development — focused on platform capability building
4.3 Breaking Down Data Silos: Enabling Richer Business Analytics
- Cross-source join analytics enabled: three CK instances consolidated into one Singdata Lakehouse platform — scenarios that previously required querying three systems separately and manually joining results can now be done with a single SQL JOIN
- Single-source analysis enhanced: four ae-related tables merged into one, simplifying query logic while maintaining high performance and enabling complete full-dataset analysis
- Data redundancy eliminated: once ae/fp/main data is fully onboarded to Singdata, HBase/Spark batch tasks for these datasets no longer need to maintain separate copies, further reducing storage costs
4.4 10× Efficiency Improvement: Empowering Business Users as Data Analysts
- Analysis efficiency dramatically improved: business users went from "submit request → wait 1 day → receive data" to "query directly → sub-second response → immediate analysis" — over 10× efficiency improvement
- Platform team value transformation: shifted from fielding constant data extraction requests to focusing on platform capability development and technical innovation
- Deeper data value extraction: with data silos broken down, business users can perform more flexible multi-dimensional join analyses, surfacing more business insights
4.5 Key Success Factors
- Identify the core conflict: deeply analyzed specific pain points — inability to self-serve analytics, resource isolation across multiple systems, slow JSON query performance — rather than vague complaints about "the system is slow" or "costs are too high"
- Find the technical breakthrough point: used real production data in a 3-month POC to validate that Singdata Lakehouse's JSON auto-indexing capability could solve the specific problem
- Incremental validation: from ClickHouse/Spark to ES/HBase — each step validated technical feasibility using real production data
- Deep product collaboration: worked closely with the Singdata team to continuously optimize for Shumei's specific scenarios and ensure capabilities translated into production results
5. Continuous Evolution: From POC to Production, From Data to AI
Shumei's partnership with Singdata began in August 2024. After rapid POC validation (overseas POC in August, domestic POC in September) and a phased rollout, the main ClickHouse and Spark workloads have been migrated to Singdata and have been running stably for over 9 months.
Next steps:
- ES migration in progress: ES workloads are moving to production, followed by HBase-related workloads — all relevant workloads will progressively migrate to Singdata, realizing the vision of one storage layer supporting multiple use case scenarios
- Closing the AI training loop: all AI model training data originates from Singdata Lakehouse; the next phase will connect the end-to-end flow for sample extraction, storage, and management needed by the AI team — improving algorithm and model training efficiency
- Multi-cloud strategy: establishing a unified big data platform overseas to support global business expansion