Full-Pipeline Real-Time Data Practice at Kuxuan Technology: Replacing an Assembled Data Platform with Singdata Lakehouse

📌 Introduction:
Founded in 2017, Kuxuan Technology is an online enterprise education services company dedicated to advancing organizational capability through technology. Its portfolio includes a smart store operations platform and other technology innovation applications, serving 4,000+ customers across 10+ verticals including retail, food & beverage, footwear & apparel, pharmacy chains, mother & infant, supermarkets & convenience stores, automotive care, and beauty & skincare.
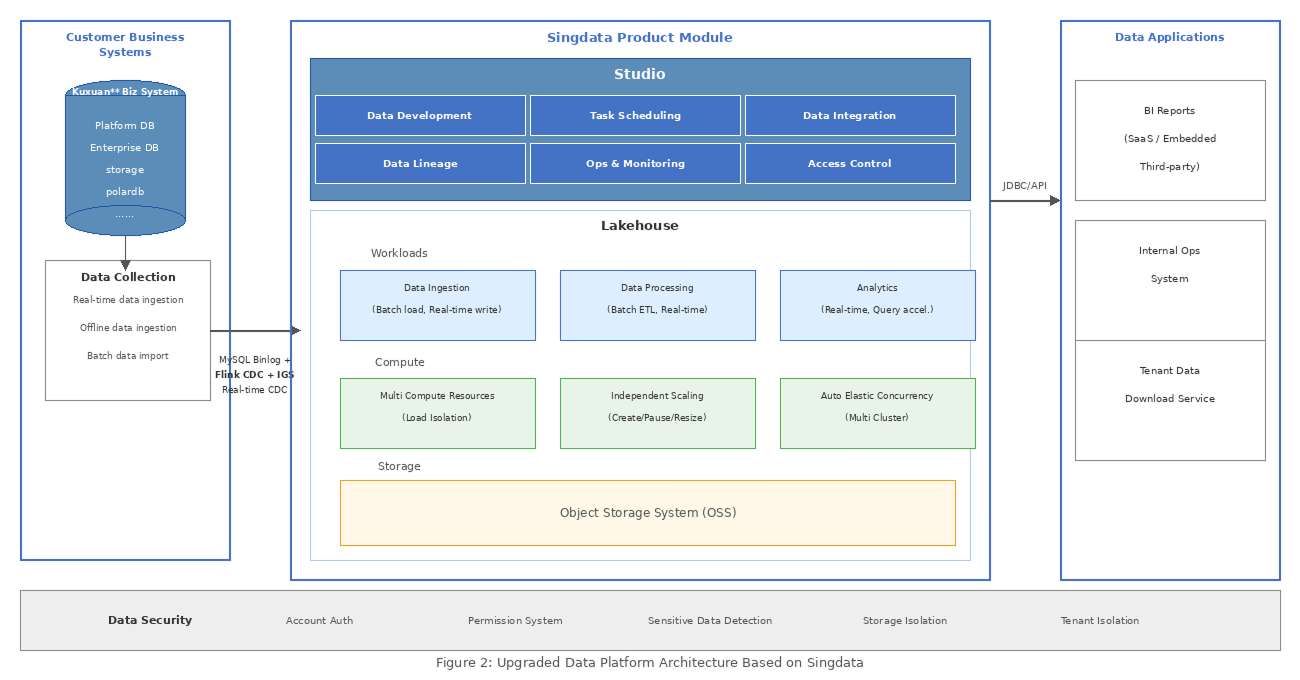
Kuxuan Technology upgraded its data infrastructure to a Single-Engine unified lakehouse platform based on Singdata Lakehouse, which has been rolled out to production across lambda architecture. The new platform delivers significant performance improvements, enabling real-time processing at the tens-of-millions-of-tables scale across all business domains. By leveraging a unified engine to eliminate redundant data, it reduces the data governance burden, and — combined with a pay-as-you-go billing model — dramatically lowers compute resource costs.
Author: Yang Jie, R&D Director, Kuxue Tech
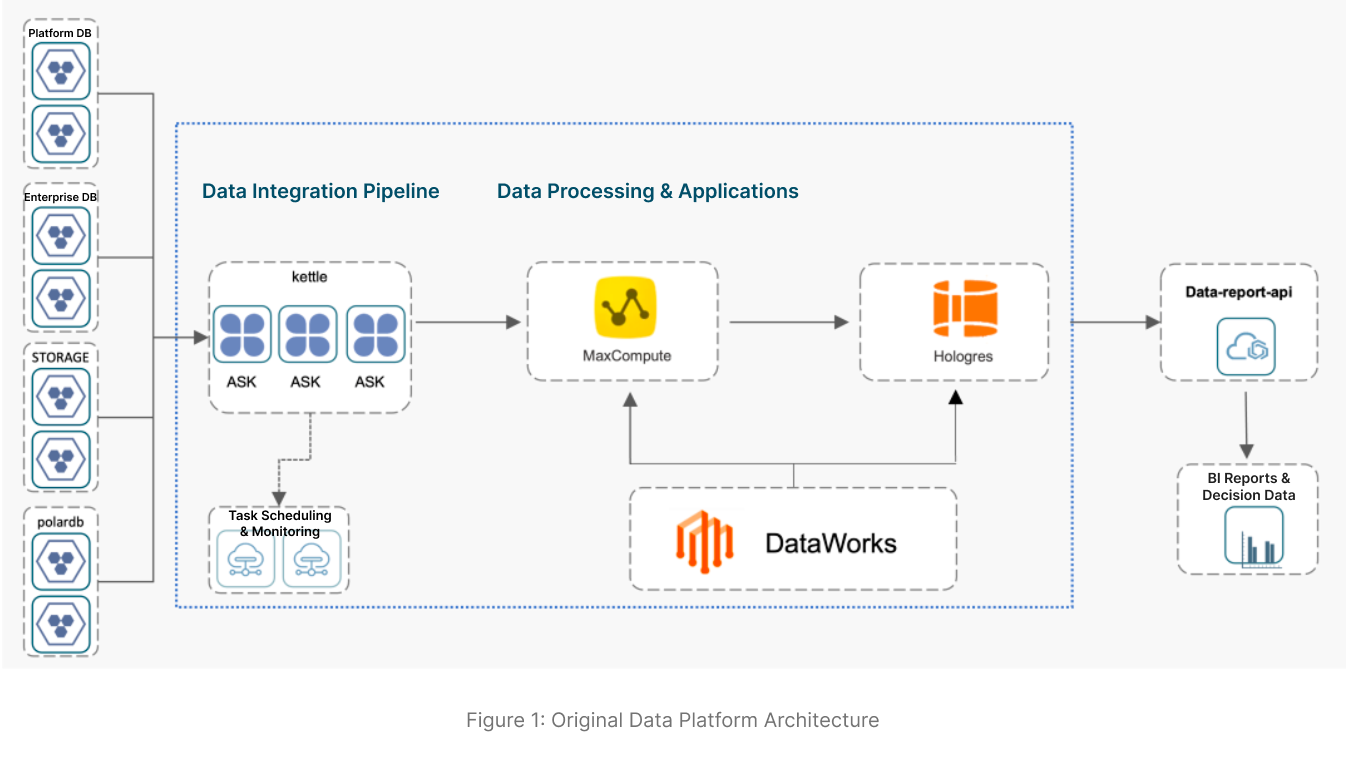
Our original data platform was built on a combination of cloud services using a standard Lambda architecture to handle business data. As the scale of enterprise customers grew, we found that the original platform could no longer meet business demands. The core challenges were:
- Customers required hourly or minute-level data. The original architecture used Kettle + MaxCompute, a data pipeline designed for large-scale offline tasks with a “T+1” refresh cycle — today’s business reports show data only through yesterday. Customers needed higher data freshness.
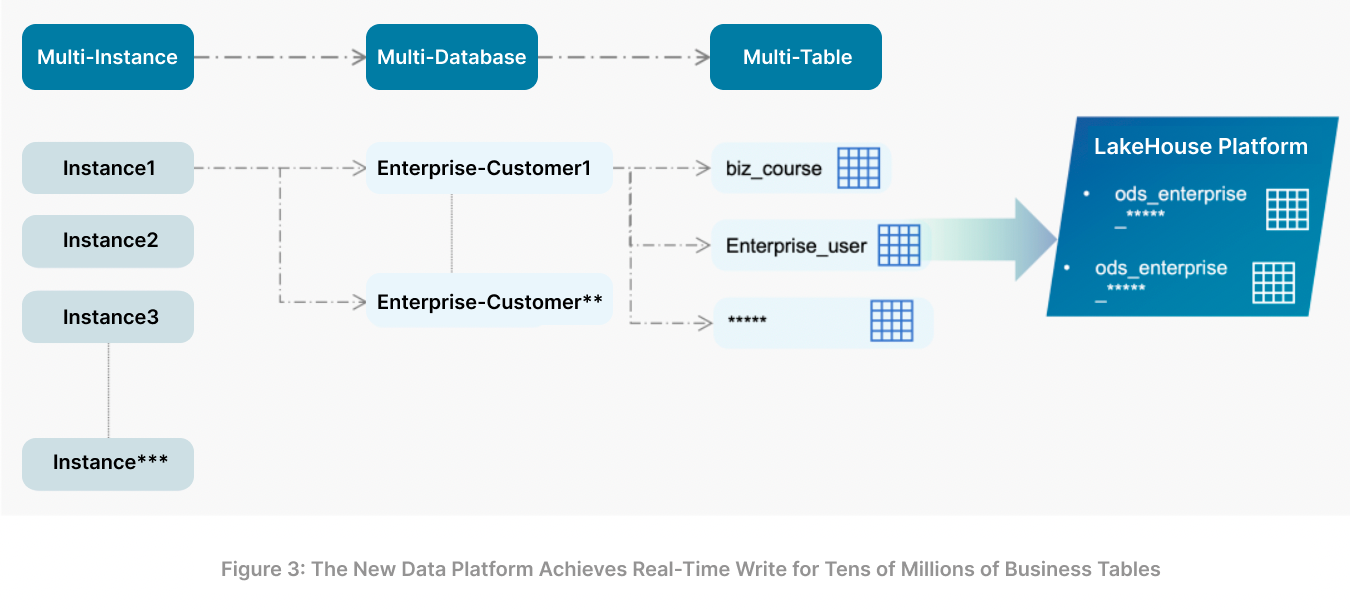
- Per-customer table sharding caused database table explosion. We provisioned a dedicated database for each customer to achieve data isolation on the business side. Each database contained thousands to tens of thousands of tables. As customer count grew and new data pipelines were developed, the total number of physical tables quickly ballooned to the tens of millions — creating significant challenges for data integration, processing, and schema evolution.
- Architecture caused data redundancy and high costs. Data was forced to be copied multiple times through the processing pipeline: data was scheduled by Kettle into MaxCompute, then moved to Hologres for an additional acceleration pass. Every independent component added a storage copy, and any change to processing logic required modifications across two or more data engines. Data governance complexity was high, with large storage and compute resource consumption.
- Peak-valley task patterns caused idle resource waste. Both our data processing windows and enterprise report query windows had pronounced peak and off-peak characteristics. Previously, we purchased annual subscriptions pre-provisioned at peak capacity, leading to significant resource waste during off-peak periods. The high costs and waste from this billing model created mounting pressure to reduce costs.
Key Requirements for This Architecture Upgrade
- Upgrade the data architecture to improve data processing timeliness;
- Reduce resource consumption while ensuring data analysis query performance and controlling compute costs;
- Reduce system personnel maintenance costs;
- Resolve the database table explosion problem.
Introducing Singdata Lakehouse to Complete the Platform Upgrade
After evaluating multiple options, we decided to adopt Singdata Lakehouse.
The selection process was not straightforward. During evaluation we considered real-time-capable products such as StarRocks and Doris, and assessed individual product capabilities — concluding that it was possible to migrate the most latency-sensitive portions of the data pipeline to real-time processing. But we also recognized that we would still need to add system components for data integration, task scheduling, data lineage, and other management functions. Each additional component adds ongoing upgrade and maintenance costs. The essence of our upgrade goal was to simplify the architecture while achieving full-domain real-time processing — and we found that assembled Lambda architecture solutions had two fundamental contradictions: real-time data freshness and cost are in tension, and functional completeness and cost are also in tension.
We therefore sought a solution with a simpler architecture that could simultaneously support unified real-time and offline processing in a fully managed model. Among products capable of such unification, global players include Snowflake and Databricks; domestically, few products support multi-cloud independence plus unified offline/real-time processing. After research, we learned that Singdata Lakehouse’s Single-Engine, built on incremental computation, could meet our unified requirements — so we engaged them for testing. After technical evaluation, PoC testing, and go-live, we validated that it met our needs.
Summary of Upgrade Results
- Real-time integration of tens-of-millions-of-tables at full scale. Cost had been our primary concern in achieving full-scale real-time integration. The new platform implements stream-batch unification through incremental computation, supporting full real-time data synchronization for tens of millions of business tables using relatively modest resources. Unlike traditional stream processing with always-on resources, incremental computation abstracts all computation into an incremental form — achieving “compute once, use many times” — saving compute resources. It also provides a flexibly adjustable “incremental interval,” enabling batch or stream processing behavior as needed.
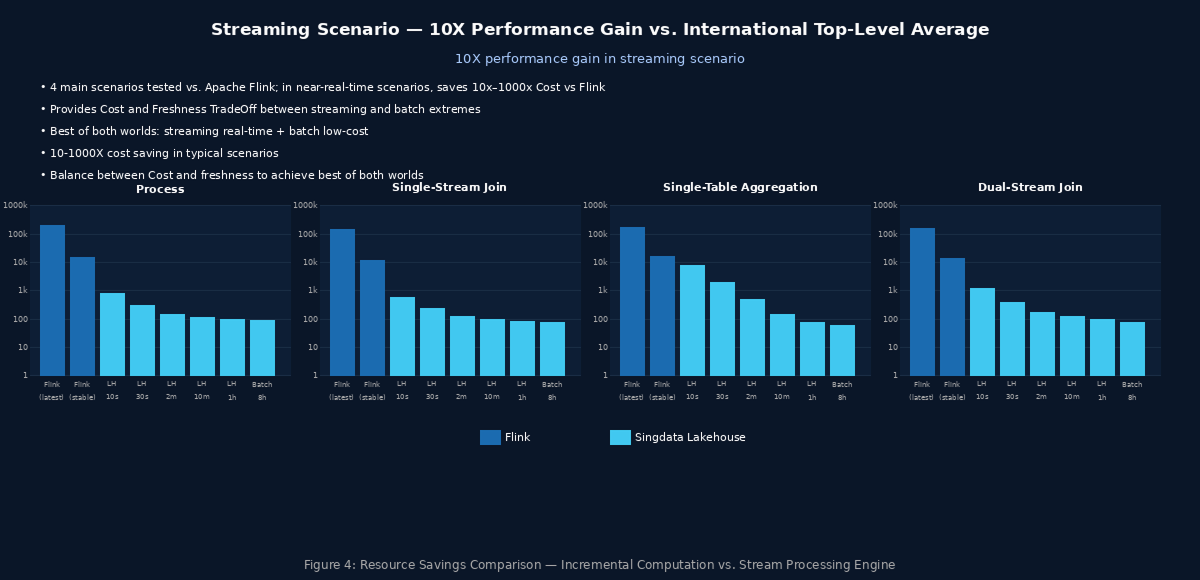
According to recent Singdata benchmarks, incremental computation achieves 10× resource savings over stream processing engines for near-real-time (hourly) scenarios. (See chart below.)
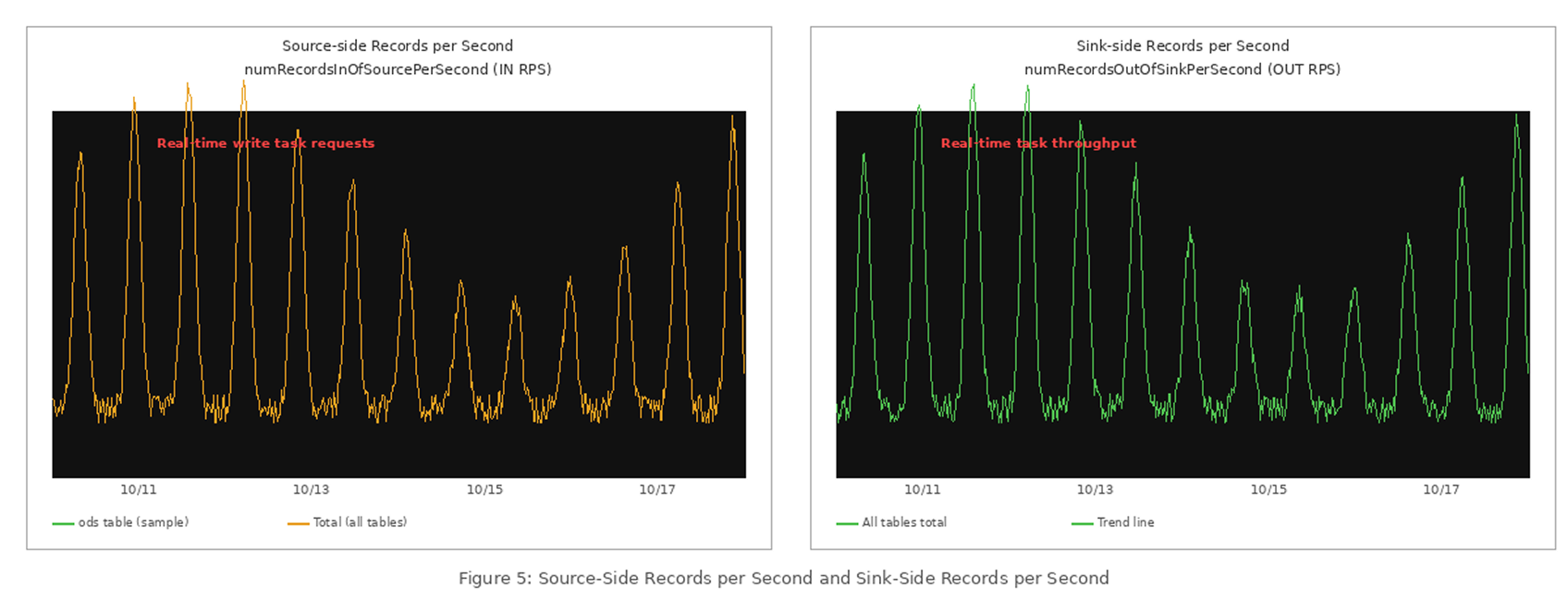
For real-time pipeline stress testing, we used production environment requirements directly: synchronizing tens of millions of business tables per-side, each with 50–100 fields, with single-table single-write batches of approximately 100 records. The source-side and sink-side per-second data throughput ran stably. Reference metrics (7-day window):
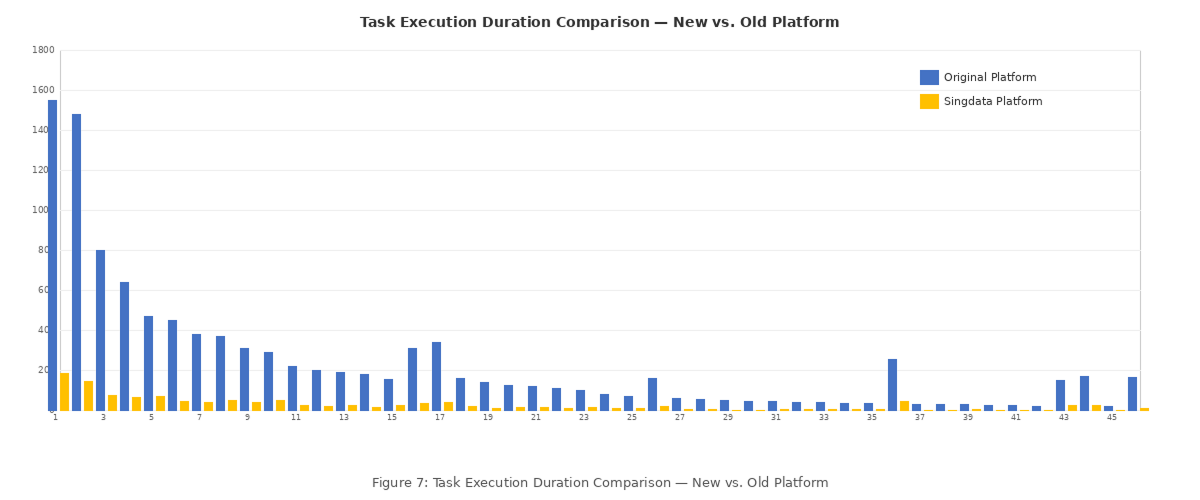
- AI4D improves data task execution performance by 2×+. Our business code uses a large number of virtual views; many identical virtual views are referenced across different queries, making manual tuning by data engineers extremely inefficient. AI4D refers to the platform autonomously learning data and workload characteristics, performing algorithm- and AI-based automatic optimization — identifying and extracting repeated computation across large volumes of tasks for reuse. This reduces compute consumption and improves data engineer productivity.

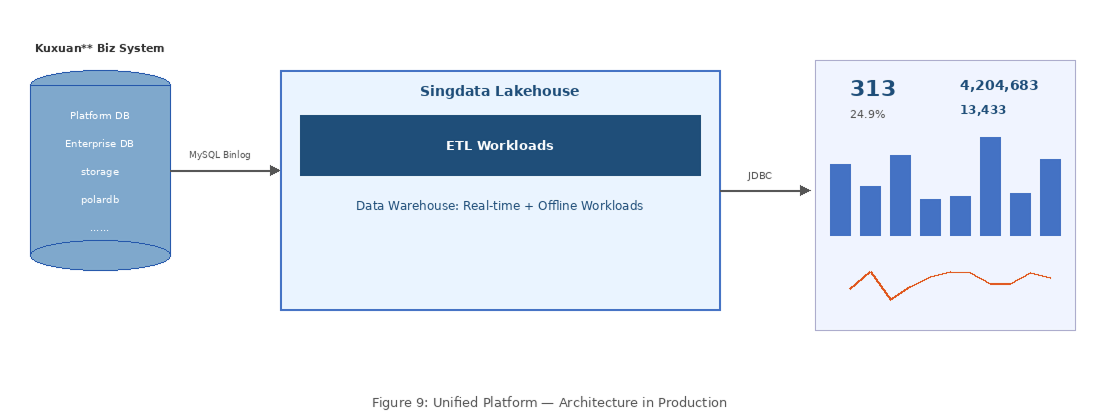
- Eliminated data redundancy — unified offline and real-time processing. The Lambda architecture’s data redundancy problem is resolved. The unified platform based on the Single-Engine philosophy makes data processing, scheduling, and operations significantly simpler. As shown below, data engineers only need to modify task code once; the ODS layer data in the warehouse stays always consistent with the business side, with no data redundancy or metric redundancy concerns. Additionally, the Single-Engine unifies offline and real-time processing — switching between the two requires only a scheduling adjustment, achieving a lean balance between data freshness and cost.

- Pay-as-you-go billing reduces compute costs by 50%. The new platform uses a usage-based billing model: the final cost is calculated based on actual consumption of compute, storage, and network resources. Compute resources are billed based on actual cluster runtime — once a compute cluster stops, billing stops. Importantly, because the new platform delivers significantly higher compute performance compared to before, the same scale of compute resources executes tasks in substantially less time — further reducing usage costs.
Business Value After the Platform Upgrade
After the new platform went live in production, we summarized the results and value delivered. Because the PoC process was thorough, production results were consistent with PoC findings. A brief summary:
- Metrics, reports, and dashboards now deliver efficient data services. Upgrading data freshness from “T+1” to “H+1” enables our customers to monitor business progress and results in a timely manner, improving product and service experience.
- The fully managed data service model allows our data team to focus on data value development and expand analytical and insights capabilities — without building or maintaining individual components. The platform’s elastic scaling and AI optimization capabilities also provide strong SLA guarantees for performance.
- We achieved our cost-reduction and efficiency-improvement upgrade goals. On one hand, the new platform’s pay-as-you-go model fundamentally resolves the idle-period resource waste of the previous approach. On the other hand, the new platform saves 50%+ of execution time for the majority of tasks at the same compute resource scale.
Reflections on Data Platform Selection for SaaS-Native Digital Enterprises
Based on our experience upgrading the original data platform with Singdata’s product, we offer the following reference points for similar enterprises evaluating data platform selection:
First, digital-native enterprises often experience rapid end-user growth at certain stages, requiring the data platform to handle massive table counts, elastic resource scaling, and — especially — cost-adjustable real-time capability. In early platform selection, these factors should be fully considered, and a streamlined unified/Single-Engine platform architecture should be preferred where possible — reducing development and operational complexity while enabling flexible expansion as business requirements evolve.
Second, SaaS enterprises are cost-sensitive, so the billing model must prioritize pay-as-you-go to avoid resource waste during off-peak periods. The cost advantage of this model grows more significant as user scale increases.
Third, digital-native enterprises face complex data operations and management. Considering platforms with AI4D capabilities — using AI for automatic task optimization — can lower the barrier to operating the data platform.