Understanding and Using Result Cache
Introduction
Singdata Lakehouse uses caching technology to accelerate query performance and efficiency. The platform provides three types of Cache to improve query performance.
-
Query Result Cache
-
Metadata Cache
-
Virtual Cluster Local Disk Cache
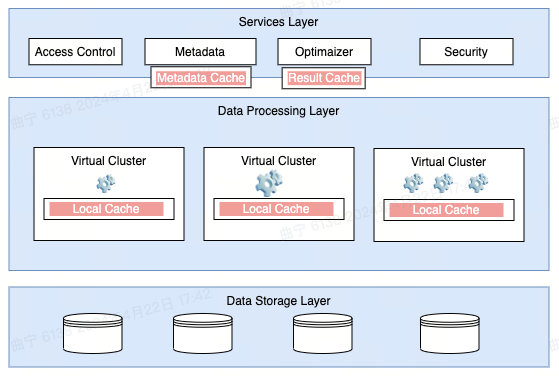
Among them:
- Metadata Cache and Query Result Cache services belong to the service layer and can be shared within the workspace.
- Virtual Cluster Local Disk Cache is stored on the local nodes of the cluster and can only be used when using the specified virtual cluster.
This article will introduce the working principles of the caches and how to use them.
Result Cache
When executing queries in Singdata Lakehouse, query results that meet certain conditions will be automatically retained for a period of time and will be cleared after the period ends. These temporarily stored query results are called Query Result Cache.
The Result Cache must meet the following conditions to be reused:
- The underlying data of the tables used in the query does not change. If the data in any table used in the query changes, the result cache cannot be used;
- The query does not include queries on views. If the query object contains views, the query result cache is not supported;
- The newly initiated SQL query statement can exactly match the previously executed query in syntax;
- The query does not contain non-deterministic functions (e.g., CURRENT_TIMESTAMP()), user-defined functions (UDF);
- The previous Result Cache has not expired and been deleted.
Result Cache Expiration Period
After the result cache is successfully created, the default retention period is 24 hours.
If subsequent queries using the query result cache are run within 24 hours, the result cache expiration time will be extended by an additional 24 hours. Otherwise, the query result cache will be cleared after 24 hours.
Enabling and Disabling Result Cache
Use the parameter cz.sql.enable.shortcut.result.cache at the SESSION level to enable or disable it, as shown below.
Note: As of April 2024, the Result Cache feature in the current Lakehouse version is in public beta and not enabled by default. It will be enabled by default in future versions.
Constraints and Limitations
Cache retention period: 24 hours
Maximum number of jobs supported by the cache in a single workspace: 100,000
Result cache size limit: No limit. Results less than or equal to 10MB will be cached in the control layer memory cache, while results exceeding 10MB will be persisted in the storage layer (object storage files).
Result caching is not supported for non-deterministic functions and UDF query results.
Result Cache Demonstration
To demonstrate query result caching, first enable the result cache and execute an SQL query in Singdata Lakehouse. Then rerun the same query to verify if the new query reused the result cache for acceleration.
The first execution took 12.1 seconds. By checking the Job Profile for job running information, the job read a large amount of data from the disk.
The second time this query was executed, the job reused the result cache from the previous query and returned the result within 15ms.
When viewing the Job Profile of the job, you can see in the execution plan diagram on the diagnostics page that the job used "JOB RESULT REUSE", indicating that the job directly queried the result data.