Writing SQL for Data Cleaning
In the process of data analysis and data mining, data cleaning and preprocessing are crucial steps. This article will introduce various commonly used Lakehouse SQL data cleaning methods to help you better understand and apply these methods.
Setting Up the Environment
Navigate to Lakehouse Studio Development -> Tasks, and click "+" to create a new SQL task (both methods below are implemented in the same task).
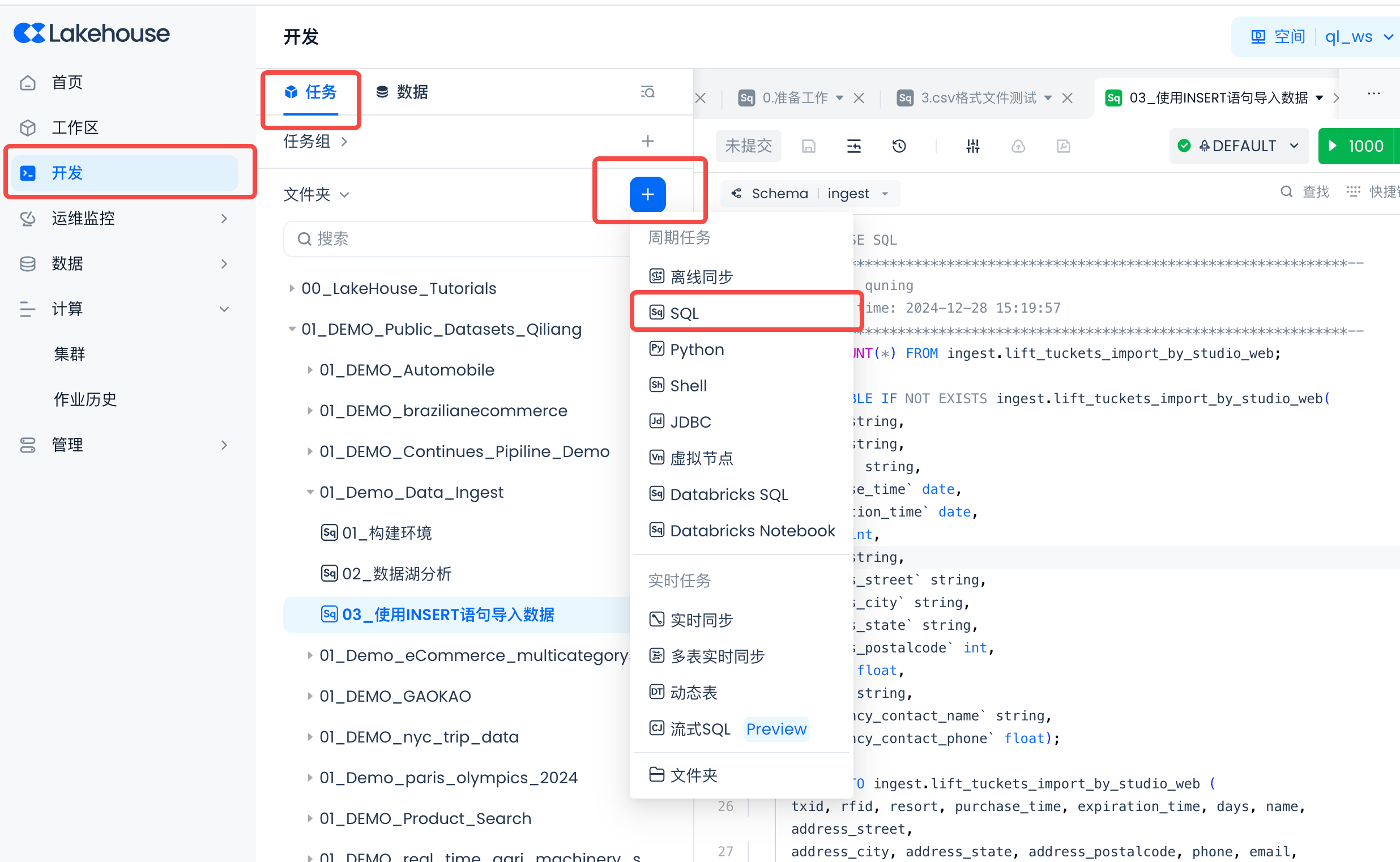
Create two new SQL tasks (as shown below), then get the code from GitHub and copy the SQL code into the two tasks.
Then run each SQL one by one and observe the results.
The following are the descriptions of each step.
Building the Schema and Compute Cluster for the Experiment
Set the schema and cluster for each task in the IDE to the newly created one:
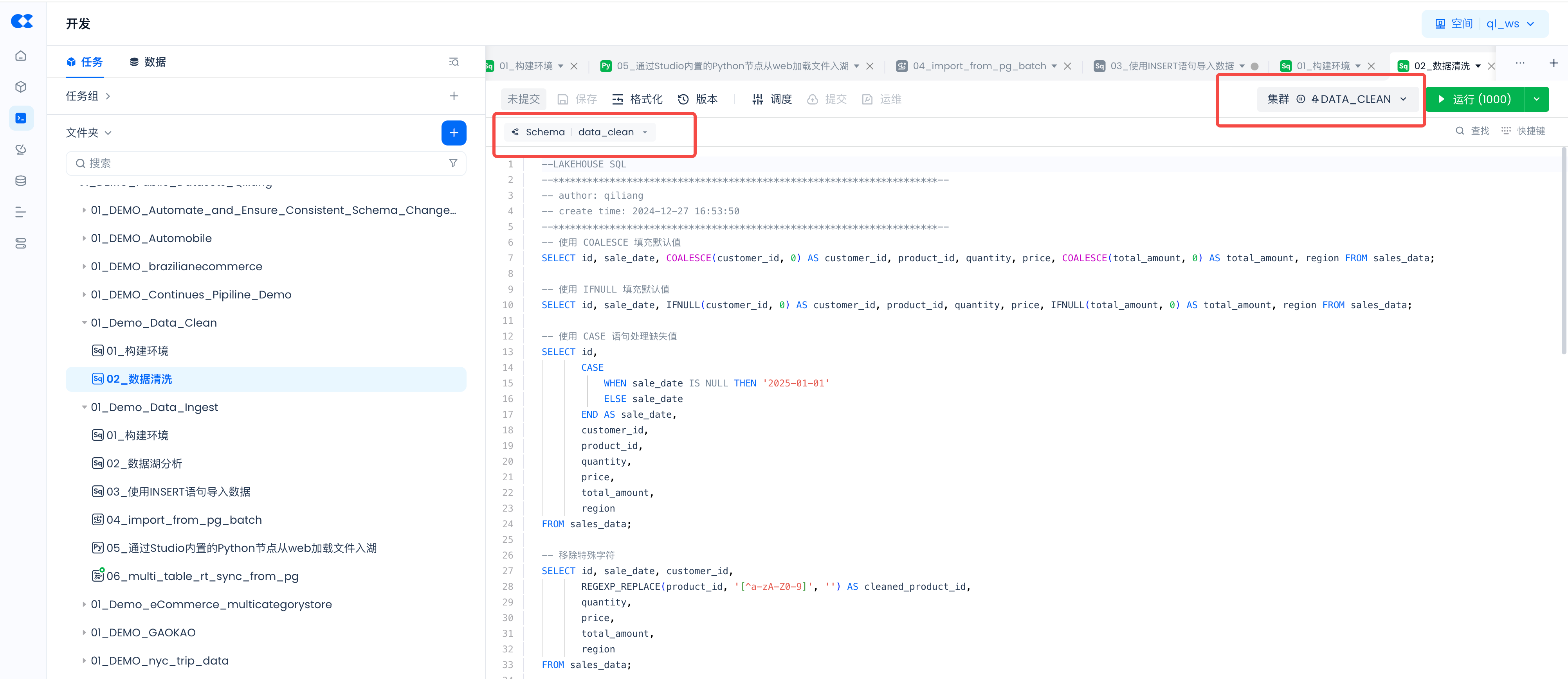
Create a sample table and insert dirty data
First, we need to create a sample table and insert some sample data containing dirty data for demonstration in the following steps.
Dirty Data Issues and Handling Methods
-
Missing Values
- Example:
customer_idis missing in row 3. - Issue: Missing values can lead to incomplete or incorrect analysis.
- Handling: Use
COALESCEorIFNULLto fill in default values, such as0.
- Example:
-
Negative Values
- Example:
quantityis negative in rows 4 and 20. - Issue: Negative values are unreasonable in certain contexts, such as sales quantities.
- Handling: Use
CASEstatements to convert negative values to reasonable values.
- Example:
-
Special Characters
- Example:
product_idcontains special characters in rows 5 and 14. - Issue: Special characters may cause data parsing errors.
- Handling: Use
REGEXP_REPLACEto remove special characters.
- Example:
-
Missing Fields
- Example:
priceis missing in row 6. - Issue: Missing fields lead to incomplete data.
- Handling: Use
COALESCEorIFNULLto fill in default values.
- Example:
-
Empty Strings
- Example:
regionis empty in row 8. - Issue: Empty strings can lead to inaccurate data parsing.
- Handling: Use the
TRIMfunction to remove blank values.
- Example:
-
Illegal Characters
- Example:
regioncontains illegal characters in row 12. - Issue: Illegal characters can cause data parsing errors.
- Handling: Use
REGEXP_REPLACEto remove illegal characters.
- Example:
By handling these dirty data issues using the methods above, data quality can be significantly improved, providing a more reliable foundation for subsequent data analysis and mining.
Handling Missing Values
Description
Missing values are a common issue in data cleaning. They can lead to inaccurate data analysis results. You can use the COALESCE function, IFNULL function, or CASE statements to fill in default values or replace missing values. In actual projects, handling missing values is often used to ensure that key fields are not empty, thereby ensuring data integrity.
Implementation
Remove Special Characters
Description
Special characters can affect data analysis. You can use the REGEXP_REPLACE function to remove these characters. In actual projects, removing special characters is often used to clean up noise characters in text fields, making the data more tidy and standardized.
Implementation
Convert Data Types
Description
Sometimes it is necessary to convert data from one type to another, such as converting a string to a date type. Data type conversion ensures data consistency and accuracy. In actual projects, it is often used to standardize data formats, such as dates, amounts, etc.
Implementation
Remove Spaces
Description
During the data cleaning process, leading and trailing spaces in strings can lead to inaccurate data analysis results. We can use the TRIM function to remove spaces. In actual projects, removing spaces is often used to clean text fields that contain extra spaces.
Implementation
Convert Case
Description
To standardize data formats, text fields can be converted to lowercase or uppercase. In actual projects, case conversion is often used to ensure data consistency, such as in customer names, product names, and other fields.
Implementation
Delete Outliers
Description
Outliers may affect the results of data analysis. You can use the DELETE statement to remove these records. In actual projects, deleting outliers is often used to eliminate extreme or erroneous data to ensure the accuracy of the analysis results.
Implementation
Data Grouping and Aggregation
Description
Through grouping and aggregation, summary reports can be generated to understand the overall situation of the data. Grouping and aggregation operations can help us discover patterns and trends in the data. In practical projects, they are often used for statistics and data analysis, such as calculating total sales, averages, etc.
Implementation
Data Filtering
Description
Use the WHERE clause to filter out data that meets specific conditions. In actual projects, data filtering is often used to extract subsets of data of interest, such as filtering out high-value customers, sales data for specific time periods, etc.
Implementation
Data Sorting
Description
Sorting can help us view data in a specific order and discover patterns and trends in the data. In practical projects, sorting is often used in data presentation, report generation, and other scenarios.
Implementation
Merge Column Data
Description
In some cases, we need to merge the data of multiple columns into one column. In actual projects, merging column data is often used to generate comprehensive information fields, such as full addresses, names, etc.
Implementation
Merging Data
Description
Use the UNION operation to merge multiple result sets together to form a complete result set. In actual projects, merging data is often used to integrate multiple query results into a unified analysis dataset.
Implementation
Through the above SQL data cleaning and preprocessing techniques, you can effectively handle and transform data, laying a solid foundation for subsequent data analysis and mining. Data cleaning not only improves data quality but also brings more accuracy and reliability to data analysis.
SQL Functions List for Data Cleaning
The following is a list of commonly used SQL data cleaning functions:
-
Handling Missing Values
- COALESCE(): Used to replace NULL values with specified default values.
- IFNULL(): Similar to COALESCE(), used to replace NULL values with specified default values.
CASE: Used to handle missing values based on specific conditions.
-
Removing Special Characters
- REGEXP_REPLACE(): Used to replace special characters in text using regular expressions.
-
Converting Data Types
CAST(): Used to convert data from one type to another.
-
Removing Whitespace
- TRIM(): Used to remove whitespace characters from strings.
-
Changing Case
LOWER(): Converts text to lowercase.- UPPER(): Converts text to uppercase.
-
Removing Outliers
- DELETE: Used to delete records that do not meet conditions.
-
Deduplication
- DISTINCT: Used to remove duplicate rows from the result set.
- ROW_NUMBER(): Used to assign a unique row number to each row in the result set.
-
Grouping and Aggregating Data
-
Filtering Data
- WHERE: Used to filter records that meet specific conditions.
-
Sorting Data
- ORDER BY: Used to sort the result set.
-
Joining Data
- JOIN: Used to join two or more tables to form a complete data view.
-
Merging Column Data
- CONCAT(): Used to merge data from multiple columns into one column.
-
Merging Data
- UNION: Used to merge multiple result sets together.