Basic Concepts
SQL Nested Data Types allow complex data structures, such as STRUCT and ARRAY, to be stored in table columns. These structures make it more concise and clear to represent one-to-one, many-to-one, and hierarchical relationships.
- STRUCT: Represents a single field containing multiple related columns, which can represent the attributes of an object.
- ARRAY: Represents an array containing multiple structured fields, suitable for many-to-one relationships.
Advantages
- Simplified Data Schema: Using STRUCT and ARRAY types simplifies the schema of data tables, making it more convenient to store and retrieve related column data.
- Improved Query Performance: Nested data types can reduce table join operations because related data is already nested within a single field.
- Enhanced Readability: Nested structures make the data schema more intuitive, making it easier for developers to understand and use.
- Flexible Data Processing: Nested data types support flexible operations and sorting of complex objects, as well as efficient splitting and reorganization of data during processing.
Use Cases
- One-to-One and Hierarchical Relationships: Suitable for scenarios where multiple related fields need to be combined, such as combining user information with address information.
SELECT
c_custkey,
STRUCT(c_name, c_address, c_phone) AS customer_info
FROM
clickzetta_sample_data.tpch_100g.customer;
- Many-to-One Relationships: Suitable for scenarios where multiple related objects need to be stored in a single field, such as combining orders with their line items.
SELECT
o.o_orderkey,
ARRAY_AGG(STRUCT(o.o_clerk, o.o_totalprice, o.o_orderpriority)) AS items
FROM
clickzetta_sample_data.tpch_100g.orders o
GROUP BY
o.o_orderkey;
- Data Transformation and Cleaning: Nested data types can be used to split data into smaller parts for transformation and cleaning, then recombine them.
-- Define orders_array using a CTE
WITH orders_array AS (
-- Aggregate all order IDs for each customer into an array
SELECT
o_custkey,
ARRAY_AGG(o_orderkey) AS order_keys
FROM
clickzetta_sample_data.tpch_100g.orders
GROUP BY
o_custkey
),
-- Define modified_items using a CTE
modified_items AS (
-- Use the TRANSFORM function to add 1 to each order ID, generating a new array
SELECT
o_custkey,
TRANSFORM(order_keys, x -> x + 1) AS modified_order_keys
FROM
orders_array
)
-- Main query
SELECT
c.c_custkey,
mi.modified_order_keys
FROM
clickzetta_sample_data.tpch_100g.customer c
-- Left join modified_items on customer ID (c_custkey)
LEFT JOIN
modified_items mi
ON
c.c_custkey = mi.o_custkey;
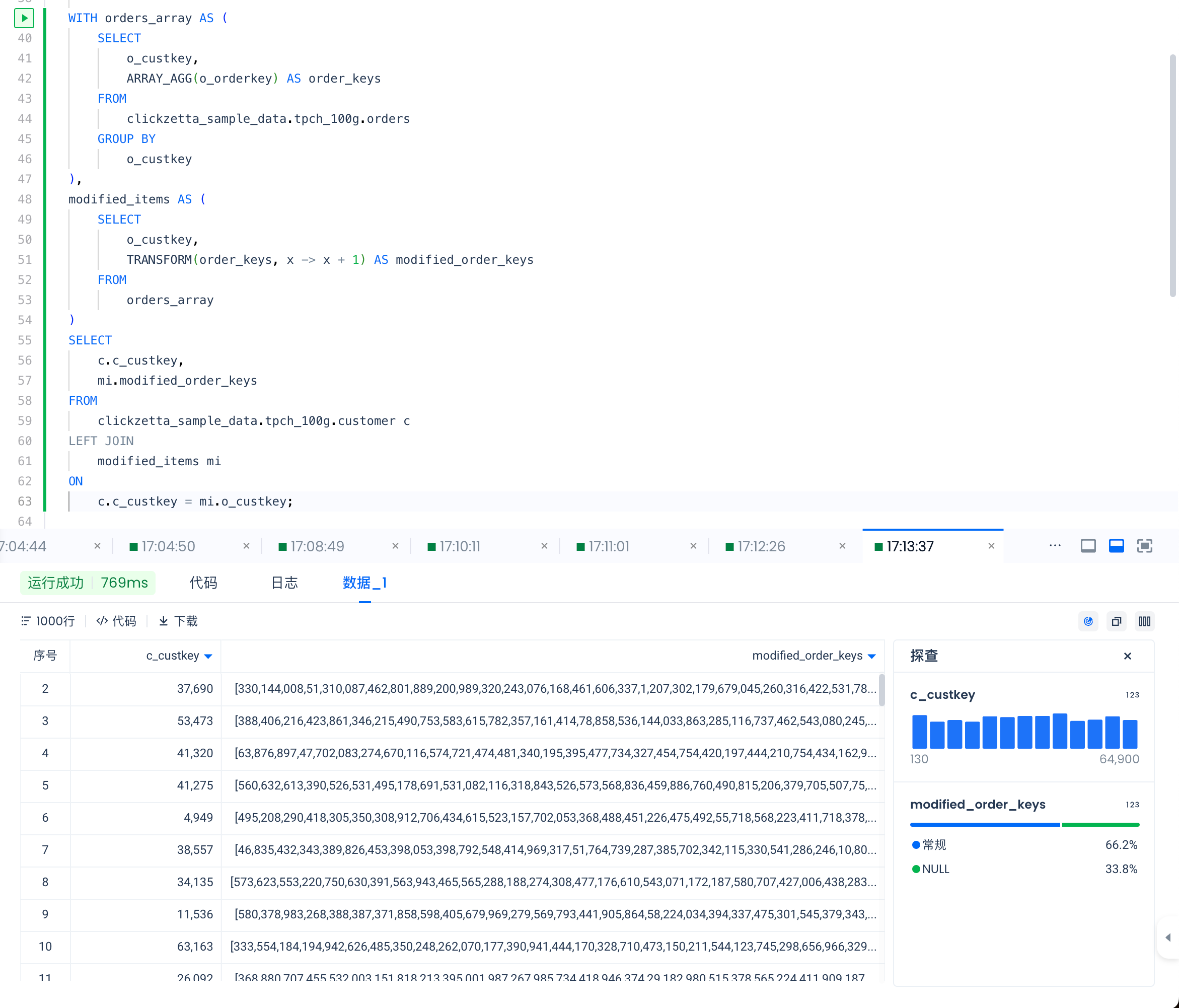
Using nested data types (such as STRUCT and ARRAY) for data transformation simplifies data schemas, improves query performance, and enhances the flexibility and readability of data processing — providing an effective solution for managing complex data structures.
Data Model
The TPC-H dataset represents a data warehouse for an auto parts supplier, containing records for orders, line items, suppliers, customers, parts, regions, nations, and part suppliers (partsupp).
Singdata Lakehouse includes built-in shared TPC-H data that any user can query directly by specifying the data context, for example:
SELECT * FROM
clickzetta_sample_data.tpch_100g.customer
LIMIT 10;
Using Nested Data Types Effectively
Using STRUCT for One-to-One and Hierarchical Relationships
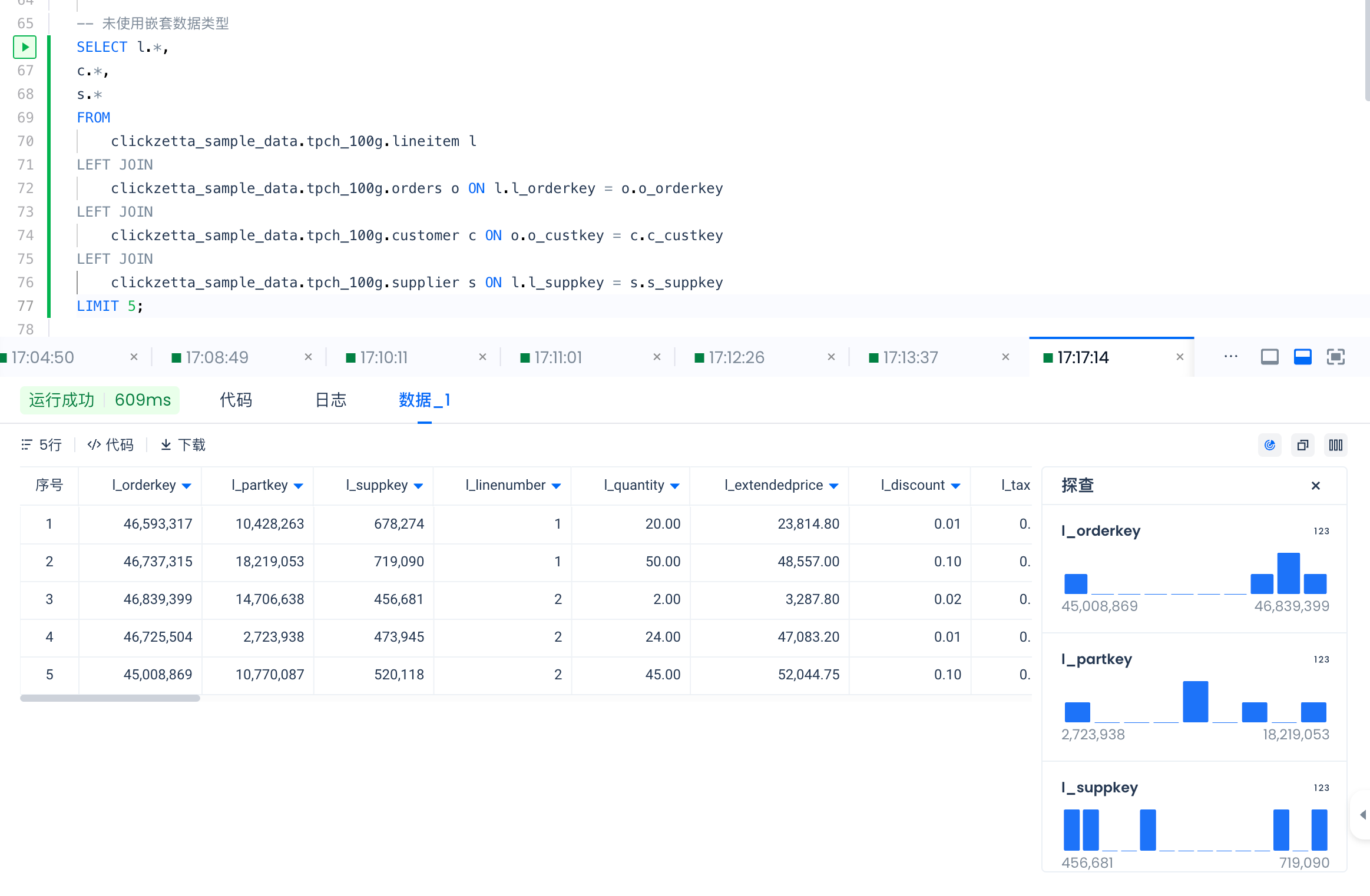
-- Without nested data types
SELECT l.*,
c.*,
s.*
FROM
clickzetta_sample_data.tpch_100g.lineitem l
LEFT JOIN
clickzetta_sample_data.tpch_100g.orders o ON l.l_orderkey = o.o_orderkey
LEFT JOIN
clickzetta_sample_data.tpch_100g.customer c ON o.o_custkey = c.c_custkey
LEFT JOIN
clickzetta_sample_data.tpch_100g.supplier s ON l.l_suppkey = s.s_suppkey
LIMIT 5;
-- Using nested data types
SELECT
l.*,
struct(
c.c_custkey,
c.c_name,
c.c_address,
c.c_nationkey,
c.c_phone,
c.c_acctbal,
c.c_mktsegment,
c.c_comment
) AS customer,
struct(
s.s_suppkey,
s.s_name,
s.s_address,
s.s_nationkey,
s.s_phone,
s.s_acctbal,
s.s_comment
) AS supplier
FROM
clickzetta_sample_data.tpch_100g.lineitem l
LEFT JOIN
clickzetta_sample_data.tpch_100g.orders o ON l.l_orderkey = o.o_orderkey
LEFT JOIN
clickzetta_sample_data.tpch_100g.customer c ON o.o_custkey = c.c_custkey
LEFT JOIN
clickzetta_sample_data.tpch_100g.supplier s ON l.l_suppkey = s.s_suppkey
LIMIT 5;

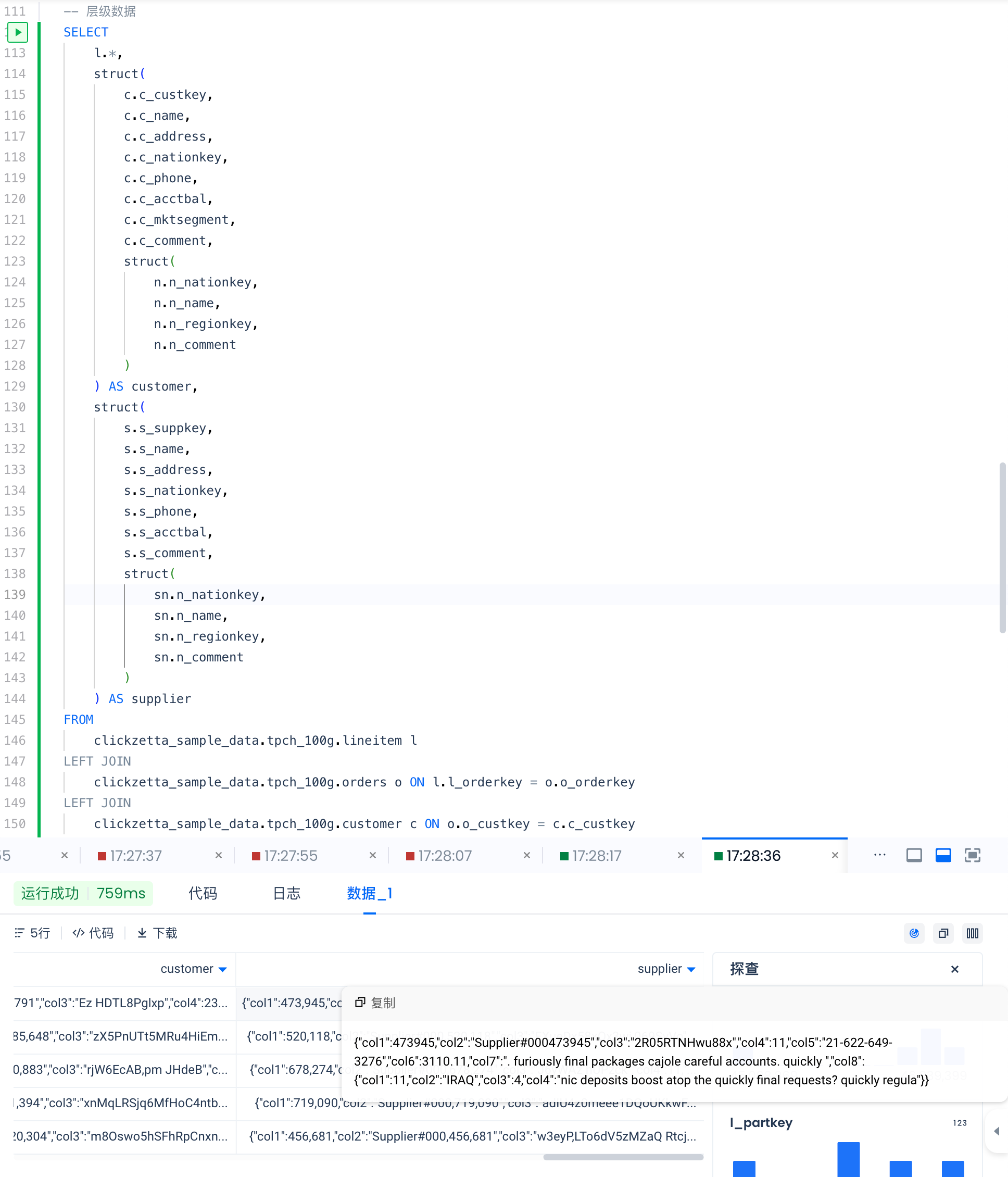
-- Hierarchical data
SELECT
l.*,
struct(
c.c_custkey,
c.c_name,
c.c_address,
c.c_nationkey,
c.c_phone,
c.c_acctbal,
c.c_mktsegment,
c.c_comment,
struct(
n.n_nationkey,
n.n_name,
n.n_regionkey,
n.n_comment
)
) AS customer,
struct(
s.s_suppkey,
s.s_name,
s.s_address,
s.s_nationkey,
s.s_phone,
s.s_acctbal,
s.s_comment,
struct(
sn.n_nationkey,
sn.n_name,
sn.n_regionkey,
sn.n_comment
)
) AS supplier
FROM
clickzetta_sample_data.tpch_100g.lineitem l
LEFT JOIN
clickzetta_sample_data.tpch_100g.orders o ON l.l_orderkey = o.o_orderkey
LEFT JOIN
clickzetta_sample_data.tpch_100g.customer c ON o.o_custkey = c.c_custkey
LEFT JOIN
clickzetta_sample_data.tpch_100g.nation n ON c.c_nationkey = n.n_nationkey
LEFT JOIN
clickzetta_sample_data.tpch_100g.supplier s ON l.l_suppkey = s.s_suppkey
LEFT JOIN
clickzetta_sample_data.tpch_100g.nation sn ON s.s_nationkey = sn.n_nationkey
LIMIT 5;
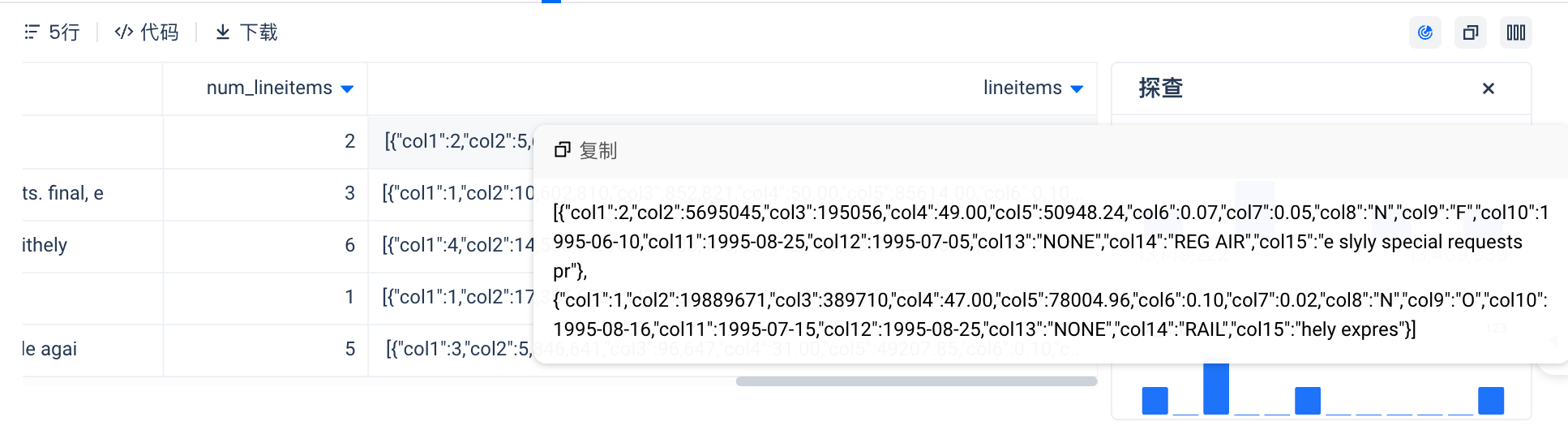
-- Use ARRAY[STRUCT] to handle one-to-many relationships
WITH line_items AS (
SELECT
l_orderkey AS orderkey,
array_agg(
struct(
l.l_linenumber,
l.l_partkey,
l.l_suppkey,
l.l_quantity,
l.l_extendedprice,
l.l_discount,
l.l_tax,
l.l_returnflag,
l.l_linestatus,
l.l_shipdate,
l.l_commitdate,
l.l_receiptdate,
l.l_shipinstruct,
l.l_shipmode,
l.l_comment
)
) AS lineitems
FROM
clickzetta_sample_data.tpch_100g.lineitem l
GROUP BY
l_orderkey
)
SELECT
o.*,
size(l.lineitems) AS num_lineitems,
l.lineitems
FROM
clickzetta_sample_data.tpch_100g.orders o
LEFT JOIN
line_items l ON o.o_orderkey = l.orderkey
LIMIT 5;
Using Nested Data Types in Data Processing
DROP TABLE IF EXISTS wide_orders;
CREATE TABLE IF NOT EXISTS wide_orders AS
WITH line_items AS (
SELECT
l_orderkey AS orderkey,
array_agg(
(
l.l_linenumber AS lineitemkey,
l.l_partkey AS partkey,
l.l_suppkey AS suppkey,
l.l_quantity AS quantity,
l.l_extendedprice AS extendedprice,
l.l_discount AS discount,
l.l_tax AS tax,
l.l_returnflag AS returnflag,
l.l_linestatus AS linestatus,
l.l_shipdate AS shipdate,
l.l_commitdate AS commitdate,
l.l_receiptdate AS receiptdate,
l.l_shipinstruct AS shipinstruct,
l.l_shipmode AS shipmode,
l.l_comment AS comment
)
) AS lineitems
FROM
clickzetta_sample_data.tpch_100g.lineitem l
GROUP BY
l_orderkey
)
SELECT
o.*,
l.lineitems,
(
c.c_custkey AS id,
c.c_name AS name,
c.c_address AS address,
c.c_nationkey AS nationkey,
c.c_phone AS phone,
c.c_acctbal AS acctbal,
c.c_mktsegment AS mktsegment,
c.c_comment AS comment,
(
n.n_nationkey AS nationkey,
n.n_name AS name,
n.n_regionkey AS regionkey,
n.n_comment AS comment
) AS nation
) AS customer
FROM
clickzetta_sample_data.tpch_100g.orders o
LEFT JOIN
line_items l ON o.o_orderkey = l.orderkey
LEFT JOIN
clickzetta_sample_data.tpch_100g.customer c ON o.o_custkey = c.c_custkey
LEFT JOIN
clickzetta_sample_data.tpch_100g.nation n ON c.c_nationkey = n.n_nationkey;
STRUCT makes the data schema and data access simpler.
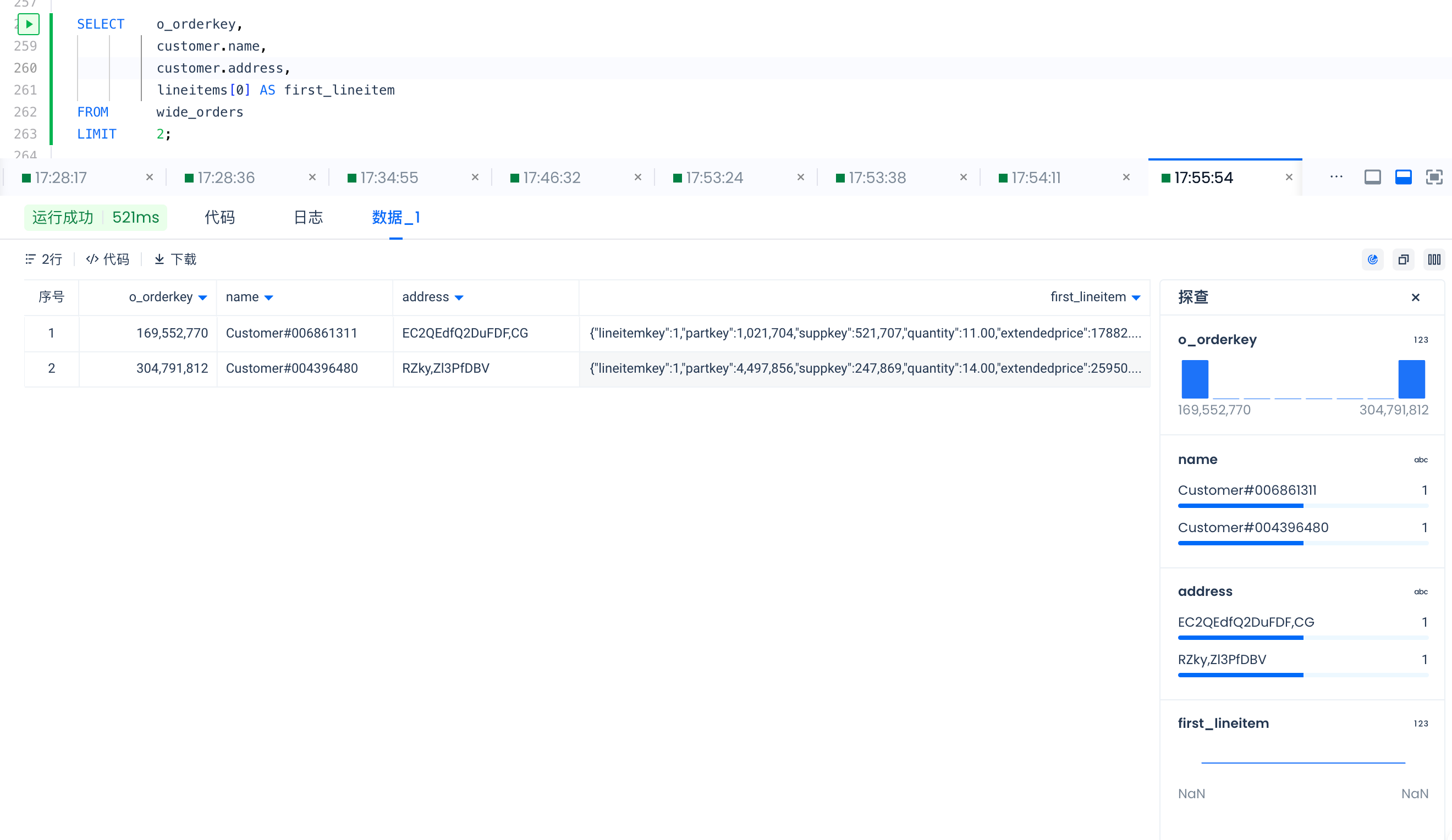
SELECT o_orderkey,
customer.name,
customer.address,
lineitems[0] AS first_lineitem
FROM wide_orders
LIMIT 2;
Expanding an ARRAY into Rows and Recombining into an ARRAY
-- Rows to ARRAY
WITH lineitems AS (
SELECT
o.o_orderkey,
EXPLODE(o.lineitems) AS line_item
FROM
wide_orders o
),
unnested_line_items AS (
SELECT
o_orderkey,
line_item.lineitemkey,
line_item.partkey,
line_item.quantity
FROM
lineitems
)
SELECT
o_orderkey,
array_agg(
struct(
lineitemkey,
partkey,
quantity
)
) AS lineitems
FROM
unnested_line_items
GROUP BY
o_orderkey
LIMIT
5;
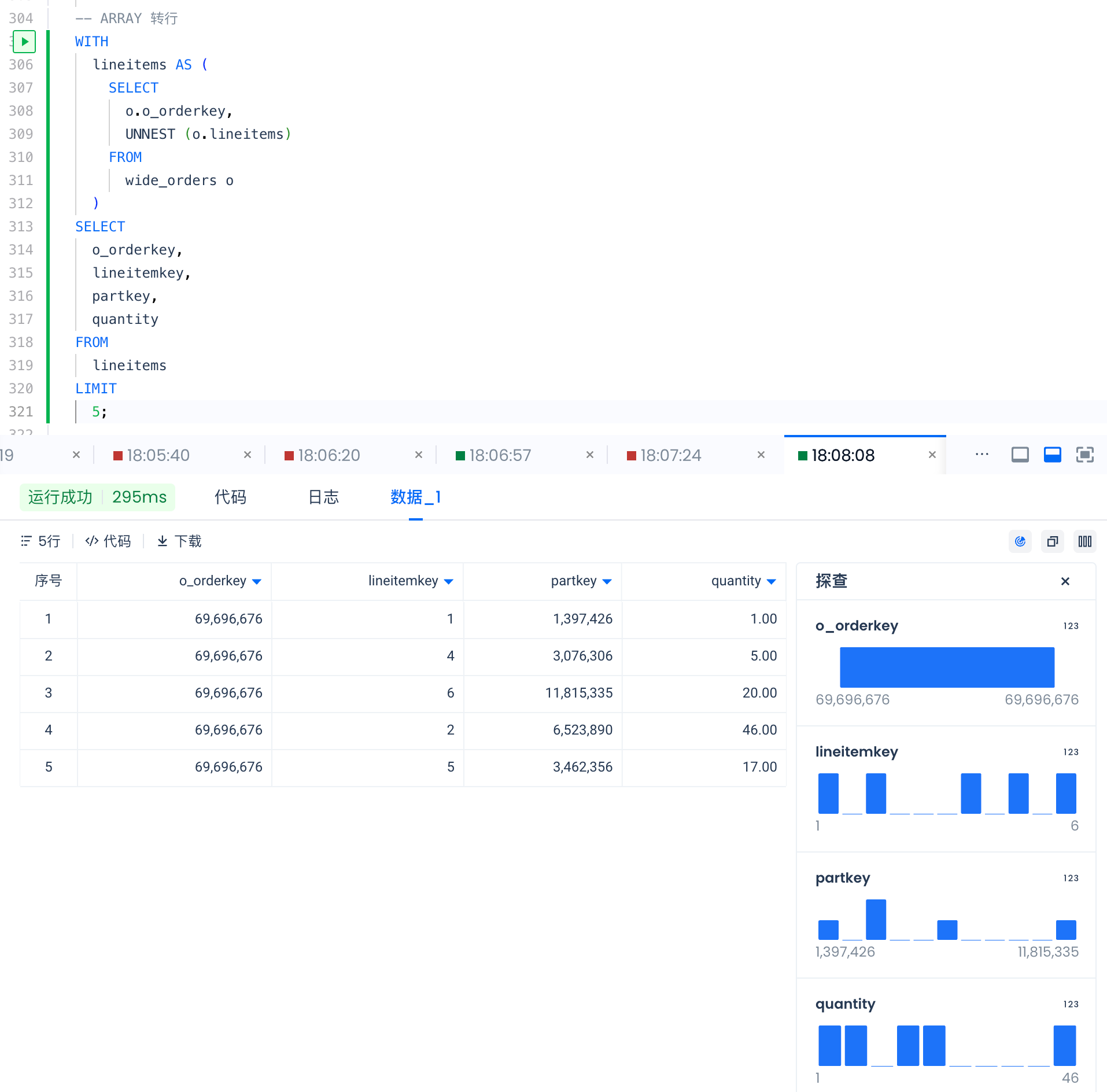
-- ARRAY to rows
WITH
lineitems AS (
SELECT
o.o_orderkey,
UNNEST (o.lineitems)
FROM
wide_orders o
)
SELECT
o_orderkey,
lineitemkey,
partkey,
quantity
FROM
lineitems
LIMIT
5;
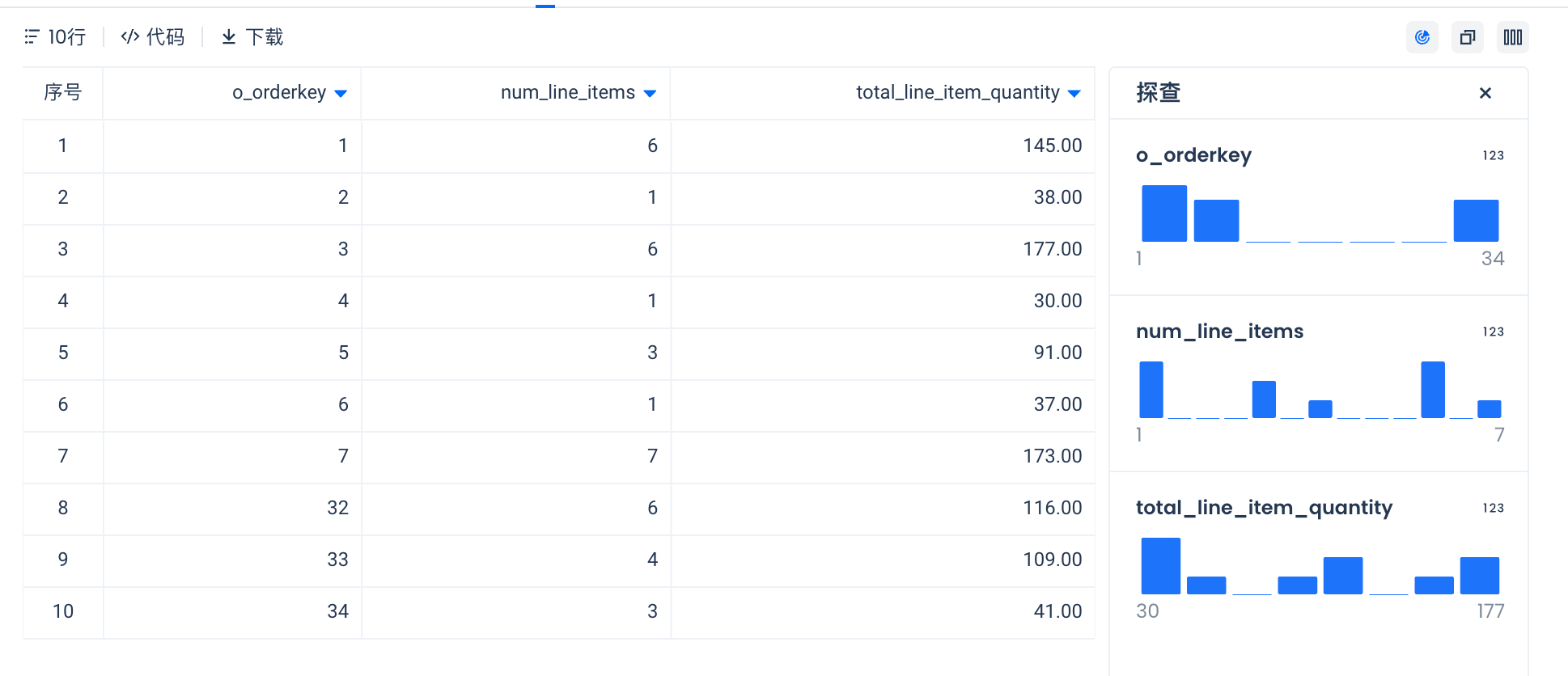
-- Get lineitem metrics
WITH
lineitems AS (
SELECT
o.o_orderkey,
UNNEST (o.lineitems)
FROM
wide_orders o
)
SELECT
o_orderkey,
COUNT(lineitemkey) AS num_line_items,
SUM(quantity) AS total_line_item_quantity
FROM
lineitems
GROUP BY
1
ORDER BY
1
LIMIT
10;
EXPLAIN
WITH
lineitems AS (
SELECT
o.o_orderkey,
UNNEST (o.lineitems)
FROM
wide_orders o
)
SELECT
o_orderkey,
COUNT(lineitemkey) AS num_line_items,
SUM(quantity) AS total_line_item_quantity
FROM
lineitems
GROUP BY
1
ORDER BY
1
LIMIT
10;
References
When using nested structures, pay attention to query execution performance. You can use EXPLODE to inspect the execution plan and verify it meets expectations.
EXPLODE
UNNEST
ARRAY_AGG