Lakehouse Parameter Control
Lakehouse supports controlling the usage behavior of data objects and the current connection session through parameters. This article will detail how to add or modify parameters by modifying the properties of Workspace, Schema, and Table, as well as how to set session parameters in a JDBC client session.
Data Object Parameters
Workspace Properties
To modify Workspace properties, please use the following syntax:
To view Workspace properties, please use the following syntax:
Schema Properties
To modify Schema properties, please use the following syntax:
To view the Schema properties, please use the following syntax:
Table Properties
To modify Table attributes, please use the following syntax:
To view Table properties, please use the following syntax:
Parameters Supported by Tables
The following table lists system properties along with their descriptions and value ranges:
| Parameter Name | Description | Value Range |
|---|---|---|
| data_lifecycle | Data lifecycle | Positive integer greater than 0, a value of -1 indicates that the lifecycle is not enabled |
| data_retention_days | Sets the Time Travel retention period, which determines how long you can access historical data, including using UNDROP, TABLE STREAM, and RESTORE to access and recover historical data | You can set different data retention periods for each table to meet different business needs. The range for num is 0-90, and Lakehouse will charge separate storage fees for Time Travel |
| cz.storage.write.max.string.bytes | The STRING type is used to store character sequences with a length greater than or equal to 0, supporting up to 16MB of text data. When importing data in batch or real-time, the system will validate the field length. If the imported data exceeds 16MB, you can adjust the string length limit by modifying the table properties, for example, setting the STRING length to 32MB: ALTER TABLE table_name SET PROPERTIES("cz.storage.write.max.string.bytes"="33554432"); | Positive integer |
| cz.storage.write.max.binary.bytes | The binary type is used to store data with a maximum length of 16MB. When importing data in batch or real-time, the system will validate the field length. If the imported data exceeds 16MB, you can adjust the binary length limit by modifying the table properties, for example, setting the binary length to 32MB: ALTER TABLE table_name SET PROPERTIES("cz.storage.write.max.binary.bytes"="33554432"); | Positive integer |
| cz.storage.write.max.json.bytes | The json type is used to store character sequences with a length greater than or equal to 0, supporting up to 16MB of text data. When importing data in batch or real-time, the system will validate the field length. If the imported data exceeds 16MB, you can adjust the JSON string length limit by modifying the table properties, for example, setting the json length to 32MB: ALTER TABLE table_name SET PROPERTIES("cz.storage.write.max.json.bytes"="33554432"); | Positive integer |
Session Parameters
Lakehouse supports setting parameters in the JDBC client session. The following is a list of currently supported parameters:
| Parameter Name | Value Range | Default Value | Description |
|---|---|---|---|
| query_tag | String type | None | Used to tag the SQL of the query |
| schedule_job_queue_priority | 0-9 | 0 | Sets the job priority when submitting SQL, with a range from 0 to 9, where a higher value indicates higher priority |
| cz.sql.group.by.having.use.alias.first | true/false | false | Specify whether the group by and having statements should prioritize using column aliases instead of looking for column names from the From statement. |
| cz.sql.double.quoted.identifiers | true/false | false | Delimiter identifier |
| cz.sql.cast.mode | tolerant/strict | tolerant | Mode used for type conversion, default is tolerant |
| cz.optimizer.enable.mv.rewrite | true/false | false | Whether to enable Materialized View query rewrite function when submitting SQL |
| cz.sql.string.literal.escape.mode | backslash | quote:quote, backslash:backslash, quote_backslash:support both quote and backslash | String escape character. By default, backslash is used for escaping, etc. |
| cz.sql.arithmetic.mode | tolerant | strict/tolerant | Control whether arithmetic errors throw exceptions. For example, precision overflow in calculations, by default, no exception is thrown |
| cz.sql.timezone | utc+08 | You can specify timezone name such as: America/Los_Angeles, Europe/London, UTC or Etc/GMT | Set SQL timezone |
| cz.sql.remote.udf.lookup.policy | schema_only: Enforces that UDFs must be prefixed with a schema. | builtin_first: Prioritizes built-in functions; udf_first: Prioritizes UDFs; schema_only: Default policy, enforces that UDFs must be prefixed with a schema. | Dynamically switches the resolution priority between UDFs and built-in functions. |
| cz.sql.translation.mode | N/A | Supports postgres, mysql, starrocks, hive, presto | Lakehouse provides a SQL dialect compatibility layer that automatically translates mainstream database dialects into native SQL syntax. This feature is implemented based on SQLGlot. If incompatible syntax is encountered, setting this parameter will automatically convert the syntax, transforming SQL from the corresponding dialect into syntax executable by Lakehouse. Note that not all syntax is supported; only a subset of syntax can be translated. |
How to Use Session Parameters
After setting parameters in JDBC, these parameters will take effect in the entire current JDBC connection. For example, to set the cz.sql.group.by.having.use.alias.first parameter, use the following command:
In the Lakehouse Studio editor, you need to select the queries you want to execute and run them. For example, to set the query_tag parameter and execute a simple query, follow these steps:
- Run the following command to set the
query_tagparameter:
2. Execute a Query:
python sdk setting parameters
SQL hints set via the set command in JDBC can be passed through the parameters parameter. Here is an example of modifying the time zone:
Session Parameter Description
cz.sql.group.by.having.use.alias.first
This parameter specifies whether the group by and having statements should prioritize using column aliases rather than looking for column names from the From statement. For example, consider the following query:
If this parameter is enabled, the query will be grouped by the alias c1. Otherwise, an error will be reported that c1 cannot be found.
query_tag
After setting the query_tag, the query job history in the session will automatically add custom tag content in the query_tag field of the job history. It can be set via the set query_tag command or in the jdbc URL. For example:
- Add
query_tagin the JDBC URL, so that each submitted SQL will carry thequery_tagto indicate the source, which can be filtered on the page. - Set query_tag in python code
In the job history of the studio, filter for exact matches only
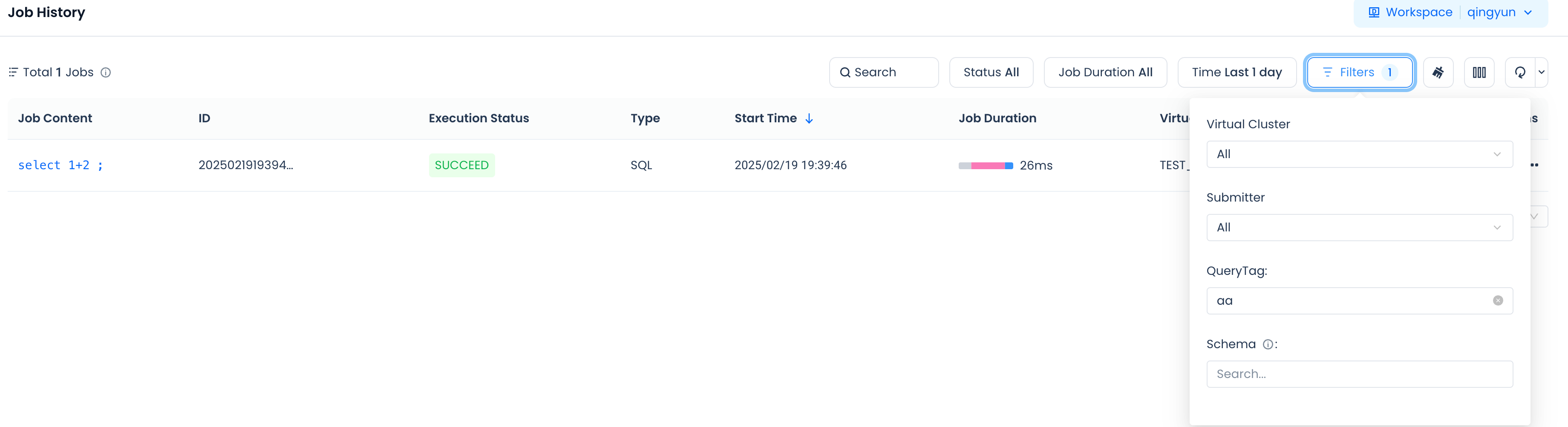
With the help of the query_tag parameter, you can classify and retrieve jobs. Filter jobs in the Lakehouse's information_schema query:
In show jobs, you can filter:
desc jobs can also display the set query tag

cz.sql.double.quoted.identifiers
- In the ANSI/ISO SQL standard, identifiers within double quotes (delimited identifiers) allow users to write special characters or keywords. Singdata can also be compatible with this behavior.
- When enabled, double quotes act as delimiters for identifiers. Set
cz.sql.double.quoted.identifiers=truecurrently only supports session-level enabling. It is important to note that if double quotes are enabled as delimiters for identifiers, Singdata will no longer consider data enclosed in double quotes as a string type.
cz.sql.cast.mode
- When cast strict mode is enabled, attempting to convert incompatible types will result in an error. You can use the
try_castfunction. - Implicit conversion behavior will result in an error if the conversion is not possible. Example:
select case when true then 'lakehouse' else nvl(null,-99) end;In this example, we want to return the string 'lakehouse'. However, due to non-standard SQL writing,nvlcontains an int type, whilethencontains a string type. According to the type precedence conversion rules, it is inferred that the overall return type should be an int. Since the condition is true, it directly enters the true output. Because 'lakehouse' is a string being converted to an int, the system's default behavior will directly usetry_cast, converting 'lakehouse' to int will result in null, leading to unexpected results. In strict mode, the system will not automatically usetry_castand will throw an exception, informing the user that this SQL is not standard behavior. If the logic is confirmed to be correct, add thetry_castfunction when ANSI mode is enabled.
schedule_job_queue_priority
Job Priority The SQL jobs submitted by users come with a priority setting, which determines the execution order of the jobs in the queue. The system uses these settings to decide which jobs should be executed first and prioritizes sending them to the virtual cluster (VCLUSTER) for processing. For GP and AP types of VCLUSTER, the priority setting determines which job is sent to the VCLUSTER first. When there are a large number of jobs queued up in the computing cluster waiting to be processed, setting job priorities is particularly effective.
Job Priority Classification
- Definition: Job priority is a numerical value used to indicate the execution order of jobs.
- Corresponding Numbers: The numerical range is from 0 to 9, with higher values indicating higher priority.
Job Priority Setting
- SQL Support: Users can modify the job priority in the current temporary session to specify the priority when submitting jobs.
- Setting Syntax: Use the following command to set the job priority:
- Among them, {priority value} is an integer between 0 and 9. Example
Below are examples for the parameters you mentioned:
cz.sql.string.literal.escape.mode
Parameter Description: This parameter is used to control the escape character for string literals. The default is to use a backslash (\) as the escape character.
Example:
-
Default mode (backslash):
-
Quote Mode (quote):
Example 1: Including single quotes in a string
This query will return the string It's a beautiful day. Note that two single quotes '' are used here to represent a single quote.
Case 2: Automatic concatenation of string constants
Case 3: Invalid String Concatenation
- Supports both quote and backslash mode (quote_backslash):
In this example, you can either use a backslash to escape special characters or use double quotes to enclose quotes.
cz.sql.arithmetic.mode
Parameter Description: This parameter controls whether an exception is thrown when an arithmetic operation error occurs. The default is tolerant, which means no exception is thrown.
Example:
- tolerant mode (default):
In this example, dividing by 0 returns a NULL or an overflowed value, instead of throwing an exception.
- strict mode:
In this example, an exception will be thrown because arithmetic operations dividing by 0 are not allowed in strict mode.
cz.sql.timezone
Parameter Description: This parameter is used to set the SQL session timezone.
Example:
-
Set the timezone to UTC+08:
-
In this example, the
NOW()function will return the current date and time, adjusted to theAsia/Shanghaitime zone (UTC+08). -
Set the time zone to UTC:
In this example, the NOW() function will return the current date and time, adjusted according to the UTC time zone.
cz.sql.remote.udf.lookup.policy
Parameter Description: Dynamically switches the resolution priority between UDFs and built-in functions.
Example: Default behavior: When using a UDF, the SCHEMA prefix must be specified.
cz.sql.translation.mode 【Preview Release】This feature is currently in public preview release.
Parameter Description: By setting this parameter, LakeHouse can automatically translate the syntax of the specified SQL dialect into native executable syntax, enabling multi-dialect compatible queries. This feature is implemented based on the enhanced version of SQLGlot, which supports transparent conversion of common database syntax into LakeHouse native syntax to reduce the cost of business migration. Note that not all syntax is supported for translation; only a subset of syntax can be translated. Currently supported dialects include PostgreSQL, MySQL, Doris, Hive, and Presto.
Example: Setting Doris translation:
DATE_FORMAT and AES_DECRYPT functions need to specify cz.sql.patible.target engine compatibility mode to set the original semantics of compatibility with MySQL or PostgreSQL.