Low Latency Real-Time Data Integration and High-Performance Real-Time Analysis
This document introduces the construction of a highly stable, low-latency real-time lakehouse data integration solution based on Singdata Lakehouse and high-performance real-time analysis based on the same lakehouse data.
Overview
As enterprise business expands, real-time data analysis becomes crucial. It not only supports business decision-making but is also a necessary condition for driving enterprise development. To achieve real-time data analysis, enterprises typically face two technical solution choices:
- Directly using the business database for BI analysis: This method is simple to operate and can be quickly implemented. However, it encounters performance bottlenecks when dealing with large-scale data and complex queries, especially when complex operations such as multi-table joins are required. The query response time will be significantly extended, failing to meet the needs of real-time analysis. Additionally, for stability and security considerations, business databases are usually not allowed to be directly used for data analysis, which limits the operational space of the data analysis team.
- BI analysis solution based on data warehouse: This solution synchronizes data from the business database to the data warehouse, utilizing the high-performance processing capabilities of the data warehouse to support BI analysis. This method effectively solves the performance problem, but the biggest challenge lies in the real-time nature of the data. Traditional data synchronization is usually in T+1 or H+1 batch processing mode, which cannot meet the business's real-time data requirements and often requires the deployment of additional OLAP engines, further increasing costs.
Singdata Lakehouse provides a highly stable, low-latency real-time lakehouse data integration solution. It can achieve real-time data synchronization from various source data sources (such as MySQL, PostgreSQL, SQL Server, etc.) and directly support real-time queries of BI reports. This solution maintains the same data in the data warehouse, supporting both real-time data writing and real-time querying of BI reports, eliminating the need for additional OLAP engine deployment in traditional solutions. This design simplifies the data architecture, reduces costs, and ensures data real-time and query efficiency, providing enterprises with an economical and efficient real-time data analysis solution.
Real-Time Lakehouse Data Integration
This section will elaborate on the productized real-time lakehouse integration solution and how to conveniently synchronize massive database table data into the Lakehouse.
Scenario and Data Description
In this demonstration practice, four tables with 1 million rows of data each are prepared in the source MySQL database. The plan is to synchronize these 4 million rows of data into the target Singdata Lakehouse tables and then directly use BI reports for query analysis.
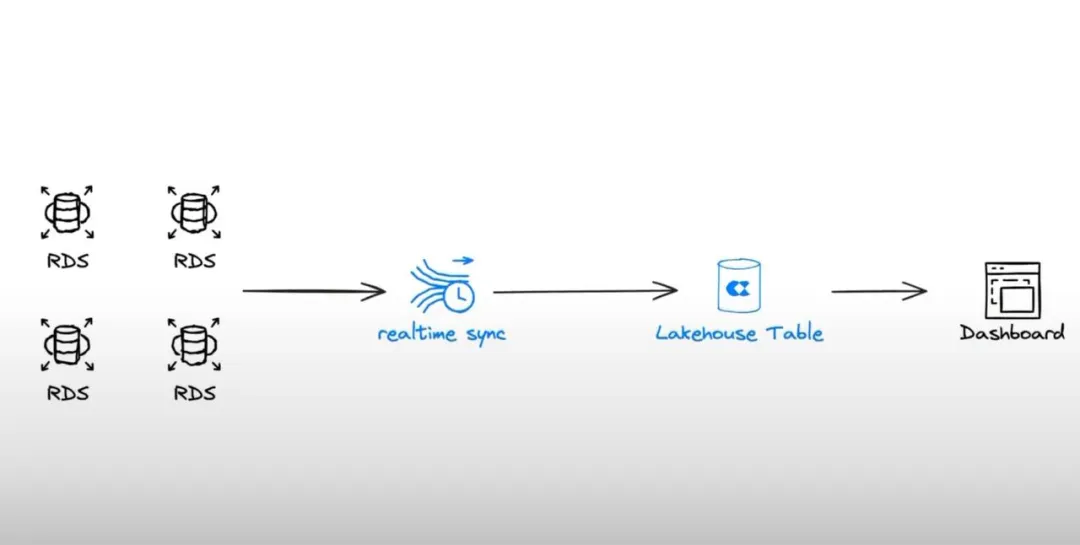
This demonstration takes the common SaaS service model as an example. In a multi-tenant mode, the database adopts a sharding structure, and data exists in different sharded tables. Some tenant information will exist in the same sharded table, and different sharded tables contain custom extension fields for specific tenants. That is, the source end has four basically identical sharded tables, but some tables have slight differences in fields. As shown in the figure below, the yellow_taxi_02 table has an additional extension field ext_columm_2 compared to the yellow_taxi_00 table.

Prerequisites: Data Source Configuration
Navigate to Management -> Data Source, click "New Data Source" and select MySQL to create the data source required for this case. Fill in the necessary configuration information, especially paying attention to selecting the correct time zone of the database. Real-time synchronization is sensitive to time zones, and configuration errors will cause synchronization to fail.
For advanced configurations such as source database permissions, refer to this document.
Real-Time Synchronization Task Configuration
First, click "New Multi-Table Real-Time Synchronization Task" in Task Development and select the correct source data source type, such as MySQL.
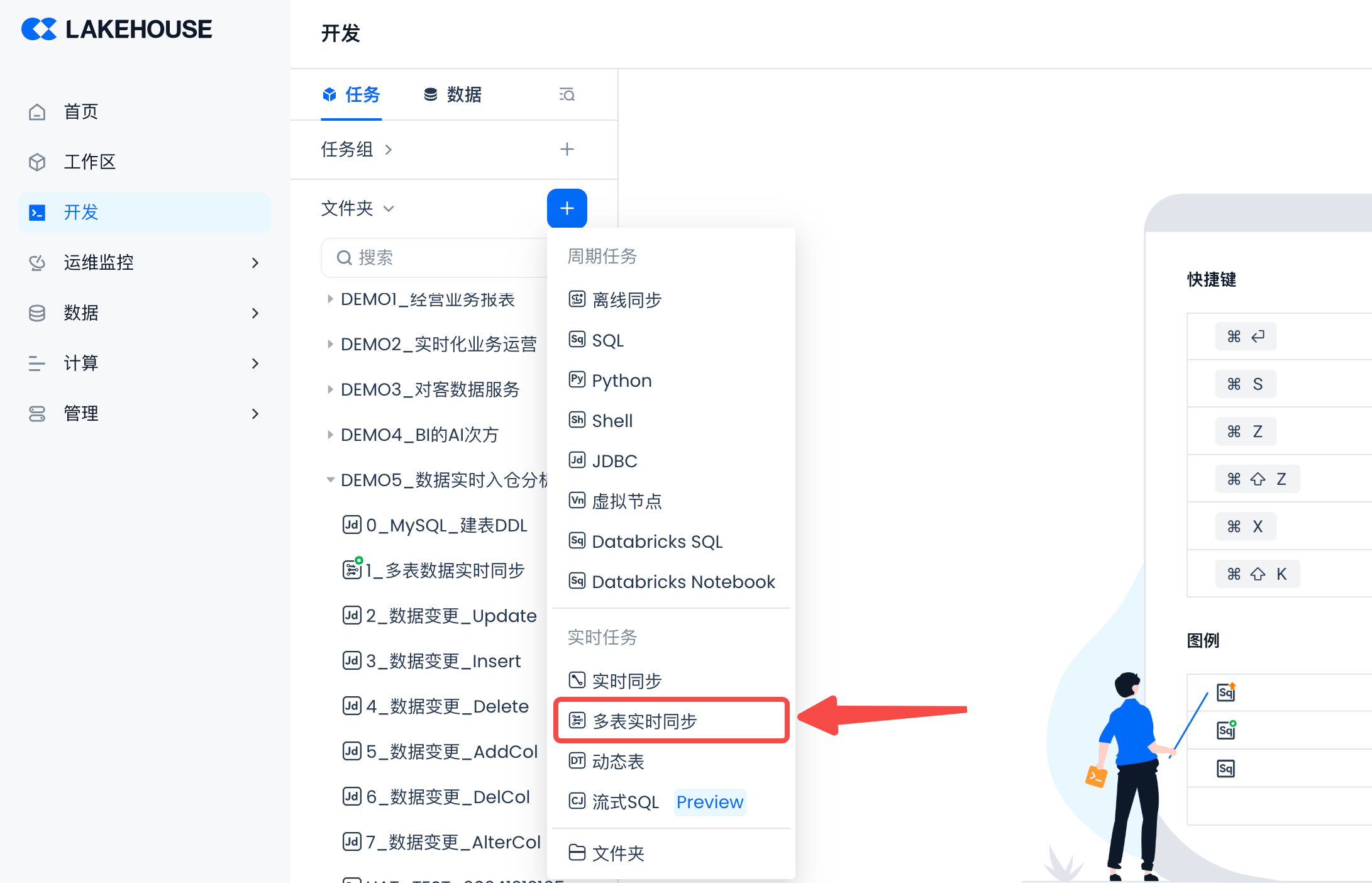
Real-time synchronization tasks provide two types of data synchronization modes:
- First type: Multi-table mirroring synchronization, which mirrors the source data tables to the target end as they are.
- Second type: Multi-table merge synchronization, which supports merging multiple source tables into the same target table. This is the scenario used in this practice. In the case of large source data volumes and sharding, merging multiple tables into the same table during synchronization eliminates the need for multi-table JOIN in subsequent queries, speeding up the query.
After selecting the synchronization mode, choose the data source that stores the source connection string information.
Next, configure the data objects to be synchronized. The product provides rich filtering rules to screen source tables, such as exact name matching, regular expression matching, etc., which can be used as needed. When there are inconsistencies in the source table fields, the system will automatically detect and prompt to enable the heterogeneous table merge synchronization function. The heterogeneous table merge synchronization function creates a table at the target end by taking the union of the source table fields, ensuring that all source data can be synchronized to the target end.
After configuration, you can preview and check the fields of specific tables to ensure that the extension fields are also added, ensuring data consistency.
If you use the mirror synchronization mode instead of the multi-table merge mode, the structure of the source table will be completely mapped to the target table, but ETL processing is still required to produce a new merged table for BI queries. Adding a table also adds a processing link, which increases complexity and extends the end-to-end link, significantly reducing data freshness and timeliness, and increasing costs.
As mentioned earlier, the source data is stored using a sharding method, but a more complex situation is often encountered: records with the same primary key field values in the source end may appear duplicated in different sharded tables. The data in this example is also designed to simulate a similar situation. In the source end, the same primary key ID value in two tables will have a record in each table, which poses a challenge for synchronization: when merging and writing to the target end, if only the ID is used as the primary key, these two records will be attempted to be written into one record, causing data conflicts. The two source records will be processed in sequence, with the later source table data overwriting the earlier source table data. To address this situation, the Lakehouse real-time synchronization solution provides the ability to extend fields to ensure data accuracy. By identifying the source of the data, such as setting fields like server, databasename, and tablename as composite primary keys, these two records will be treated as two separate records in the target end. This ensures that even in complex situations where the primary key data is duplicated in the sharded tables at the source end, the source data can still be accurately synchronized to the target end.
After completing the above configuration, the next step is to set the target data source type, data source name, and other configuration items in the "Target Configuration".
Next, you can preview the synchronized field configuration in the mapping relationship, where you can see the extended fields included, and the extended fields/composite primary keys are also reflected here.
Singdata Lakehouse real-time synchronization also provides rich synchronization rule strategies to dynamically adapt to changes in the source database (Schema Evolution), such as strategies for handling situations where fields are added or deleted in the source table, and the types of source change messages that need to be processed.
At this point, the entire real-time synchronization task is configured, requiring only four simple steps: select the data source, define the source synchronization objects, select the target end, and set the synchronization strategy.
Submit and Start Real-Time Data Synchronization
Singdata Lakehouse provides two modes: development environment and production environment. To run this task in the production environment, it needs to be published and submitted first, and then started in the Operations Center.
-
Submit Multi-Table Real-Time Synchronization Task: In the task editor, click the "Submit" button to publish the task configuration to the production environment.
-
Operate Multi-Table Real-Time Synchronization Task: Navigate to the Operations Center to find and manage the submitted task.
-
Start Multi-Table Real-Time Synchronization Task: When starting, you can choose whether to perform a full data synchronization based on actual needs. For the first synchronization, it is usually recommended to perform a full data synchronization once, and then proceed with incremental data synchronization.
After the task starts, you can see in the operations interface that the task will enter the full synchronization stage, with data being written at a rate of 25,000+ rows/second.
Specifically, the multi-table real-time synchronization task only needs to perform a full synchronization of the source end once during the first start. After the full synchronization is completed, the task will automatically switch to the incremental synchronization phase without manual changes, ensuring seamless data continuity.
Verify the Effect of Data Change Synchronization
In practical applications, it is common for the source database tables and structures to change due to business needs, such as adding fields, deleting fields, or changing field types in the source table. Lakehouse real-time synchronization also provides corresponding solutions for these situations.
Singdata Lakehouse product supports direct manipulation of the source database, allowing modifications, queries, and other operations on the source database through SQL. First, we make changes to the source data by adding some new fields: ext_column_0 & ext_column_1, deleting a field in the source table, and changing a field type from int to bigint.
Next, you can see on the monitoring page that the data changes from the source have been synchronized for consumption. Based on the Schema Evolution rules configured in the synchronization task, it automatically updates without manual operation for additional configuration or task restart, ensuring the smooth operation of the entire synchronization link.
After the synchronization is complete, you can also check in the task operation and maintenance interface whether the changes from the source have been successfully synchronized to the target. The newly added fields ext_column_0 & ext_column_1 have been extended to the target, and the changed bigint field has also been updated.
Stability and Metrics Monitoring of Real-time Synchronization Tasks
After the real-time synchronization and analysis link is established, one of the most concerned issues is the stability of the entire link. The product provides comprehensive monitoring information display for each multi-table synchronization task, such as synchronization status, synchronization delay, etc. For possible abnormal situations in the synchronization link, such as a single data write failure causing the task to fail, it also provides automatic Failover capability for the task. After the task fails, it will be automatically restarted, reducing the need for manual operation and maintenance.
Singdata Lakehouse provides a monitoring and alerting product module with rich built-in status and metrics monitoring capabilities. It supports custom configuration of monitoring rules to comprehensively monitor the status of the entire task operation, including task instance operation failure, single table stock data synchronization exception, end-to-end delay of real-time synchronization tasks, job failover, source data reading point delay, etc. A series of monitoring items can be monitored by configuring corresponding rules.
In this practice demonstration, some monitoring rules were configured to monitor whether the end-to-end synchronization delay exceeds 10 seconds. When the quantity is particularly large, the delay will be captured by the monitoring and alert notification will remind the responsible person to perceive and handle it in time.
Operation and Maintenance of Real-time Synchronization Tasks
In actual production, various complex problems are often encountered. Therefore, Singdata's real-time synchronization solution also provides a variety of supporting operation and maintenance functions for support. For example, during real-time synchronization, if the source data changes and there is a problem with the data in a certain table, we provide a data replenishment synchronization function that supports re-synchronizing the entire table. During business peak times, when the source change traffic is very large, the real-time synchronization of multiple tables' change data will affect each other. In both cases, the full data replenishment synchronization function can be used to accelerate the data synchronization process. For example, re-synchronizing the source table yellow_taxi_00 for full data replenishment: its incremental real-time synchronization will be paused, and the background will re-synchronize the source data in a full manner. After the full data replenishment synchronization is completed, the incremental synchronization will automatically start without manual operation.
In addition, Singdata Lakehouse also provides a priority execution function for daily operation and maintenance. When multiple tables need to be synchronized and resources are relatively limited, you can choose to prioritize the allocation of resources to more important business tables, and prioritize the data synchronization of that table in the task queue. This ensures the freshness of critical business data even when there is a backlog of consumption and increased end-to-end delay.
High-performance Real-time Analysis
In the traditional offline data warehouse architecture, data is directly connected to the BI engine for querying after ETL processing, often resulting in slow response times. Therefore, enterprises usually introduce real-time analysis engines such as Clickhouse to improve query performance. Singdata's solution simplifies this process by enabling real-time data writing from the source and immediate query analysis of the target table without the need for an additional query acceleration engine.
In this demonstration, we used the Metabase BI tool to build a report showing the comparison of the number of rows of MySQL data at the source and the number of rows in Singdata Lakehouse, and conducted complex query analysis, such as calculating the average fare based on the number of passengers. During this process, real-time data synchronization and query analysis were both completed on the same table, highlighting the advantages of Singdata's solution in simplifying architecture and improving efficiency.
Through the "Job History" module provided by the product, you can view all SQL details submitted to the Lakehouse engine. The real-time synchronization writes to the `yellow_taxi_demo` table, which is also queried in real-time on the Metabase BI dashboard. Under the relatively complex query conditions demonstrated, a full table scan of 4 million rows returns query results in just 11 milliseconds. The Singdata Lakehouse solution does not require an additional acceleration engine for query acceleration, eliminating the need to synchronize and replicate an extra copy of the data, thereby significantly reducing overall costs.
Next, let's examine the query response under high concurrency. Singdata Lakehouse employs a storage-compute separation architecture. On the query computation side, different cluster types support various query loads:
- General-purpose Clusters: Optimized for batch processing.
- Analytical Clusters: Highly efficient for online real-time subqueries.
Singdata also offers excellent resource elasticity. You can set different cluster specifications and scaling methods, configure the number of concurrent queries, and the number of instance replicas to achieve dynamic scaling. For example, if the source has 8 concurrent queries, only 1 query instance is needed. By setting the elasticity to 2 replicas, when the concurrency exceeds 8, the system will automatically scale out to the second replica to handle the additional traffic. The entire process requires no manual intervention.
Additionally, Singdata Lakehouse provides an auto-start and auto-stop feature. In terms of resource pricing, the product operates on a pay-as-you-go model in the SaaS mode. For example, for BI reports, when there is no usage or traffic during the night, the cluster will be automatically stopped, incurring no costs. This helps avoid idle resource waste and saves on expenses.
Summary
Singdata Lakehouse, based on one-stop product capabilities, provides solutions for real-time synchronization and real-time analysis scenarios, addressing the complex situations of source databases. The product supports various data sources such as MySQL, PostgresSQL, SQLServer, etc., meeting the synchronization requirements in heterogeneous source databases, providing relatively complete high-performance synchronization capabilities, and comprehensive supporting operation and maintenance monitoring capabilities to ensure stable data production. In terms of cost, compared to traditional synchronization solutions from leading cloud vendors, Singdata can achieve overall cost savings of over 50%. In terms of performance, it has lower end-to-end synchronization latency, usually within 20 seconds; and faster analytical query response speeds, such as achieving a query response speed of 10 milliseconds for relatively complex SQL queries. Based on Singdata Lakehouse's product capabilities, it can provide enterprises with better data freshness, enabling business decisions to be made faster and maintaining a leading position in the competition.
Appendix
For more detailed usage guidelines on the multi-table real-time synchronization feature, please refer to this help document.