Real-time Multi-table Synchronization and Dynamic Table Implementation for Change Data Capture (CDC) and Data Processing through Singdata Lakehouse
Overview
In this quick start guide, we will explore how to use customer transaction data stored in a PostgreSQL database, import the data into Singdata Lakehouse tables through real-time multi-table synchronization, process the data in real-time using dynamic tables, and further perform visual data exploration and conversational data analysis using Singdata Lakehouse's built-in DataGPT. This will achieve real-time end-to-end data ingestion, data processing, and data analysis to gain insights into customer transactions.
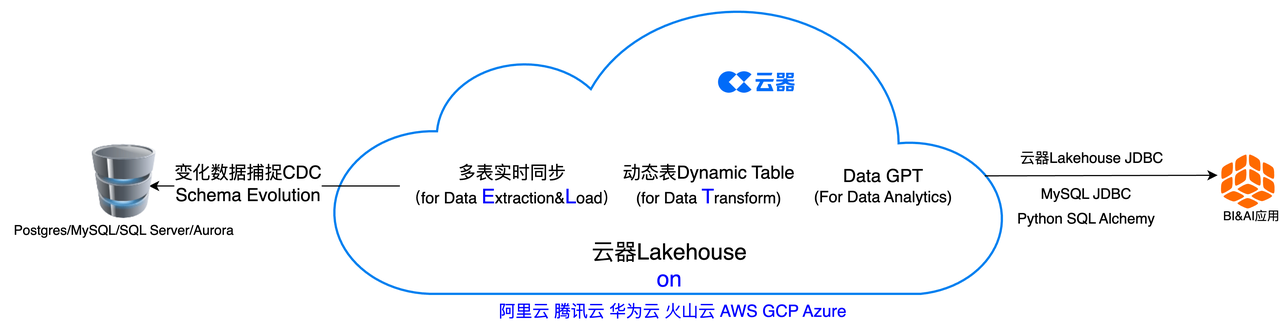
From an ELT perspective, Singdata Lakehouse's real-time multi-table synchronization achieves data extraction (Data Extraction) and loading (Load) based on CDC, and during this process, schema evolution is realized, meaning the synchronization content will include changes in the structure or schema of the source database. Dynamic Table implements data transformation (Data Transform) in a brand-new way.
Environment Preparation:
-
Docker installed on the local machine
-
Tools available to connect to the PostgreSQL database
- For example, Visual Studio Code or DBV/DBGrid, and Python code, etc.
-
Familiarity with basic Python and SQL
-
Familiarity with using data science Notebooks
-
An existing Singdata account, or go to the Singdata Technology registration page and register for a free account. After registration, you can directly log in to the Singdata Lakehouse Web console.
Singdata Lakehouse Environment
Overview
You will use Singdata Lakehouse Studio (the web interface of Singdata Lakehouse) to create Singdata Lakehouse objects (virtual compute clusters, spaces/databases, schemas, database schemas, users, etc.).
Create Objects and Load Data
- Navigate to Development -> Tasks, click
+to create a new workspace and worksheet task, then select SQL Worksheet
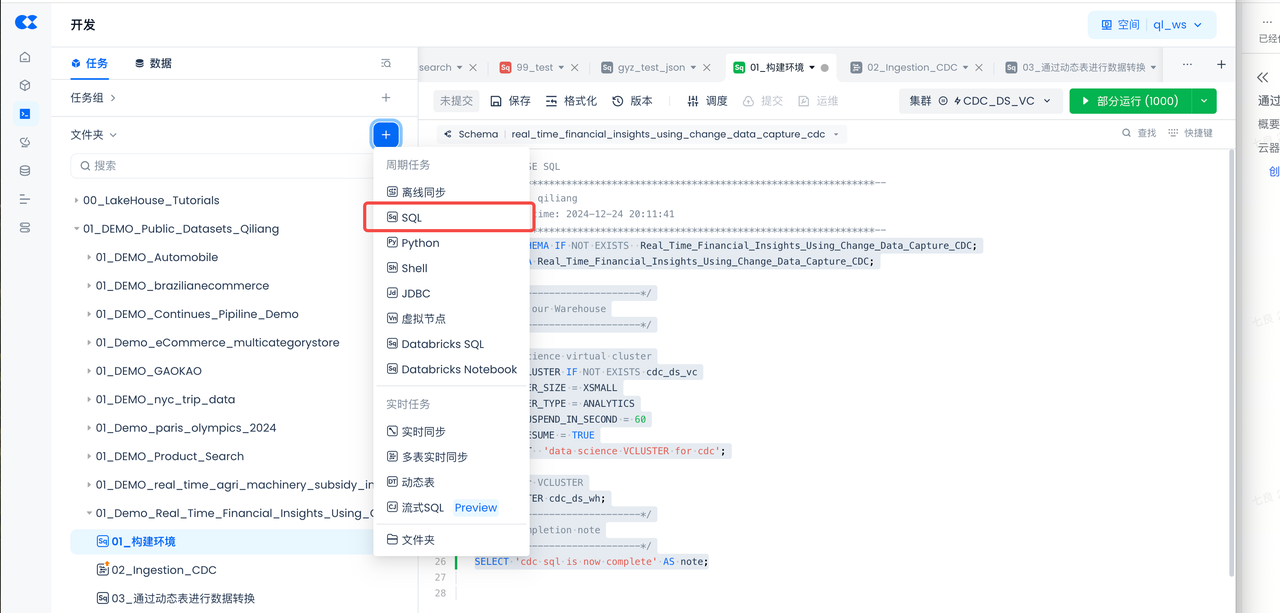
- Workspace Name: 01_Demo_Real_Time_Financial_Insights_Using_Change_Data_Capture_CDC
- Task Name: 01_Setup Environment
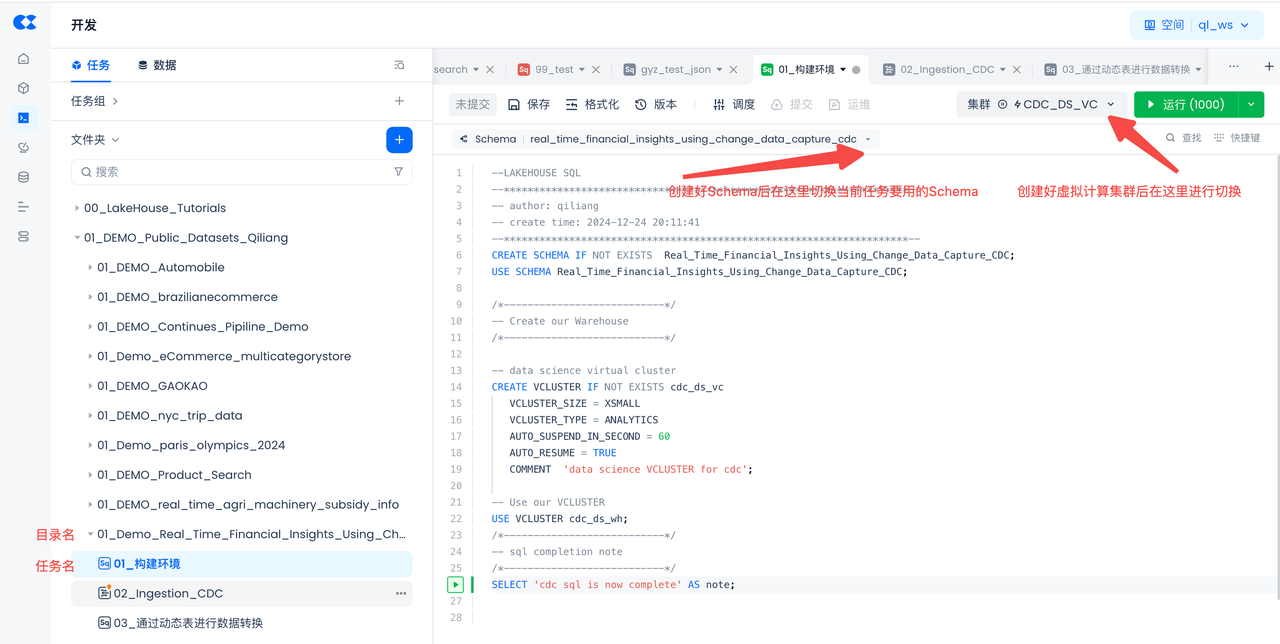
- Copy and paste the following SQL script to create Singdata Lakehouse objects (virtual compute clusters, database schemas), then click "Run" at the top of the worksheet
Postgres Environment
Overview
In this section, we will set up a PostgreSQL database and create tables to simulate customer transaction data for a financial company.
Start Database Instance
Before starting this step, make sure you have installed Docker Desktop for Mac, Windows, or Linux. Ensure that Docker Compose is installed on your machine. Docker Compose.
- To start a PostgreSQL database using Docker, you need to create a file named docker-compose.yaml. This file will contain the configuration for the PostgreSQL database. If you have another container client, start the container and use the PostgreSQL image below.
- Open your preferred IDE (such as VS Code), and copy and paste the following content by copying and pasting this file:
- Open the terminal and navigate to the directory where the docker-compose.yaml file is located. Run the following command to start the PostgreSQL database:
Connect to the Database
To connect to the pre-configured database using Visual Studio Code or DBV/DBGrid/PyCharm or any IDE of your choice for database connection, follow these steps using the provided credentials:
-
Open your chosen tool to connect to the PostgreSQL database
- For VSCode, you can use the PostgreSQL extension
- For PyCharm, you can use the Database tools and SQL plugin
-
Click the
+symbol or similar to add a data source -
Use these connection parameters:
- User:
postgres - Password:
postgres - URL:
jdbc:postgresql://localhost:5432/
- User:
-
Test the connection and save
-
To allow Singdata Lakehouse Studio to access the Postgres database via the public network, be sure to set up public NAT mapping for the Postgres database.
Load Data
- Run the following postgres script in PostgreSQL to create the database, schema, and tables:
-
Download these csv files and save them to a directory on your local computer:
-
Postgres Data Loading Method 1, Load via PG's Copy Command
- Before loading the data into the PostgreSQL database, we need to move the files from the local computer to the Docker container.
- Navigate to your terminal and use the following command to get the Docker container ID:
-
-
To copy the CSV file to the container, run the following command in the terminal, replacing the file path with the actual file path, and replacing
container_idwith the actual container ID from the previous command: 5. ```Shell docker cp /Users/your_username/Downloads/customers.csv container_id:/tmp/customers.csv docker cp /Users/your_username/Downloads/merchants.csv container_id:/tmp/merchants.csv docker cp /Users/your_username/Downloads/products.csv container_id:/tmp/products.csv docker cp /Users/your_username/Downloads/transactions.csv container_id:/tmp/transactions.csv -
Return to the PostgreSQL console and run the following SQL command to load the file from the container into the PostgreSQL table:
5. Next, ensure to run the CREATE PUBLICATION command to enable logical replication of the tables in the schema raw_cdc. This will allow the real-time synchronization task below to capture changes made to the tables in the PostgreSQL database:
Create and Start Singdata Lakehouse CDC Multi-Table Real-Time Sync Task
Overview
You will use Singdata Lakehouse Studio to create a multi-table real-time sync task in a no-code manner through interface operations, loading data from Postgres tables to Singdata Lakehouse tables.
Create Postgres Data Source
Navigate to Management -> Data Source, click "New Data Source" and select Postgres to create a Postgres data source, making Postgres accessible to Singdata Lakehouse.
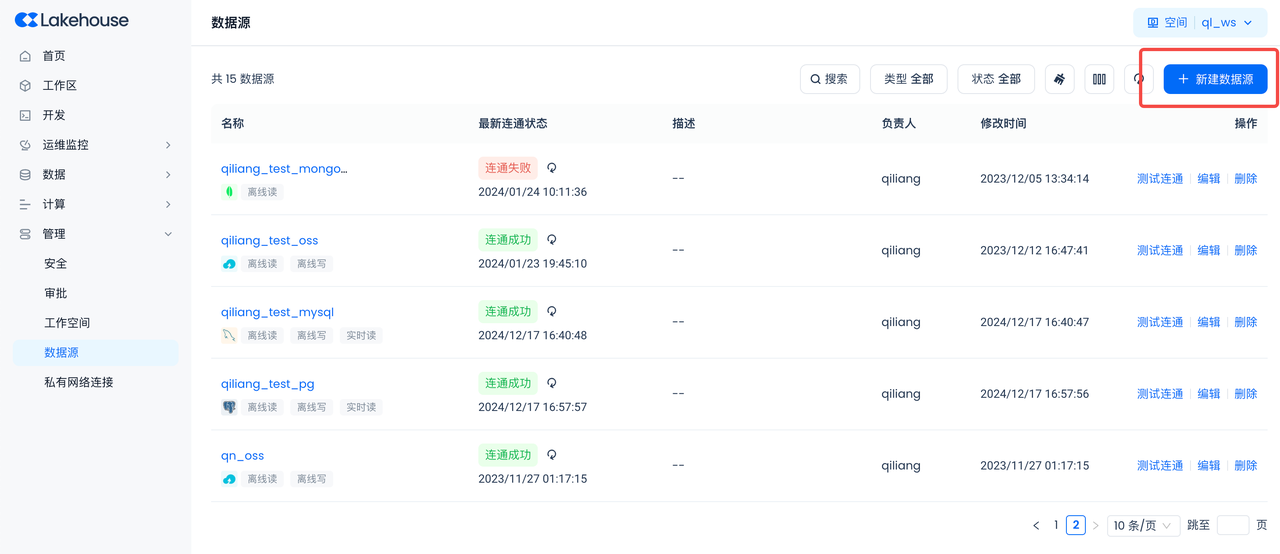
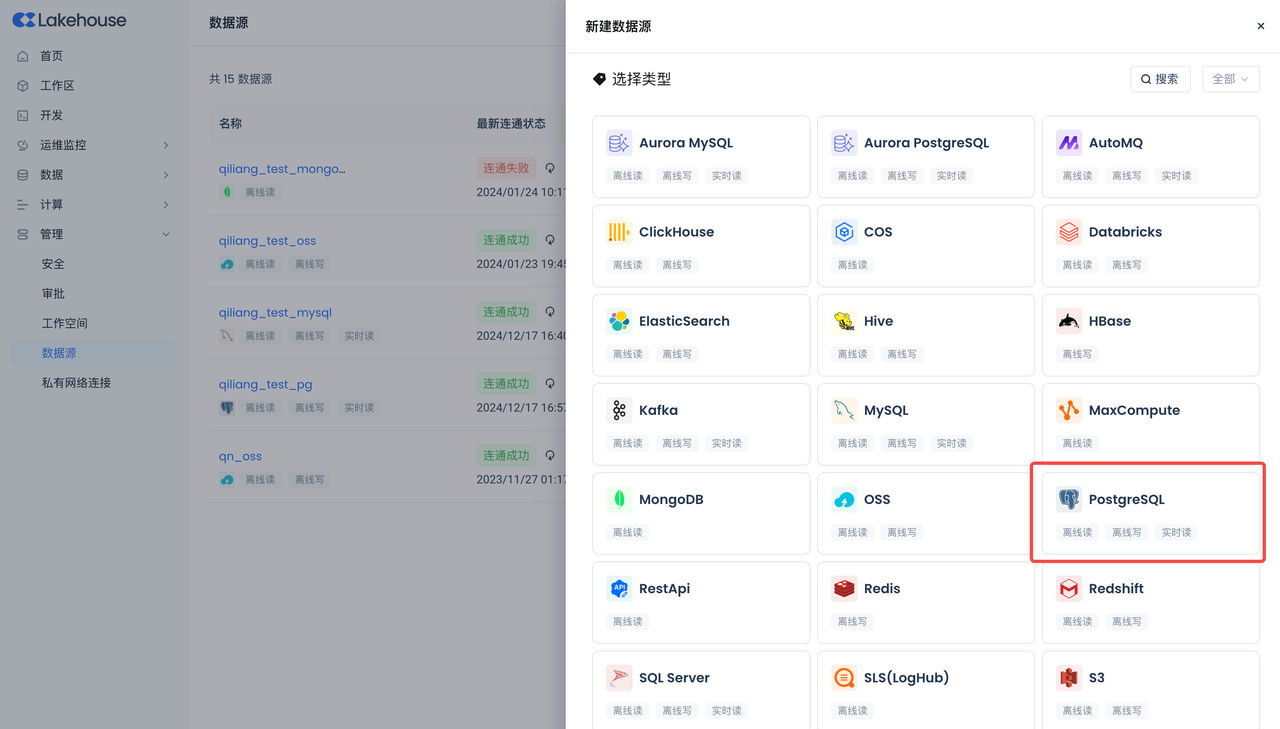
- Data Source Name: PG_CDC_DEMO
- Connection Parameters: Same as the connection parameters in the previous Postgres environment section.
- Please ensure to configure the correct timezone of the database to avoid data sync failure.
Create Multi-Table Real-Time Sync Task
Navigate to Development -> Tasks, click + to create a new workspace and worksheet task, then select "Multi-Table Real-Time Sync".
- Select "Multi-Table Real-Time Sync":
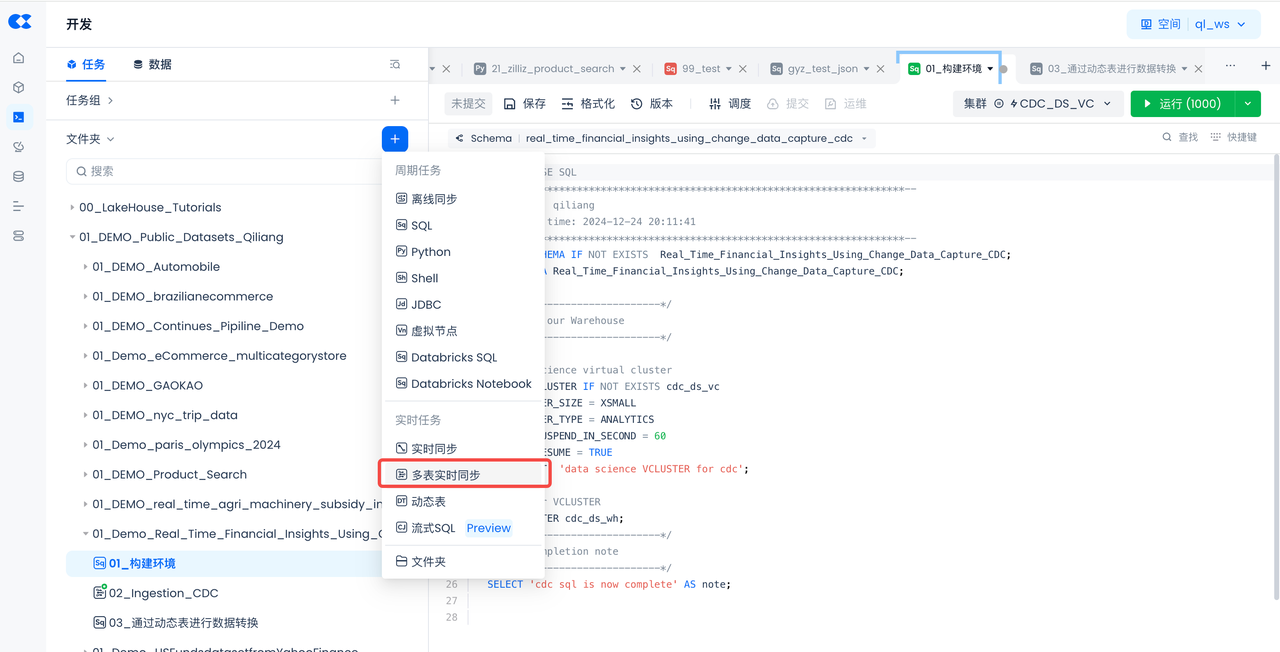
Create a multi-table real-time sync task and store it in the same directory as the previously built environment:
- Task Name: 02_Ingestion_CDC
- Source Data: Select Postgres
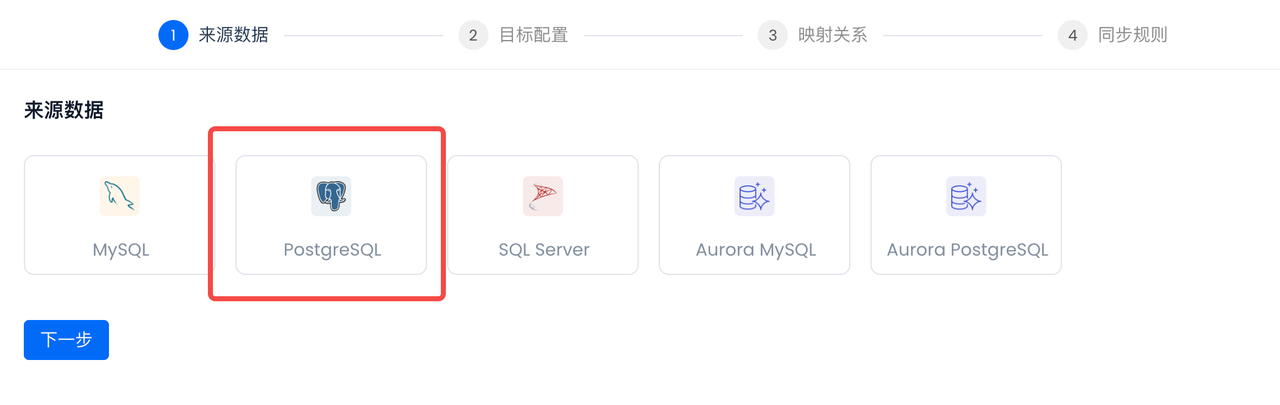
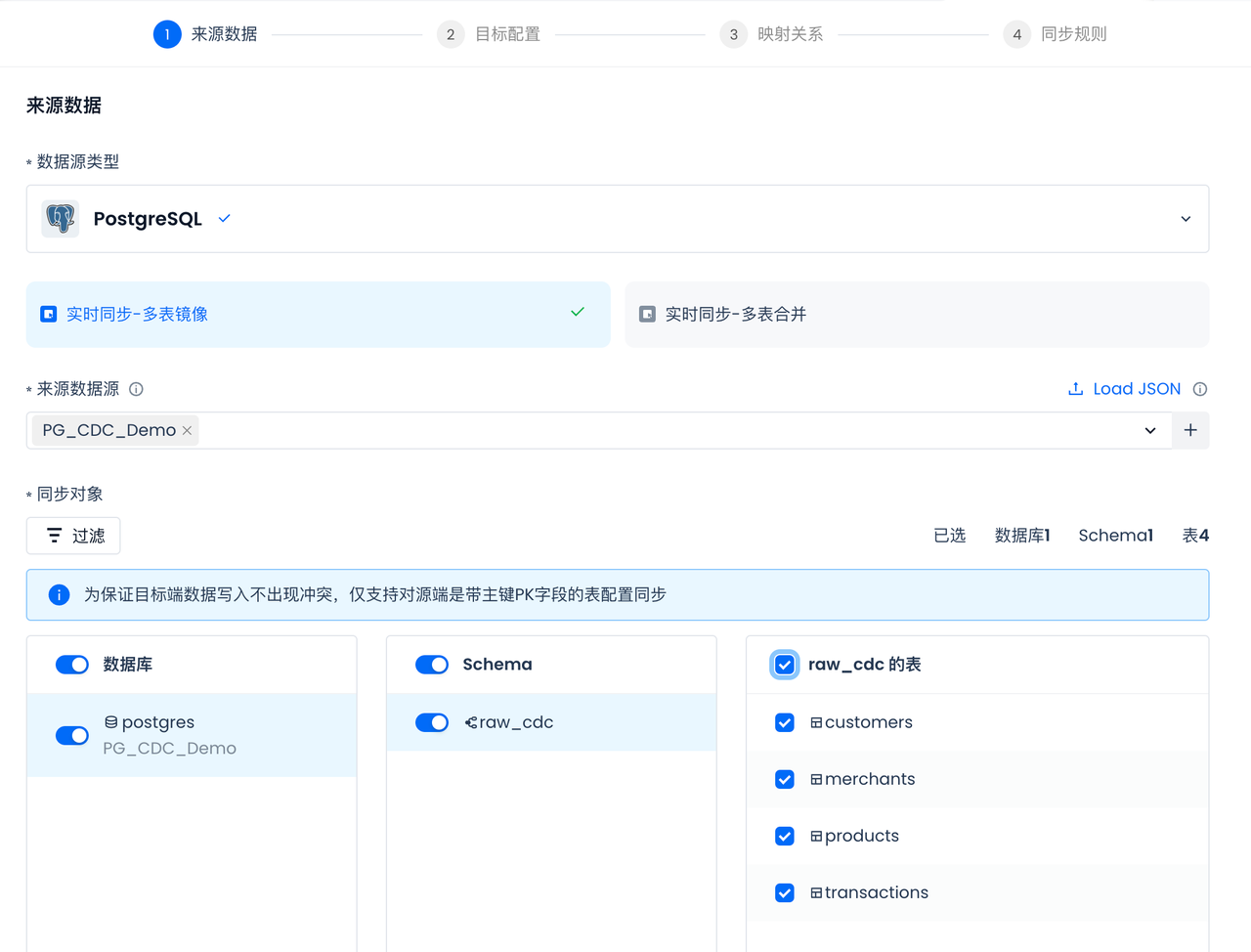
Select the Postgres data source created in the previous step: PG_CDC_DEMO. After selection, the accessible databases, Schema, and tables of the data source will be automatically displayed, and all tables will be selected (all tables need to be synced):
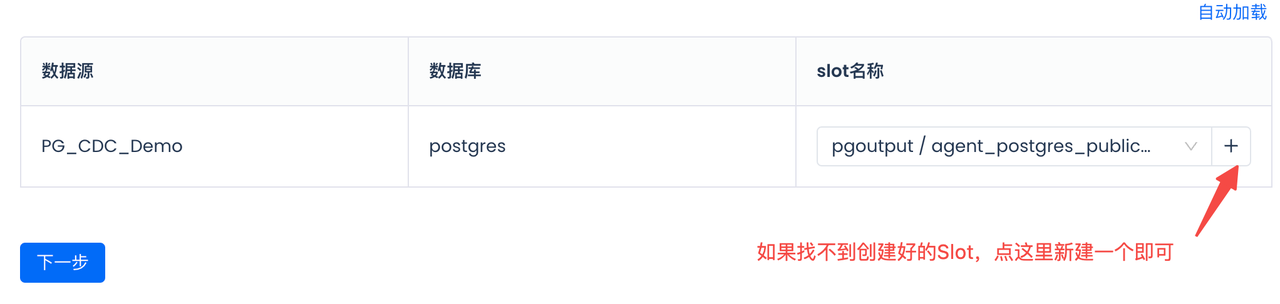
Select or create a new SlotName for CDC sync. Please note that the same Slot should not be shared by two tasks to avoid data loss:
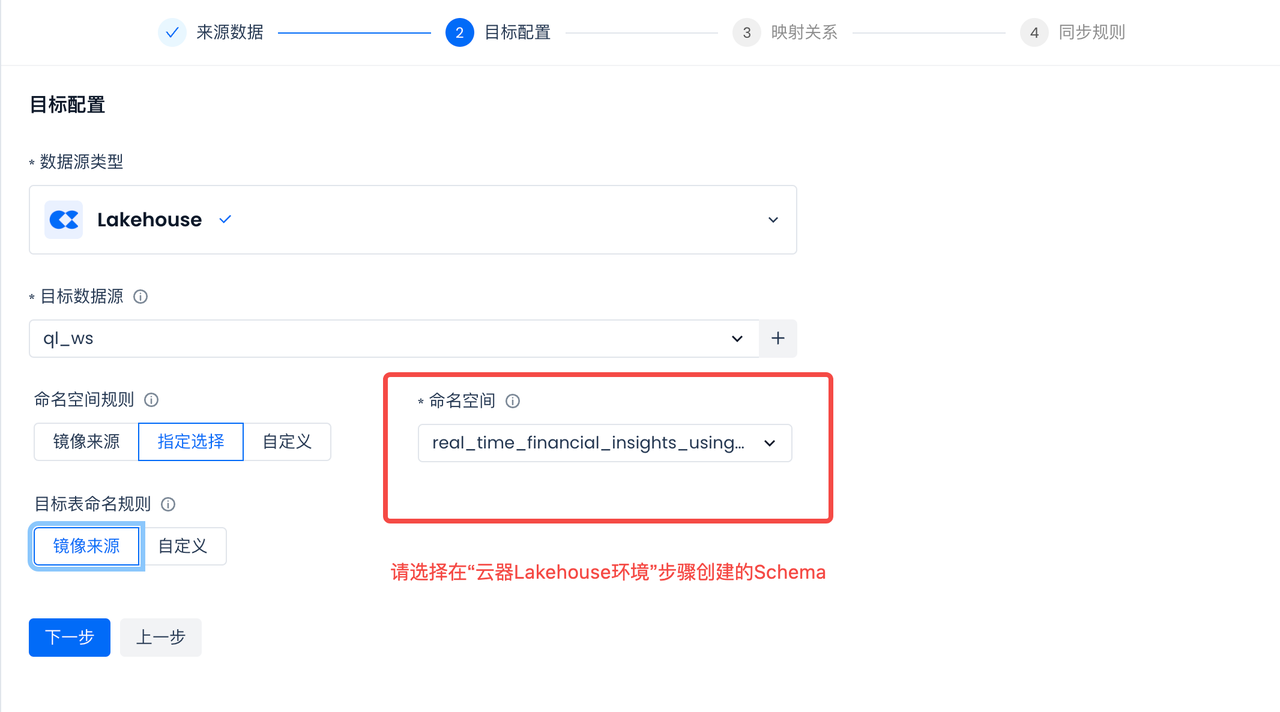
Target Table Configuration:
Select the existing Schema under the target data source as the storage location for the target table.
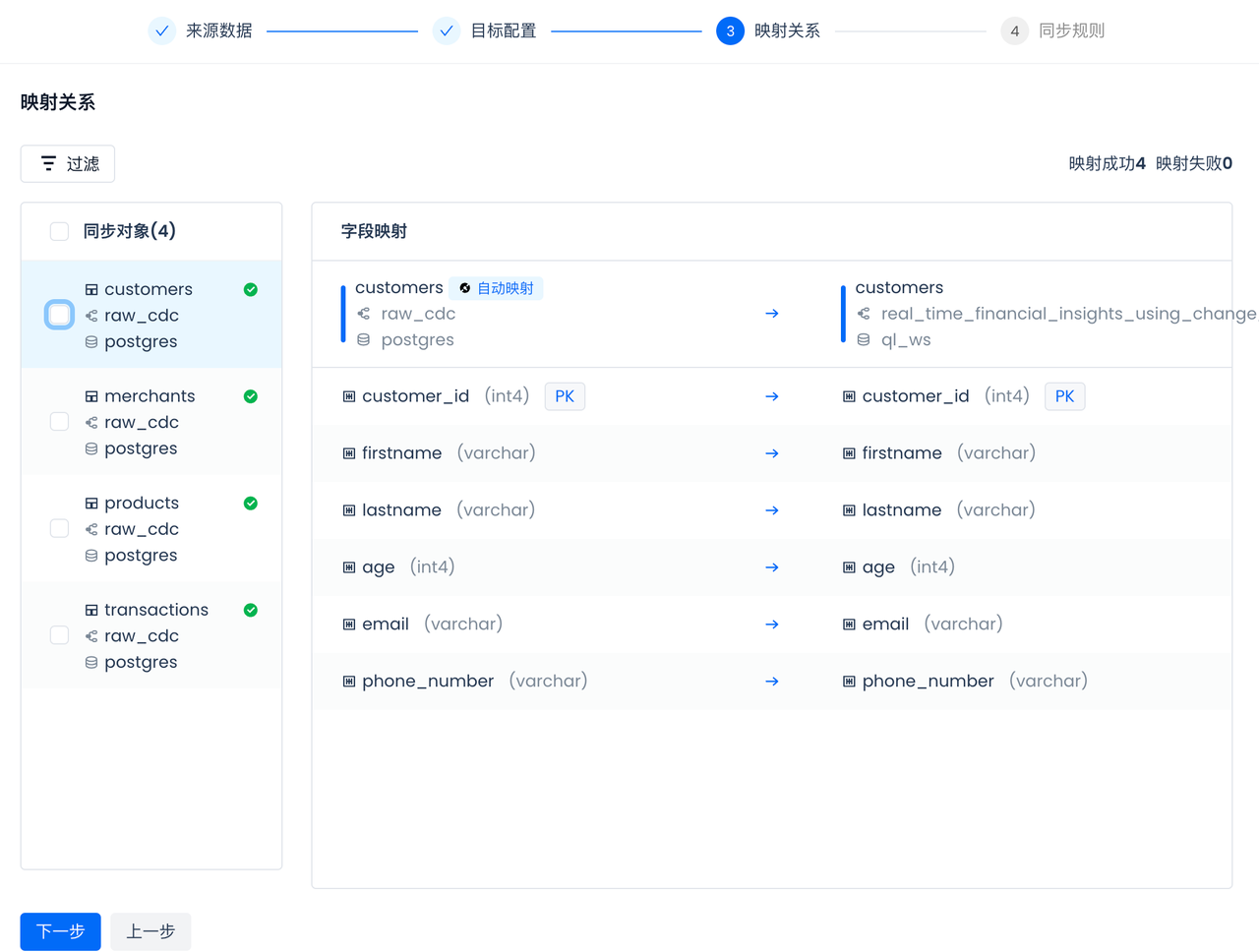
Configure and check the table and field mapping relationships:
Singdata Lakehouse will automatically form the mapping of tables and fields, including data type mapping. If there is no corresponding table in the selected Singdata Lakehouse namespace, the multi-table real-time sync task will automatically check and create the table when the task starts, without the need for manual pre-creation. CDC sync requires primary keys in the source tables, and the multi-table real-time sync will automatically create corresponding primary keys in the Lakehouse target tables.
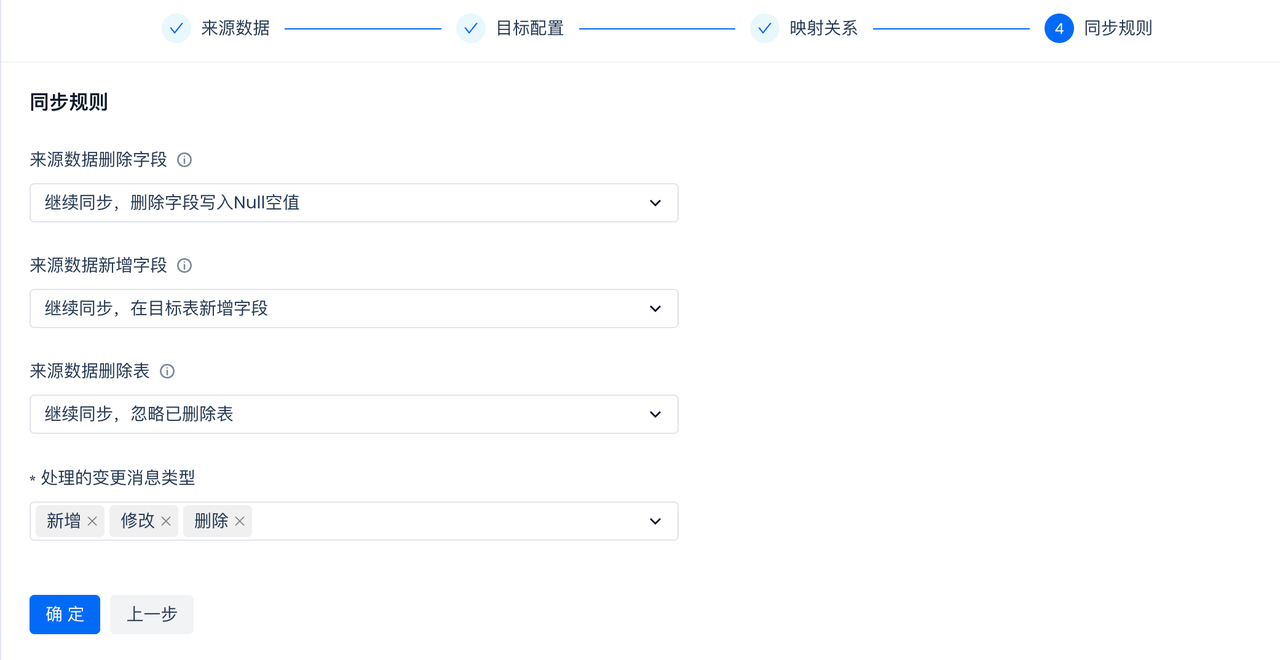
Configure Sync Rules:
Schema Evolution refers to the process of modifying and adapting the structure or schema of a database over time and as needs change in a database management system. Schema evolution typically involves changes to the structure of database tables, fields, data types, relationships, and constraints, without interrupting the operation of existing systems or causing data loss.
In the sync rules of real-time sync tasks, you can configure automatic handling strategies for changes to source tables and fields:
- Set the behavior after deleting fields from the source table.
- Set the behavior after adding fields to the source table. Renaming fields is considered as field deletion, and the renamed fields are recognized as new fields.
- Set the behavior after adding fields to the source table.
- Set the behavior when the data source sync object is deleted. Renaming tables is considered as deletion, and the renamed tables are considered as new tables.
Additionally, the sync rules also support setting the types of source change messages that need to be processed. Please set as needed. For example, in some scenarios, it is expected that the data on the target side will always accumulate, without processing the "delete" changes from the source side. In this configuration, simply remove the "delete" option.
Submit and Start Multi-Table Real-Time Sync Task
- Submit the multi-table real-time sync task:

- Operate and Maintain the multi-table real-time task:
- Start the multi-table real-time task:
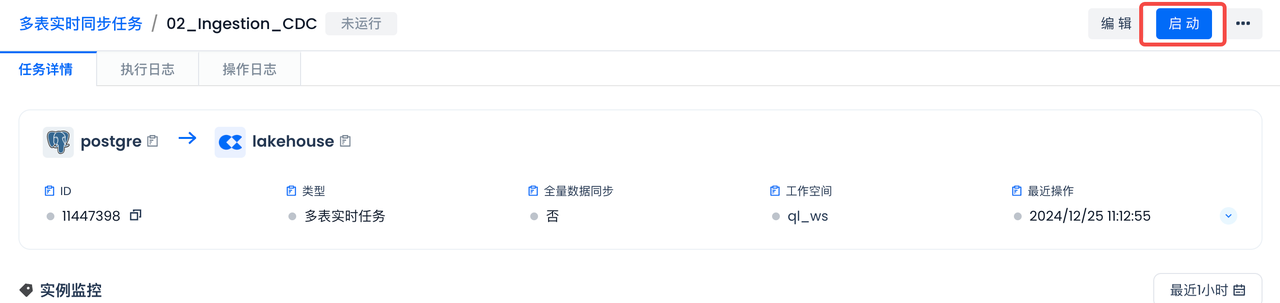
- And select "Full Data Sync":
Whether to perform a full data sync before incremental sync. Please note that this configuration can only be selected the first time the task is started after going live. !
{kind=link}
View Full Sync Status
In the previous "Postgres Environment" step, data was loaded into the four Postgres tables using either the Copy method or a Python script. The "Full Data Sync" selected in the previous step achieves full data synchronization before the incremental data synchronization begins.
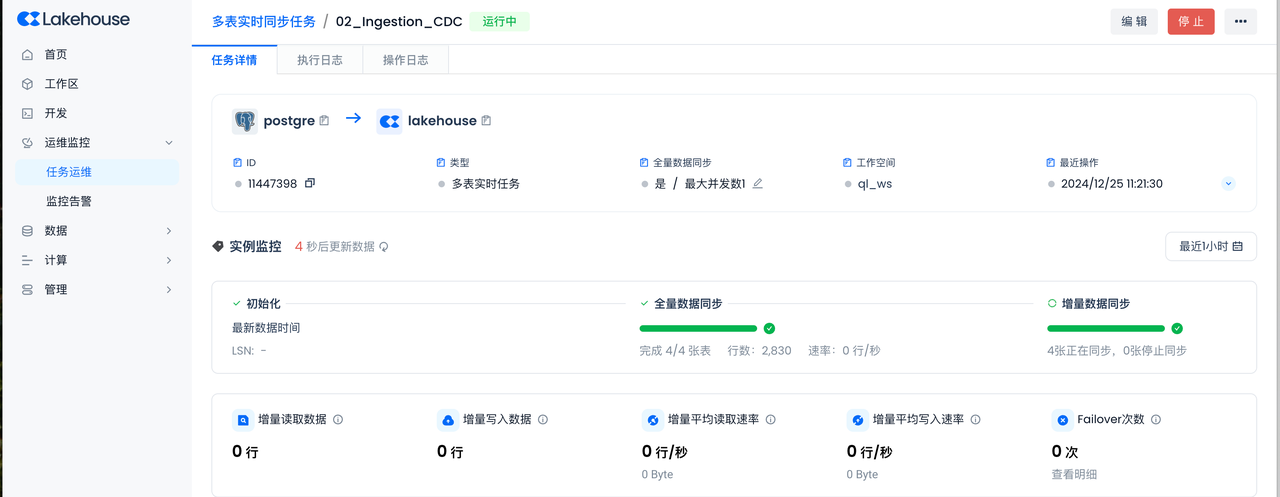
The full sync status and incremental sync status of all 4 tables are normal, with no Failover occurring.
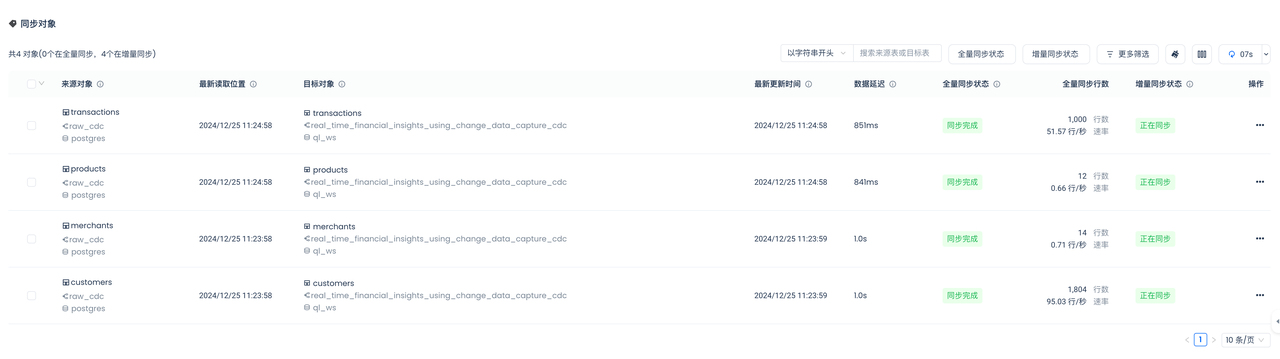
You can see that the full sync has been completed. After that, the incremental sync status will automatically switch to "Syncing" without manual intervention.
Incremental Sync Process of Multi-Table Real-Time Sync
Insert New Data into the Data Source
Insert data into the source table in Postgres to achieve incremental data synchronization through the already started real-time multi-table sync task, and check the sync status of the real-time multi-table sync task.
During the incremental sync process of multi-table real-time sync, the Java Real-Time Programming Interface of Lakehouse is used to write data in real-time into the primary key table of Lakehouse.
Copy the following code into the Notebook and run it, or download it directly:
- Create a database connection
- Set parameters for incremental data generation
- Data Loading Functions
- Call function to insert transaction data
- Closing cursors and connections
View Incremental Sync Status
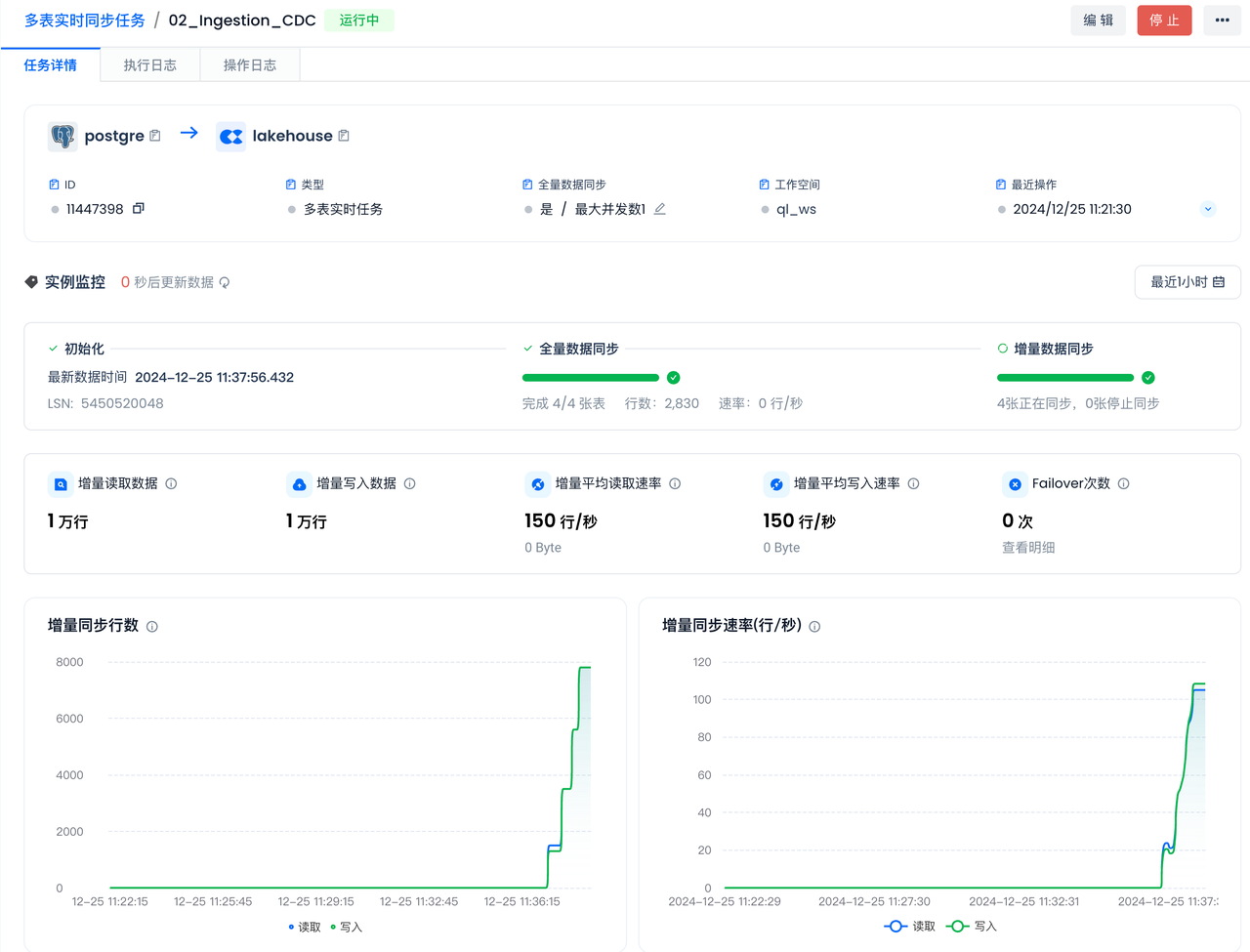
Process Multiple Tables' Real-Time Synced Data via Dynamic Table
Overview
You will use Singdata Lakehouse Studio to create a Dynamic Table, which will process data in real-time that is synced from Postgres tables to Singdata Lakehouse via multiple tables.
Create Dynamic Table
Navigate to Development -> Tasks, and click "+ Select Dynamic Table".
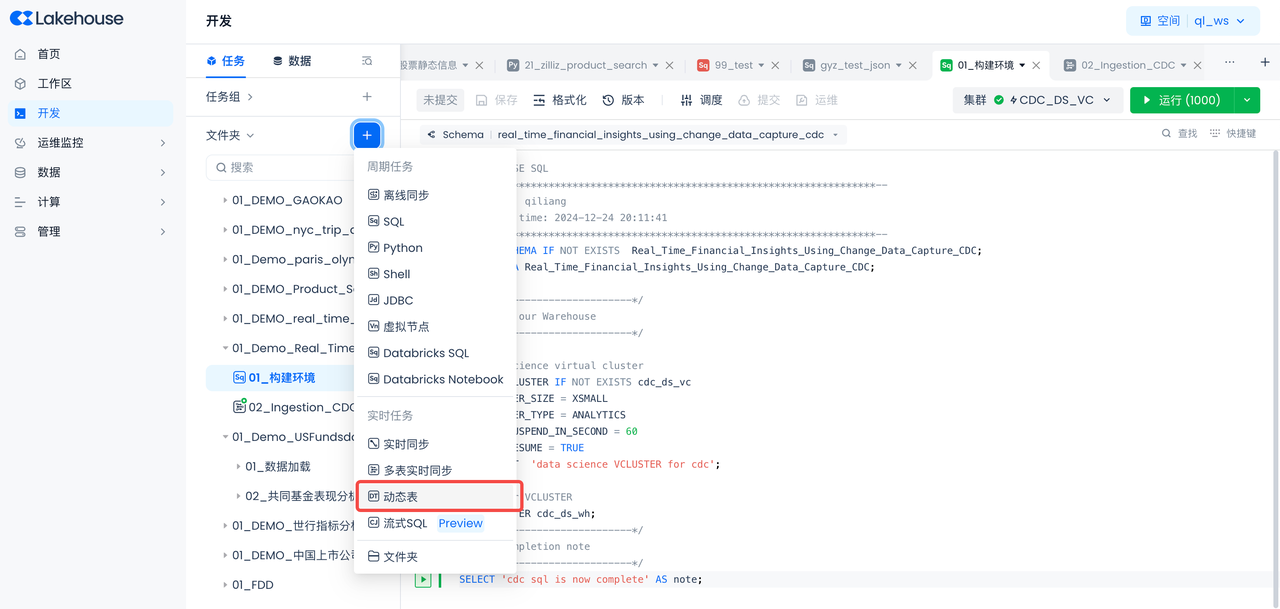
- Task Name: 03_customer_purchase_summary
- Schema Selection: real_time_financial_insights_using_change_data_capture_cdc
- Enter Table Name: customer_purchase_summary
- Enter the following in the SQL code:
This SQL query specifically functions to retrieve detailed transaction records from the transactions table by joining multiple tables and obtaining related information from the customers, products, and merchants tables. Here is a detailed explanation:
-
Extract transaction records from the `` table:
t.transaction_id: Retrieve the unique identifier for each transaction.t.customer_id: Retrieve the identifier of the customer associated with the transaction.t.product_id: Retrieve the identifier of the product involved in the transaction.t.merchant_id: Retrieve the identifier of the merchant providing the product or service.t.transaction_dateandt.transaction_time: Retrieve the date and time when the transaction occurred.t.quantity: Retrieve the quantity of products purchased in the transaction.t.transaction_card: Retrieve the type of card used for the transaction (e.g., credit card or debit card).t.transaction_category: Retrieve the category of the transaction (e.g., purchase or refund).
-
Extract customer information from the `` table:
- Use
JOIN customers c ON t.customer_id = c.customer_idto join thetransactionstable with thecustomerstable and retrieve customer information associated with the transaction. c.age AS customer_age: Retrieve the customer's age and name itcustomer_age.
- Use
-
Extract product information from the `` table:
- Use
JOIN products p ON t.product_id = p.product_idto join thetransactionstable with theproductstable and retrieve product information involved in the transaction. p.product_name: Retrieve the name of the product.p.product_category: Retrieve the category of the product.t.quantity * p.price AS total_price: Calculate the total price of each transaction (quantity multiplied by product unit price) and name ittotal_price.
- Use
-
Extract merchant information from the `` table:
- Use
JOIN merchants m ON t.merchant_id = m.merchant_id AND m.merchant_category = p.product_categoryto join thetransactionstable with themerchantstable and ensure the merchant's category matches the product category. m.merchant_name: Retrieve the name of the merchant.m.merchant_category: Retrieve the category of the merchant.
- Use
Through these joins and data extractions, this query generates a detailed result set where each record contains detailed transaction information, customer information, product information, and merchant information, and calculates the total price of each transaction, thus providing a more comprehensive and in-depth transaction analysis.
Dynamic tables will directly refresh data periodically according to the life syntax, achieving the purpose of dynamic data changes.
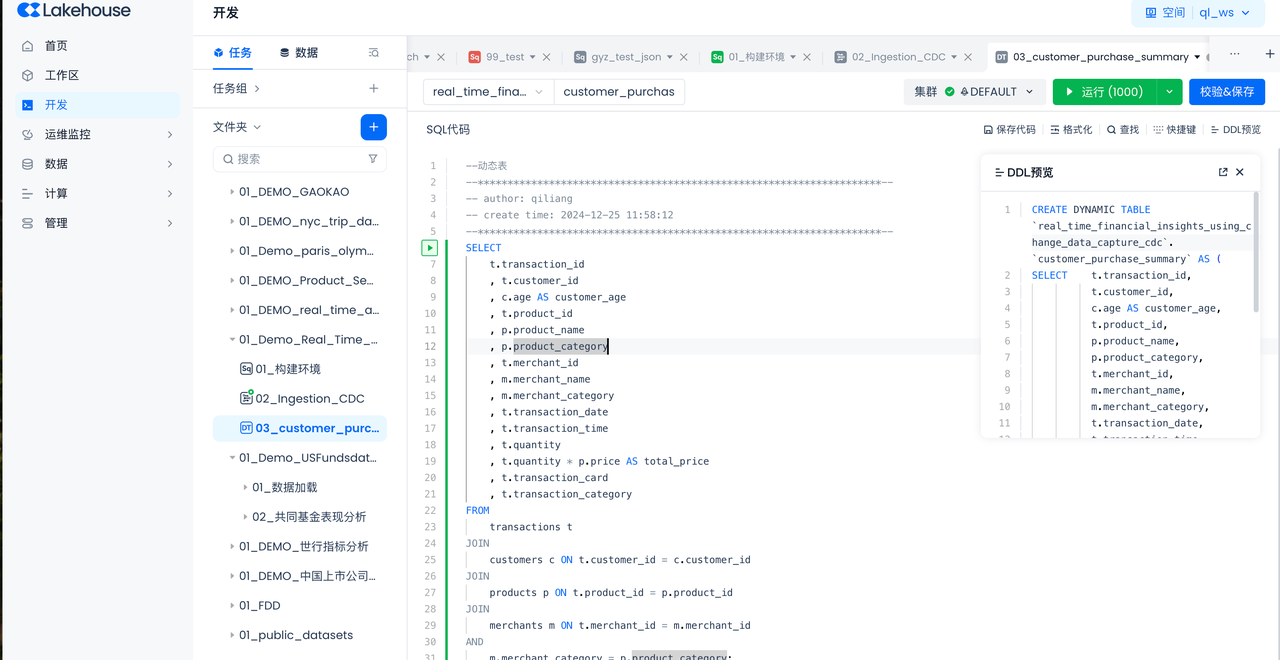
- Validate and save, select "Complete SQL Development":

-
Select the virtual cluster for dynamic table refresh before submission
Select the virtual compute cluster "CDC_DS_VS" created in the "Singdata Lakehouse Environment" step.
-
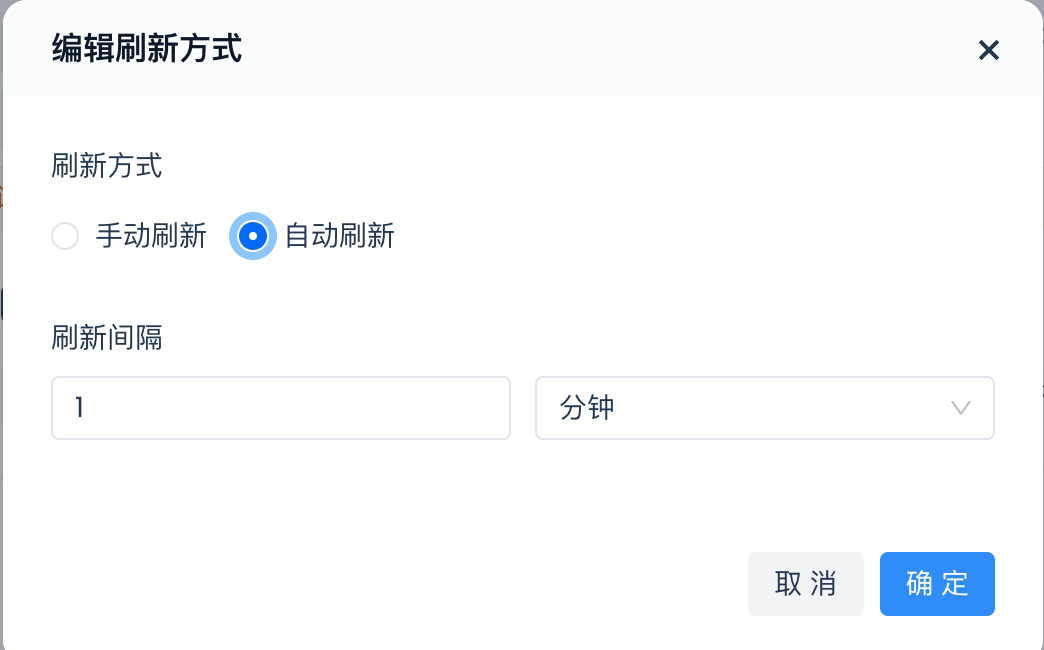
Select "Auto Refresh" before submission
Submit and complete the development of the dynamic table
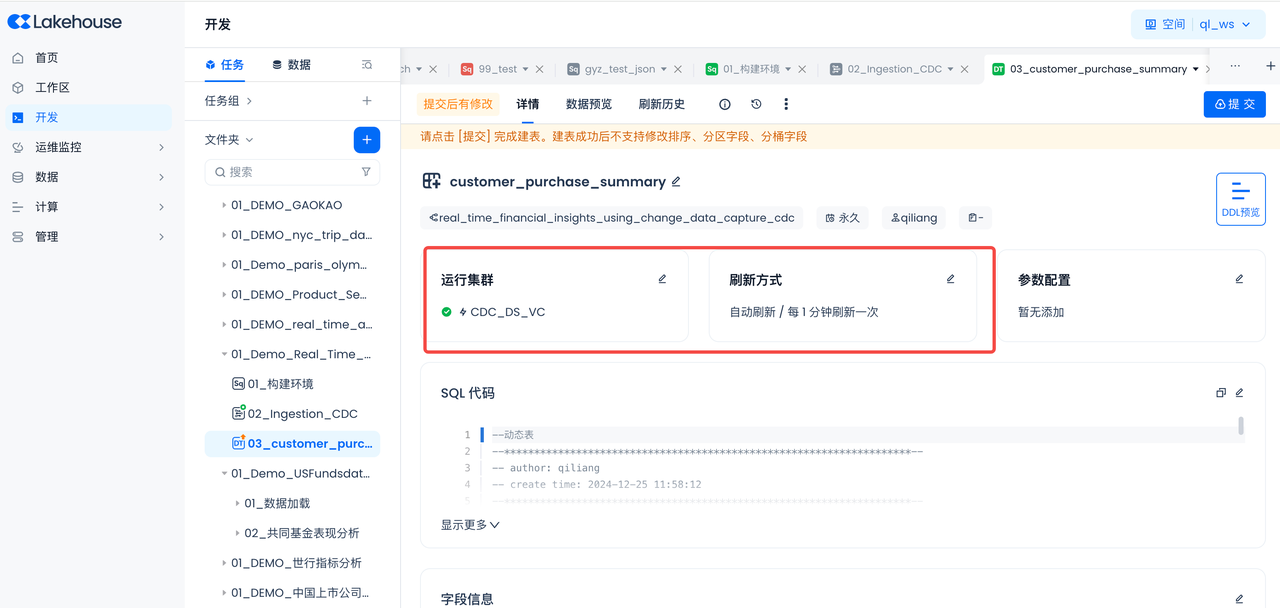
Dynamic Table Operations
After successful submission, you can go to the Operations Center to view the task details and refresh history of the current table, and support starting or stopping the current table.
- Task details:
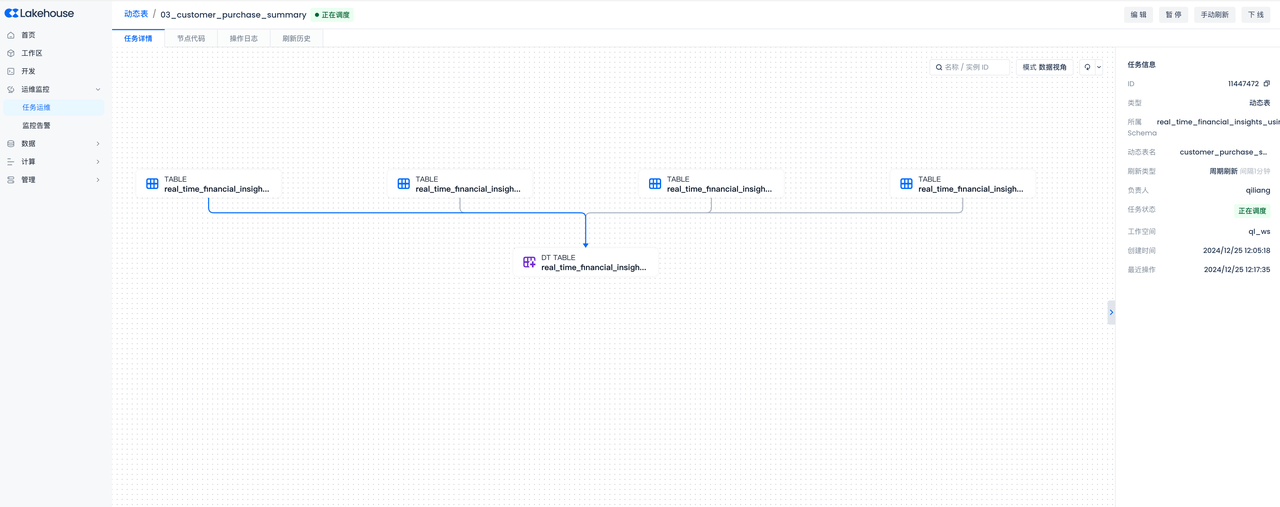
-
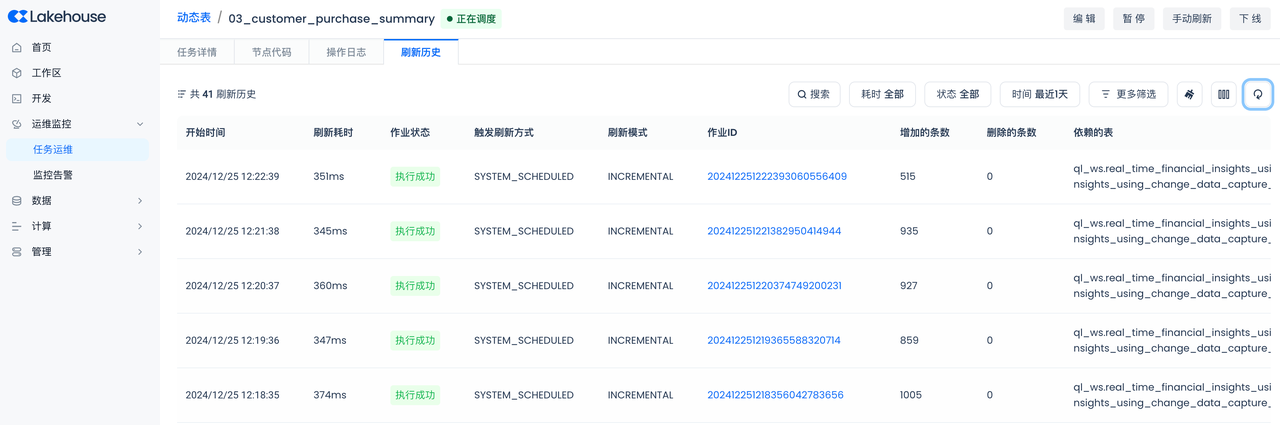
Refresh history:
You can see the number of rows added and deleted in each refresh cycle, thus understanding how the data in the dynamic table "dynamically" changes.
Conduct Q&A Data Analysis through Singdata DataGPT
Overview You will use Singdata Lakehouse DataGPT to synchronize tables from Postgres to Singdata Lakehouse in real-time and analyze them through Q&A.
Access Singdata DataGPT
Navigate to the account homepage -> DataGPT to enter Singdata DataGPT.
Create a New Analysis Domain
Build data analysis based on multiple data tables, metrics, answer builders, knowledge, and documents, and support adding users for permission isolation.
- Analysis Domain Name: CDC Transaction Data Analysis.
- After successfully creating, select "Add Data," then choose "Add Table" -> "Import Table" to add the dynamic table created in the previous section to DataGPT.
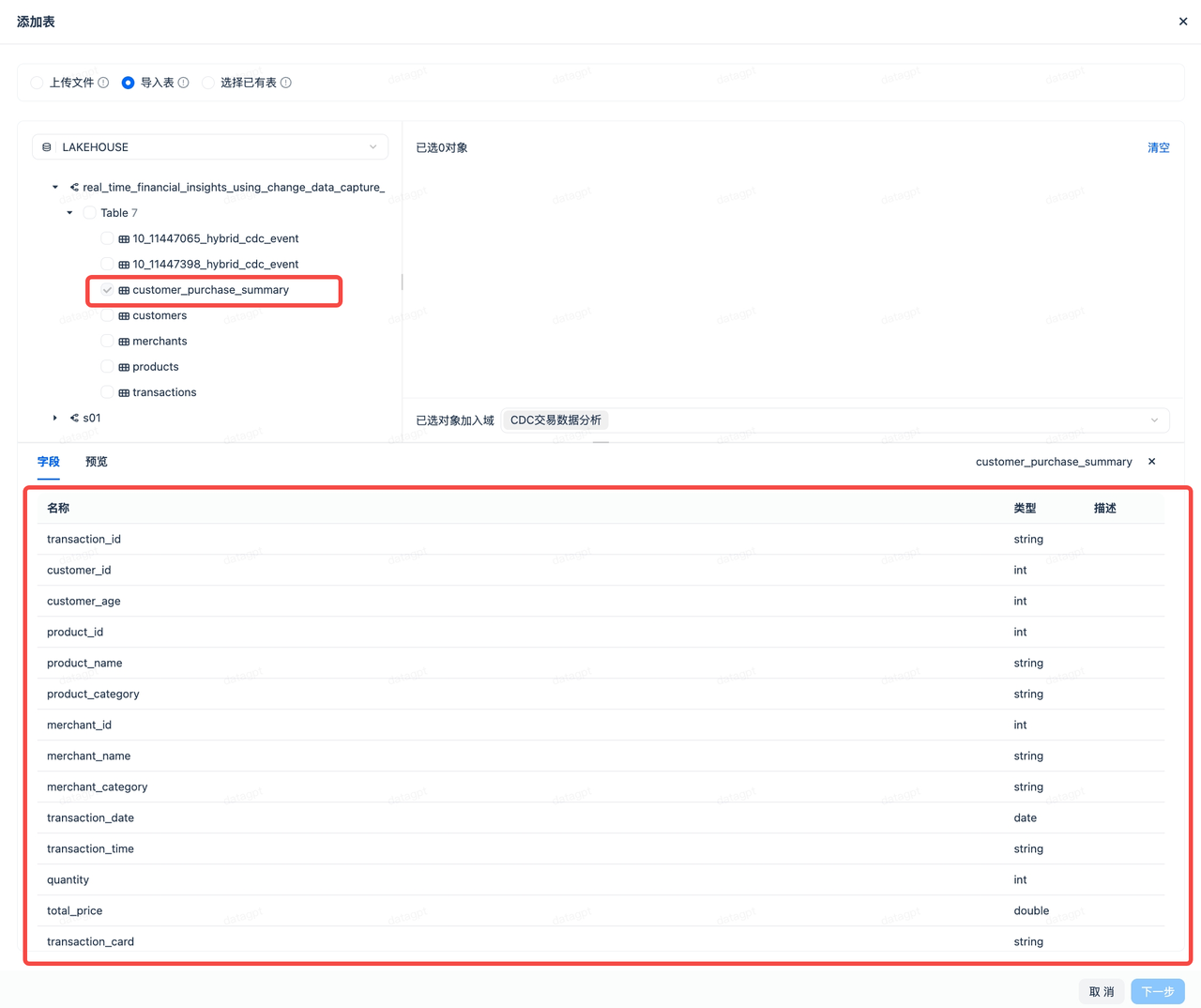
- Click the icon next to "Description," and the system will use a large model to add appropriate descriptions for each field, facilitating alignment with Chinese semantics.
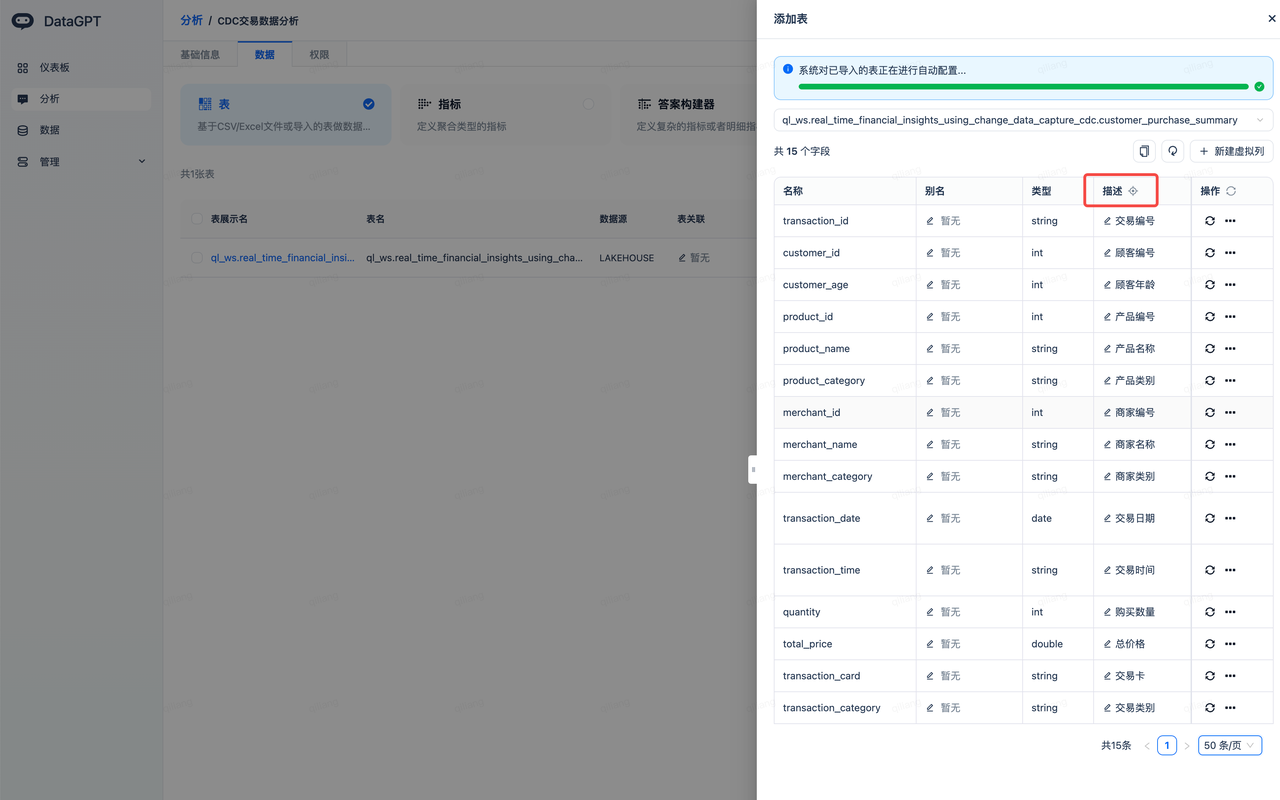
- Adopt the metrics automatically generated by the large model, complete and start the analysis:
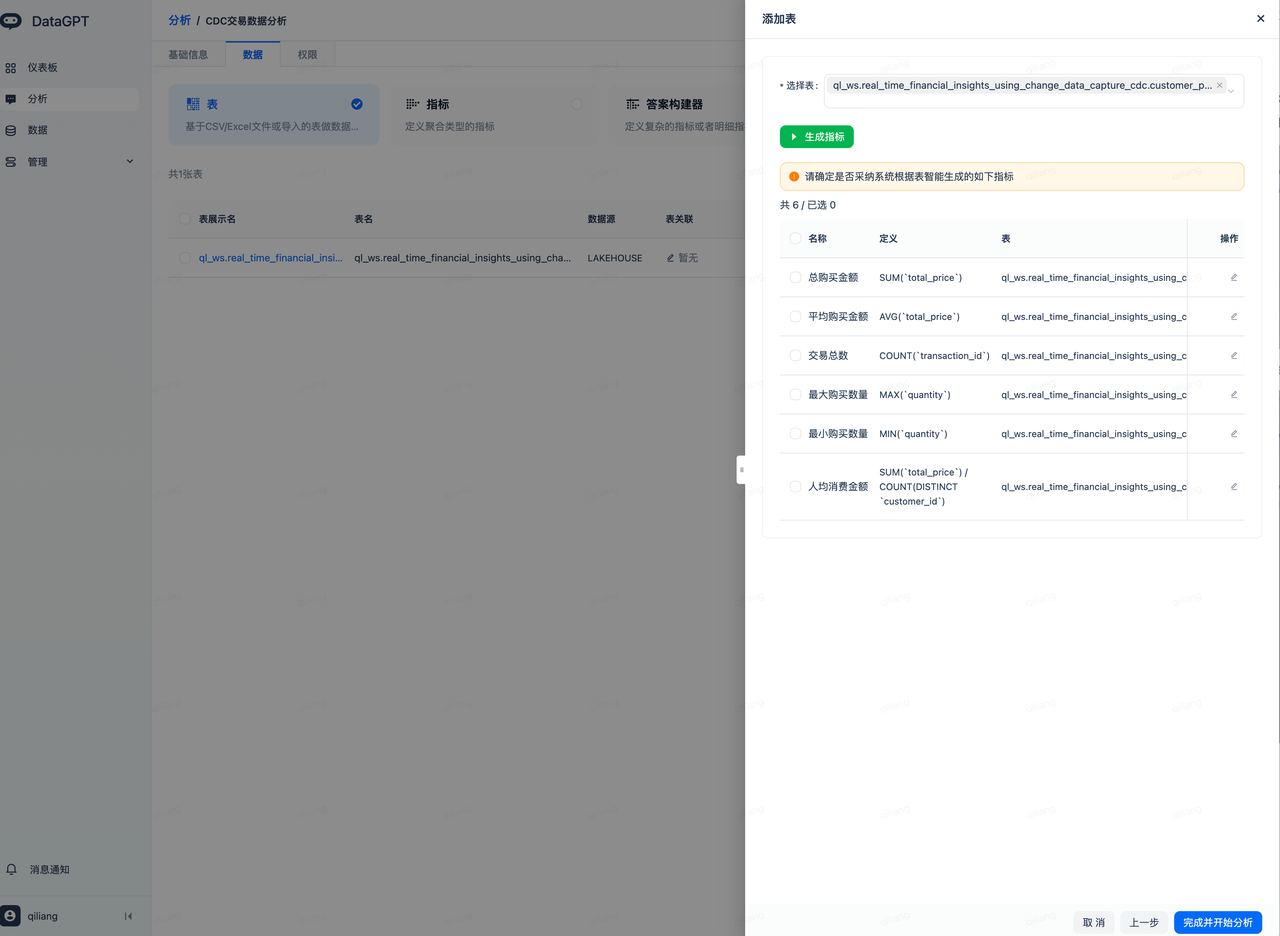
Enter the following analysis domain page to start data exploration and conversational analysis.
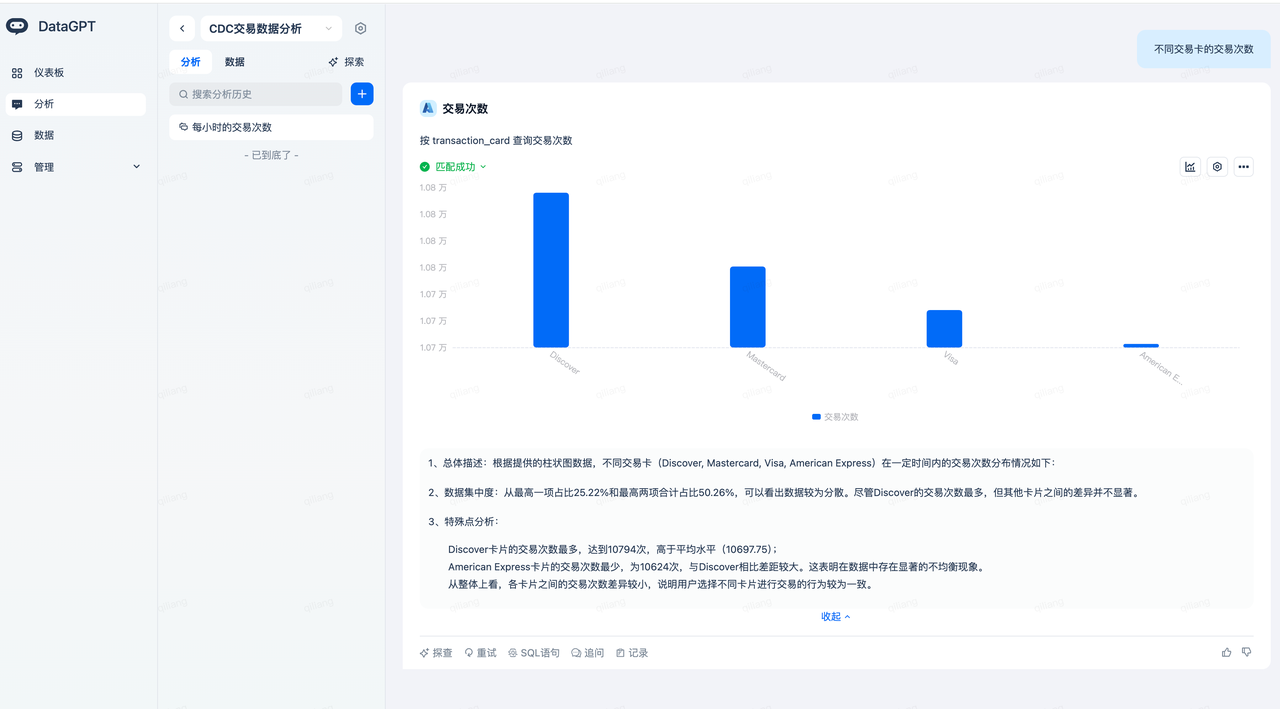
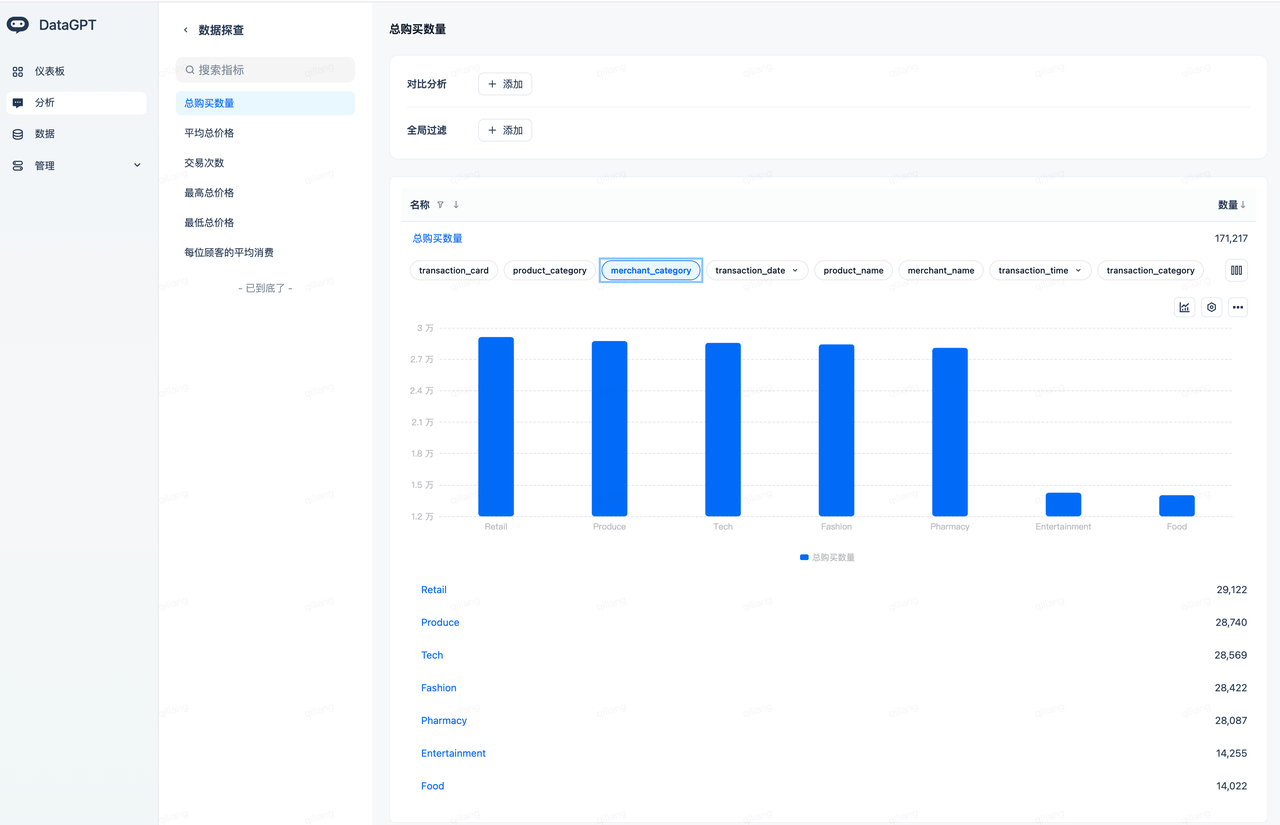
Data Exploration
Navigate to the analysis domain (select "CDC Transaction Data Analysis") -> Explore to explore data based on the automatically created metrics.
Conversational Data Analysis
Enter the question "Number of transactions for Mastercard, distributed by merchant category," and get the following analysis result:
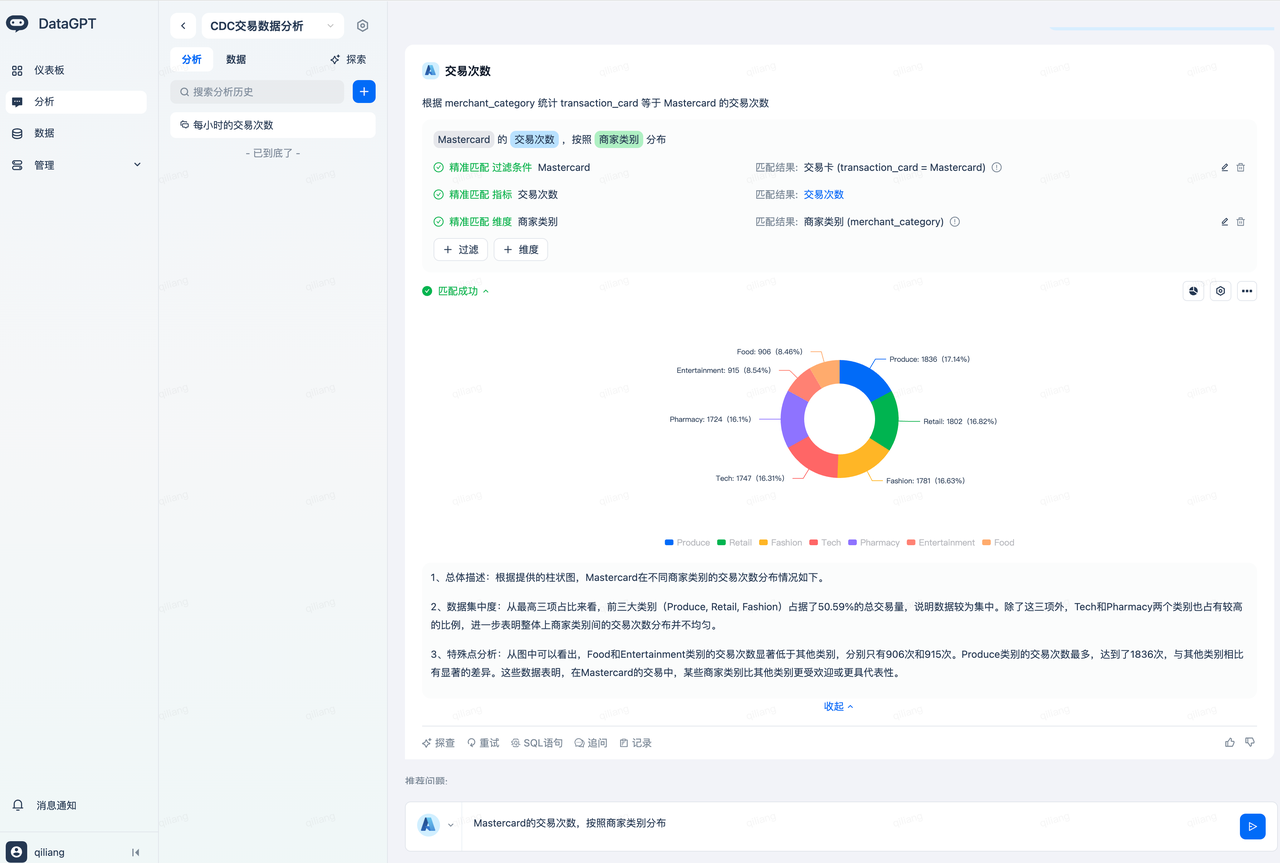
It understands that Mastercard needs to match the transaction card (transaction_card = Mastercard), thanks to DataGPT's automatic indexing of the transaction_card field values.
The number of transactions is an automatically created metric, achieving metric caliber alignment.
The merchant category corresponds to the field merchant_category, benefiting from the automatic generation of field descriptions, quickly achieving semantic alignment.
Enter the question: What is the total number of transactions for 'Disinfectant Wipes' products purchased through each channel? Get the following analysis result:
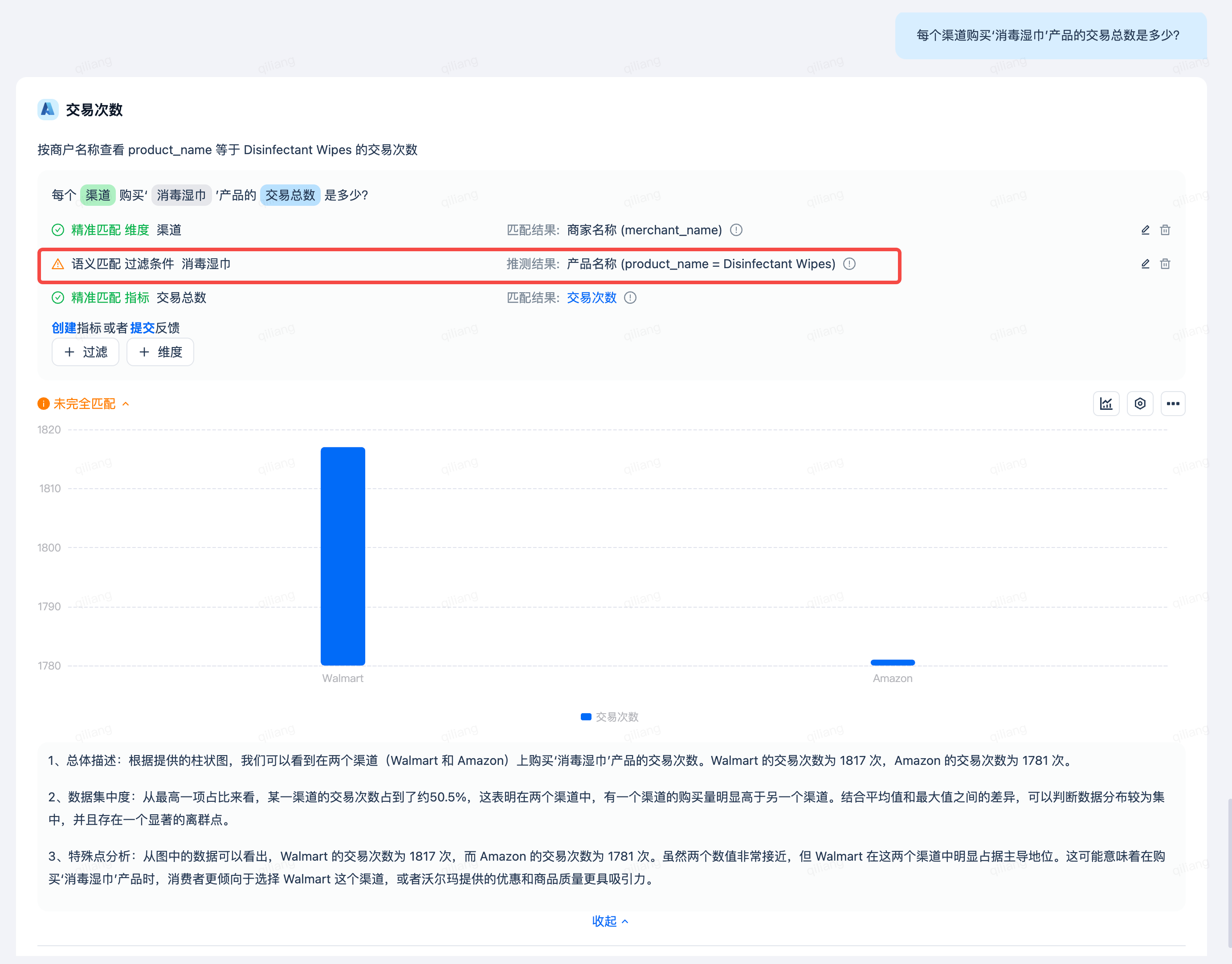
In the Lakehouse table, the product 'Disinfectant Wipes' is stored in English as 'Disinfectant Wipes.' When the user asks about '消毒湿巾,' DataGPT will automatically translate it to achieve precise matching, without requiring the user to input 'Disinfectant Wipes,' fully leveraging the advantages of the large model, making data analysis simpler.
Cleanup
After completing this quick start, you can clean up the objects created in Singdata Lakehouse.
Summary
Congratulations! You have completed this quick start!
Key Learnings
After completing this quick start, you now have a deep understanding of:
- How to use Singdata Lakehouse multi-table real-time synchronization to sync PostgreSQL data to Singdata Lakehouse tables, corresponding to the data extraction (E) and loading (L) in the ELT process.
- Using dynamic tables to process data, corresponding to the data transformation (T) in the ELT process.
- Visualizing and analyzing data conversationally through Singdata Lakehouse's built-in DataGPT.
Resources
Singdata Lakehouse Multi-table Real-time Synchronization
Singdata Lakehouse Dynamic Table
Singdata Lakehouse Q&A Data Analysis DataGPT
Singdata Lakehouse Studio: Web Development and Management Tools