December 25, 2023 Lakehouse Platform Release Notes
Overview
This release of the Singdata Lakehouse version (Release 2023.12.25) introduces a series of new features, performance optimizations, and fixes, as well as some behavior changes. The update will be gradually rolled out in phases to the following regions:
- Alibaba Cloud Shanghai Region
- Tencent Cloud Shanghai Region
- Alibaba Cloud Singapore Region
- Tencent Cloud Beijing Region
Note: The update will be completed within one to two weeks from the release date, depending on your region.
New Features and Optimizations
Performance Enhancements
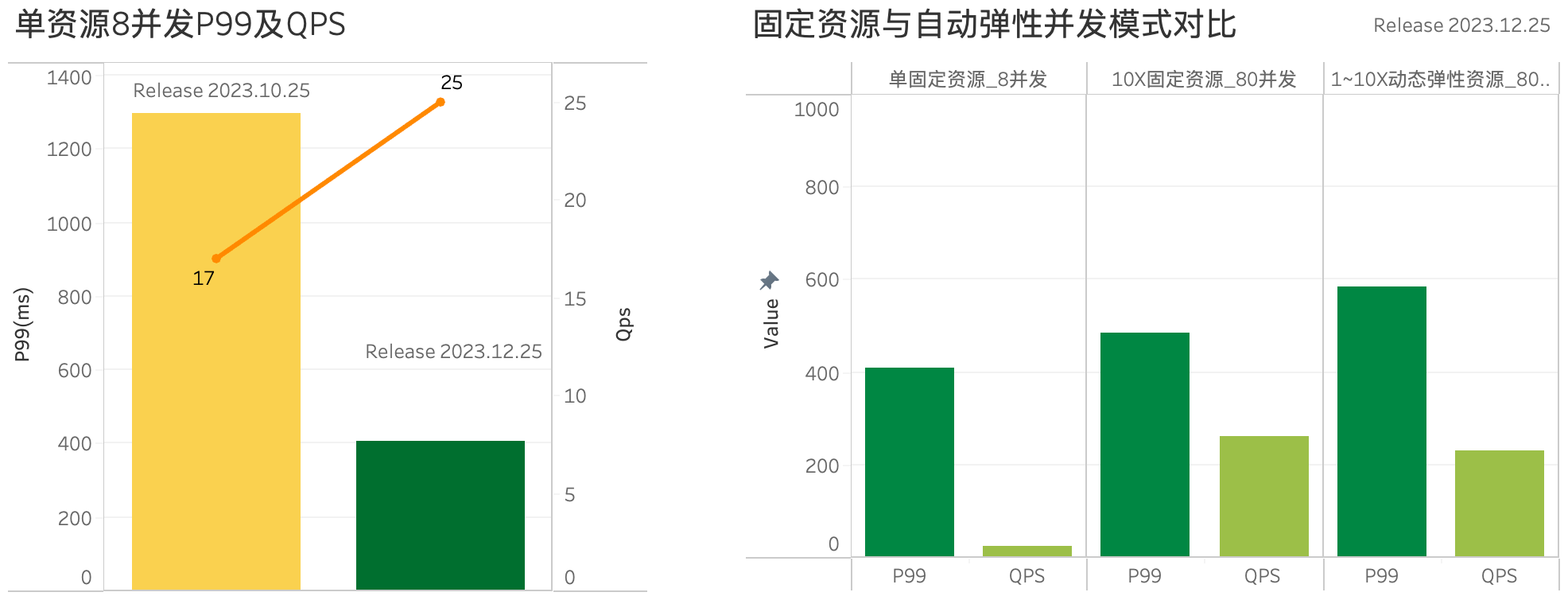
In multi-concurrent scenarios, resource scheduling has been significantly enhanced, improving concurrent query performance and performance stability during elastic scaling. Compared to the Release 2023.10.25 version, the QPS of a single resource instance on the SSBFlat 1G dataset increased by 47%, and the P99 query latency decreased by 68%. Additionally, in the automatic horizontal elastic scaling (Concurrency Scaling) mode, the P99 and QPS performance metrics of multi-concurrent queries further approach the performance of fixed resources planned for peak values, effectively reducing resource costs.
- Real-time Ingestion Service
- Upsert Real-time Writing: For primary key constraint tables, the real-time ingestion service now uses the primary key index cache to accelerate writing efficiency and automatically rotates the memory cache based on data hotness to balance the cost-effectiveness of large table updates.
- Hot Upgrade Support: The real-time ingestion service now supports hot upgrades, enhancing business continuity for real-time writing.
Real-time Processing Pipeline
- Incremental Materialized Views: Added "processing time" semantics, supporting filtering using
current_dateandcurrent_timestamp, providing the ability to filter late-arriving data similar to stream processing Watermark. - Table Stream: In addition to Append-Only change record capture, added support for capturing change records for DELETE/UPDATE operations.
Virtual Cluster Management
- State Management: When the cluster is in states such as "starting" or "scaling", added support for the "terminate change" function, allowing a rollback to the previous state before the change.
- Preload Cache: Added proactive cache capability for newly written data, improving real-time data cache hit rate and reducing jitter in real-time analysis queries.
- Elastic Concurrency: Supports analytical clusters reading cached data within the cluster during elastic scaling, reducing query quality fluctuations during resource elastic scaling and improving performance stability under multi-concurrency.
Job Management
- Job History Query: The Show Jobs command and the "Job History" module in the Web-UI now support querying and returning job history records within the last 7 days, up to a maximum of 10,000 rows.
- Job Diagnostics: The job list and job diagnostics page provide a breakdown of the duration of each stage during job execution, including compilation optimization, resource waiting, and actual running, and optimize the execution time proportion metrics of each operator within the job stage, enhancing self-service job diagnostics capabilities.
Data Lake (Volume)
- SQL Query VOLUME: Now supports using SQL to directly query VOLUME files, including csv, parquet, and orc formats.
- Image File Display: In the Web-UI SQL editor query results, supports displaying presigned URLs of image type files contained in volume objects as images.
External Function
- UDAF Function Support: Now supports custom Java/Python UDAF functions.
- Resource File Reference: External Function supports referencing resource files within Volume, simplifying the steps for developing and creating External Functions.
SQL & Built-in Functions
- ALTER Command Enhancements: Supports using
ALTER TABLE,ALTER SCHEMA,ALTER WORKSPACEcommands to modify the COMMENT content of objects. - Trailing Commas Support: Added support for trailing comma syntax style. Now, when specifying fields in CREATE TABLE and SELECT statements, it is allowed to add a comma after the last field or value, improving code management friendliness.
- NATURE JOIN Support: Supports using NATURE JOIN as a simplified syntax for inner joins, automatically performing implicit equi-joins based on columns with the same name in both tables without declaring join conditions.
- UUID Function: Added a UUID function for generating universally unique identifiers.
Data Protection
- TimeTravel: Supports setting the data retention period at the workspace level.
- Storage Encryption: Supports table-level storage encryption settings.
Drivers & Interfaces
- JDBC Download Interface: JDBC provides a full download interface for query results, supporting secondary consumption scenarios after query result export.
- SDK Download: Supports downloading Java/Python SDK through the central repository.
- Flink Connector: Connector for Flink supports CDC schema evolution during write operations.
Information Schema
- 【Preview】Provides the creation and refresh history view of materialized views for intelligent data model optimization (AutoMV)
- 【Preview】Default workspace-level Information_Schema, users within the space can be authorized to access
Data Sharing
- 【Preview】New data sharing feature, allowing cross-account data sharing by creating share objects through trial SQL and authorizing share objects. The scope and operations of shared data are constrained by the permissions defined by the data provider, who can cancel or modify the authorization at any time. Shared data does not need to be migrated, and data updates are visible in real-time.
Ecosystem
- 【Bug Fix】Resolved the COS storage adaptation issue when Apache Spark accesses Tencent Cloud Lakehouse service through Catalog SDK
- Added Metabase connection support