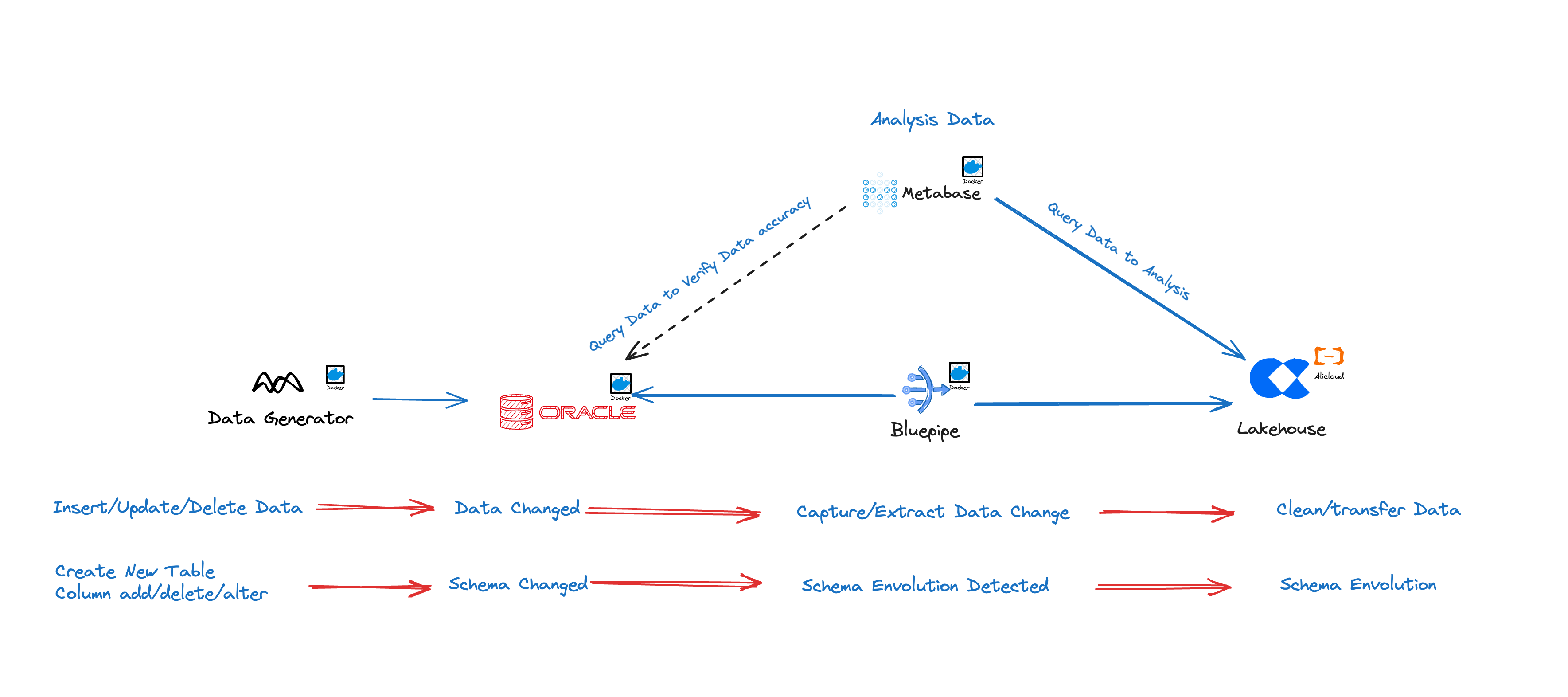
Real-time Data Synchronization from Oracle Database to Singdata Lakehouse via Bluepipe
Solution Introduction
For over 30 years, Oracle has held a significant position in the fields of relational databases and data warehousing. With the introduction of integrated systems such as Exadata, Exalytics, Exalogic, SuperCluster, and the 12c Database, the tight integration of storage and computing has enabled faster processing of large amounts of data using on-premises infrastructure. However, the quantity, speed, and variety of data have increased dramatically, and the cloud has brought more possibilities for modern data analysis. For example, by separating computing from storage, Singdata Lakehouse has achieved a new generation of cloud data platforms, enabling automatic and instant scaling of computing and storage with a share-nothing data architecture.
Solution Advantages
Bluepipe supports real-time data synchronization from Oracle to Singdata Lakehouse, especially in complex database environments with multiple instances and tables. Bluepipe achieves automated synchronization, greatly reducing the complexity and workload of manually configuring synchronization jobs. For source databases with tens of thousands of tables, Bluepipe can automatically configure synchronization tasks.
Out-of-the-box, Configuration Completed in 10 Minutes
Bluepipecan run on almost anyLinuxsystem, supportingx86andarmchips; common rack servers, laptops, and even Raspberry Pi can be used for deployment;- The minimal configuration process achieves optimal performance with default parameters.
Integrated Full and Incremental Synchronization, No Maintenance Intervention Needed
- Deep coordination of full and incremental synchronization, almost no daily maintenance operations required;
- Efficient data comparison and hot repair technology always ensure data consistency;
- Highly robust
Schema Evolution.
Push Data, Not Expose Ports
Bluepipeis deployed within your intranet along with your database, no need to expose ports externally;- Elastic
buffer sizetechnology automatically balances betweenthroughputandlatency.
Unique Advantages of Oracle Link
Bluepipe captures change data based on Oracle LogMiner. Meanwhile, it has been deeply optimized in the following aspects:
Deep Compatibility with DDL Behavior
Under the default LogMiner strategy, when DDL behavior occurs, subsequent DML operations on the related table cannot be correctly parsed, resulting in the inability to correctly capture changes.
Bluepipe maintains an automatic construction strategy for dictionary files, ensuring that correct incremental data can still be captured after table structure changes.
Large Transaction Optimization
Oracle Redo Log records the complete transaction process, while in business, only the data after commit is usually desired. Therefore, a buffer is needed during transmission to temporarily store uncommitted change records.
Bluepipe can easily handle large transactions of tens of millions of records on a single node based on unique memory management technology.
After the Oracle 12.2 version, the maximum length of table names and field names is supported up to 128 bytes. However, for various reasons, LogMiner still does not support DML parsing for tables with long names in instances without OGG LICENSE. For details, refer to the official documentation.
Bluepipe fully supports incremental data capture and delivery in such cases based on efficient stream-batch fusion technology.
Adaptation Support for RAC Architecture
Synchronization Effect
LAG: About 10 seconds
Synchronization speed: 20,000 rows/second
Implementation Steps
Install and Deploy Bluepipe
If you have not yet completed the installation and deployment of Bluepipe, please contact Singdata or Bluepipe.
Configure Synchronization Data Source in Bluepipe
Configure Oracle Data Source
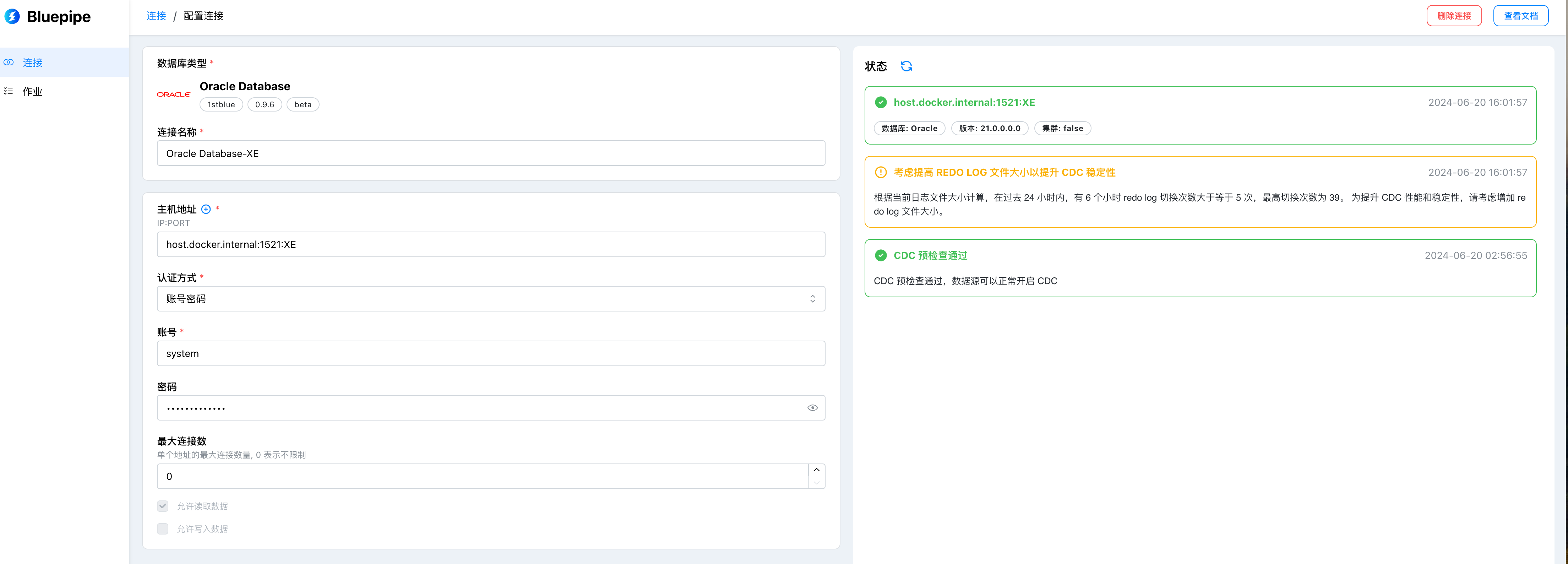
Configuration Item Description
| Configuration Item Name | Description |
|---|---|
| Connection String | The connection method of the data source, format: IP:PORT:SID, e.g., 127.0.0.1:1521:XE |
| Username | The username to connect to the database, e.g., C##CDC_USER |
| Password | The password corresponding to the username to connect to the database, e.g., userpassword |
| Connection Name | Custom data source name for easier management, e.g., local test instance |
| Allow Batch Extraction | Read data tables via query, supports row-level filtering, enabled by default |
| Allow Streaming Extraction | Capture database changes in real-time via CDC, enabled by default |
| Allow Data Writing | Can be used as a target data source, enabled by default |
Basic Functions
| Function | Description |
|---|---|
| Structure Migration | If the selected table does not exist on the target, automatically generate and execute the creation statement on the target based on the source metadata and mapping |
| Full Data Migration | Logical migration, sequentially scan table data and batch write to the target database |
| Incremental Real-time Sync | Supports common DML sync for INSERT, UPDATE, DELETE |
Configure Singdata Lakehouse as Target
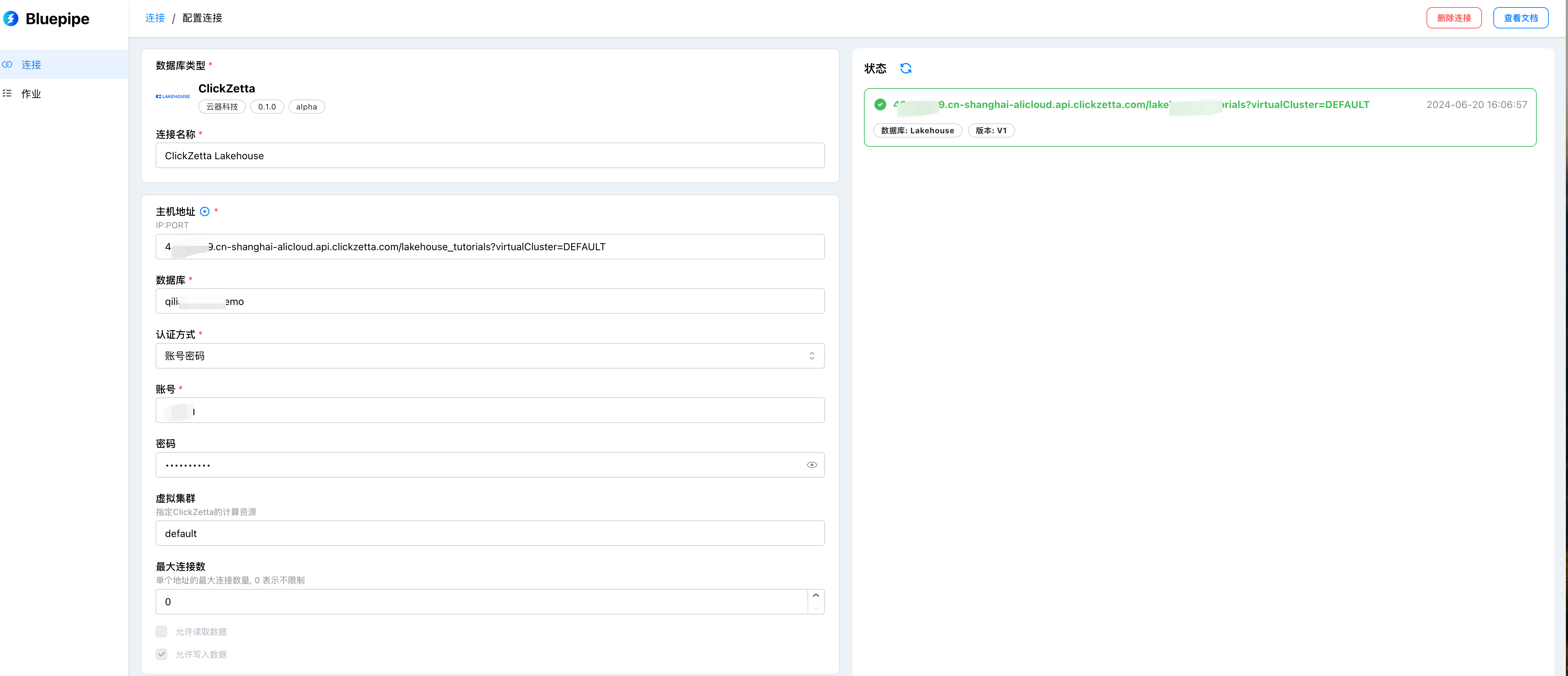
Configuration Item Description
| Configuration Item Name | Description |
|---|---|
| Connection String | Connection method for the data source, format: {instance}.{domain}/{workspace}, e.g., abcdef.api.clickzetta.com/quick_start |
| Virtual Cluster | Set the running virtual cluster, default value is default |
| Username | Username for connecting to the database, e.g., username |
| Password | Password corresponding to the username for connecting to the database, e.g., userpassword |
| Connection Name | Custom data source name for easier management, e.g., local test instance |
| Allow Batch Extraction | Read data tables via query, supports row-level filtering, not supported for extraction |
| Allow Streaming Extraction | Capture database changes in real-time via CDC, not supported for extraction |
| Allow Data Writing | Can be used as a target data source, enabled by default |
Create Table in Oracle Database
Create a New Sync Job in Bluepipe
Please note:
- When selecting the source, for the target table name {namespace}/{table}, you can replace {namespace} with your desired schema name, such as "bluepipe_oracle_staging".
- In the design phase, choose "Use CDC technology for real-time replication" for incremental replication.
The effect after successfully creating a new sync job is shown below:
 The new job will automatically start and begin full data synchronization, followed by continuous real-time incremental data synchronization.
The new job will automatically start and begin full data synchronization, followed by continuous real-time incremental data synchronization.
Data Generate
By running the following Python code, data is inserted into the Oracle source table employees in real-time:
import oracledb import random import time,datetime db_user = "SYSTEM" db_password = "" db_host = " db_port = "1521" db_service_name = "XE"
Connect to Oracle database and get cursor
connection = oracledb.connect(f"{db_user}/{db_password}@{db_host}:{db_port}/{db_service_name}") cursor = connection.cursor()
Total number of records to insert
total_records = 1000000 batch_size = 1000 # Number of records to insert per batch inserted_rows = 0 start_time = time.time() for batch_start in range(1, total_records + 1, batch_size): batch_end = min(batch_start + batch_size - 1, total_records) hire_date = random.randint(1, 200)
Construct insert statement
insert_sql = f""" INSERT INTO metabase.employees ( employee_id, first_name, last_name, hire_date, salary, department_id, email, phone_number, address, job_title, manager_id, commission_pct, birth_date, marital_status, nationality ) SELECT LEVEL, 'Name' || LEVEL, 'Surname' || LEVEL, SYSDATE - {hire_date}, 5000 + LEVEL * 1000, MOD(LEVEL, 5) + 1, 'employee' || LEVEL || '@example.com', '123-456-' || LPAD(LEVEL, 3, '0'), 'Address' || LEVEL, CASE MOD(LEVEL, 3) WHEN 0 THEN 'Manager' WHEN 1 THEN 'Analyst' WHEN 2 THEN 'Staff' END, CASE WHEN LEVEL > 1 THEN TRUNC((LEVEL - 1) / 5) END, 0.1 * LEVEL, SYSDATE - (LEVEL * 100), CASE MOD(LEVEL, 2) WHEN 0 THEN 'Single' WHEN 1 THEN 'Married' END, CASE MOD(LEVEL, 4) WHEN 0 THEN 'China' WHEN 1 THEN 'USA' WHEN 2 THEN 'UK' WHEN 3 THEN 'Australia' END FROM DUAL CONNECT BY LEVEL <= {batch_size} """
Execute insert
cursor.execute(insert_sql) connection.commit() inserted_rows = inserted_rows + batch_size end_time = time.time() total_time = end_time - start_time average_insert_speed = inserted_rows / total_time print(f"Total rows inserted: {inserted_rows}") print(f"Average insert speed: {average_insert_speed:.2f} rows/second") time.sleep(0.5) end_time = time.time() total_time = end_time - start_time average_insert_speed = inserted_rows / total_time print(f"Total rows inserted: {inserted_rows}") print(f"Average insert speed: {average_insert_speed:.2f} rows/second")
Close cursor and connection
cursor.close() connection.close()