NinjaVan's Journey from Traditional Spark to Singdata Lakehouse
0. Introduction
This case study examines how NinjaVan significantly enhanced its data infrastructure by migrating from a traditional self-built Spark architecture to Singdata's next-generation Lakehouse architecture. Key business benefits and implementation insights include:
Achieving query acceleration directly on existing data lakes without migration
Seamless compatibility between Spark (pySpark) and Presto workloads
Dramatic improvements in BI analysis performance and stability
Effective handling of peak-valley resource demands
Cost reduction through unified architecture replacing Lambda components
1. Company Background
NinjaVan, established in 2014 and headquartered in Singapore, has become one of Southeast Asia's top three logistics companies. Specializing in technology-driven e-commerce logistics, NinjaVan provides comprehensive cross-border shipping, customs clearance, and delivery solutions across the region. The company has expanded to operations in six countries with 43,000 employees, including over 200 IT personnel and dozens of data analysts distributed across these locations.
Previously, NinjaVan relied on an open-source self-built big data platform. However, as data complexity and query demands grew, this architecture increasingly struggled to support business growth, prompting the search for a managed data platform solution that could enhance capabilities while reducing costs.
2. Pre-Migration Architecture Analysis
2.1 Existing Infrastructure
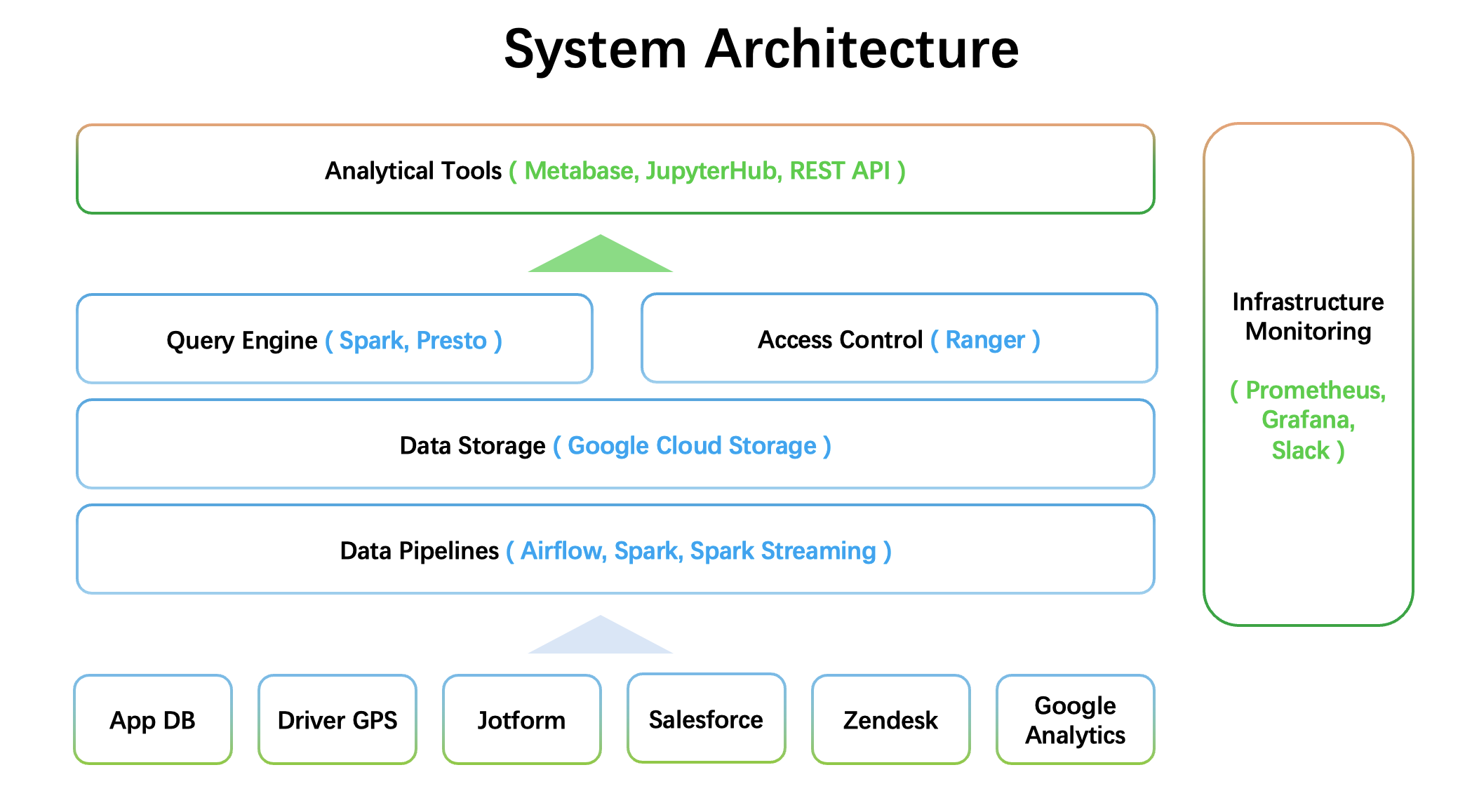
NinjaVan builds a centralized data platform based on business data on GCP, providing Regional Business Intelligence business report analysis services. Previously, NinjaVan supported these applications and analyses by assembling a data platform based on Lambda architecture, using multiple open source Big Data components such as Spark, Spark Streaming, Kafka, Airflow, Ranger, Presto, Metabase, and JupyterHub.
The architecture link is written to the GCS Data lake through Kafka + Spark Streaming Data Transmission Service and stored as a DataLake DeltaTable. Then, based on the Delta format data on the data lake, Spark is scheduled for offline calculation through Ariflow to generate Pure Parquet Datawarehouse Table. Analysis is supported by the combination technology stack of Presto + HMS + Parquet, and interactive analysis is connected to Metabase BI reports. Based on this data architecture, some Spark data science and data mining applications submitted by JupyetrHub are accompanied. This is also the mainstream data architecture in the industry, supporting NinjaVan's long-standing business intelligence development.
2.2 Key Challenges
Over the past decade of NinjaVan's exponential growth, the original data platform has increasingly struggled to address the efficiency challenges and escalating costs associated with their massive accumulated data volumes. The data infrastructure team now faces several critical obstacles in supporting business operations and developing new applications:
2.2.1 Challenges to support stable and timely BI online analysis needs
Performance Degradation Under Growing Data Volumes As NinjaVan's data volumes expanded, Presto's query performance deteriorated significantly, particularly for complex operations involving multi-table joins and aggregations. Under fixed resources, these performance issues led to extended query times, increased latency, and higher resource consumption—ultimately compromising the user experience of data applications and preventing timely business analysis.
Inflexible Resource Scaling To address performance demands, Presto required additional computing nodes to handle increased query pressure. However, unlike modern cloud-native systems, Presto's resource expansion mechanism proved cumbersome and time-consuming. The process required complex manual coordination and configuration adjustments between nodes to maintain consistency and low latency. With expansion response times exceeding 10 minutes, the system couldn't efficiently adapt to business concurrency needs or handle irregular scaling demands.
Limited Fault Tolerance Presto's weak fault tolerance presented significant operational risks in large-scale cluster environments. When node failures occurred, queries would often fail completely or require full re-execution. The time-intensive data recovery process further extended service downtime, creating reliability issues that impacted business continuity and decision-making capabilities.
2.2.2 Inefficient Resource Management for Peak-Valley Workloads
NinjaVan's operational reality involved varying workload intensities—with a tendency toward offline ETL processing during nighttime hours and higher volumes of BI analysis and queries during business hours, though these patterns weren't strictly segregated. The fragmented architecture of disparate open-source big data solutions, coupled with non-integrated resource management systems, made precise resource allocation extremely challenging.
During periods of heightened demand, the team faced a difficult choice: either over-provision resources (incurring unnecessary costs) or risk insufficient capacity to handle traffic surges (compromising performance). Conversely, when demand naturally decreased, the platform's inability to dynamically release resources resulted in significant waste, with idle computing power continuing to consume budget without delivering business value.
This inflexibility in resource scaling created a persistent cost inefficiency that grew increasingly problematic as NinjaVan's data operations expanded.
2.2.3 Growing Architectural Complexity Hampering Operational Efficiency
In their efforts to efficiently process massive logistics order datasets, NinjaVan had progressively introduced additional big data components to address emerging challenges in their original platform architecture. However, this layering of various technologies created a highly complex ecosystem that became increasingly difficult to operate and maintain.
The fundamental issue stemmed from the assembled nature of the architecture—each component was independently developed and operated with potentially divergent optimization priorities and design philosophies. When business requirements necessitated adjustments across these interconnected systems, such as rebalancing the trade-offs between data freshness, query performance, and infrastructure costs, the team faced substantial challenges:
Configuration changes required complex modifications across multiple systems
Development work frequently needed duplication across different components
Integration points between systems created additional complexity
Adjustments became increasingly time-consuming and resource-intensive
This architectural complexity significantly extended adaptation cycles and often delivered suboptimal results, limiting NinjaVan's ability to respond quickly to changing business requirements while simultaneously driving up operational costs.
2.2.4 Migration Obstacles for Legacy Workloads and Massive Datasets
While exploring alternatives to efficiently process their growing logistics order data, NinjaVan evaluated several modern data architectures to improve both offline processing and online analysis performance. However, migrating to platforms like BigQuery or Alibaba Cloud's big data ecosystem presented substantial compatibility challenges and technical barriers.
The company's extensive investment in existing workflows created significant migration hurdles:
Thousands of production Airflow pySpark jobs represented critical business logic
Numerous business reports relied on Presto-specific SQL syntax in Metabase
Vast quantities of historical data would require transfer and validation
SQL dialect differences would necessitate extensive query rewrites
Complex ETL processes would require reengineering and verification
Each migration attempt faced prohibitive costs in terms of engineering effort, business disruption risk, and potential data inconsistencies during transition periods. The validation alone—comparing results between old and new systems—would consume substantial resources.
Given these constraints, NinjaVan needed a solution that could seamlessly integrate with their existing multi-cloud data lake architecture while minimizing code changes and eliminating the need for massive data migration.
2.3 Transformation goals
NinjaVan required a Lakehouse-based integrated data platform that would minimize migration overhead while delivering superior performance and dynamic resource management. The ideal solution needed to balance multiple critical factors: reducing migration costs, enhancing analytical capabilities, optimizing infrastructure expenses, and ensuring operational simplicity—ultimately providing a comprehensive and sustainable foundation for the company's evolving data needs.
2.3.1 Choosing the Right Solution Partner
After thorough evaluation, NinjaVan recognized that continuing with their patchwork open-source approach would not address their fundamental challenges. They needed a transformative data platform architecture to replace their Lambda composite system while minimizing migration costs.
Singdata, founded in 2021 by veterans from Oracle, Microsoft, Alibaba Cloud and ByteDance, offered the ideal solution with their Lakehouse integrated platform. As pioneers of "General Incremental Computing," Singdata's technology delivers up to 10x performance improvement over traditional systems like Spark while reducing total cost of ownership to just 1/5-1/3 of conventional alternatives.
The platform's true multi-cloud capability—supporting all major providers and on-premises deployment—perfectly aligned with NinjaVan's infrastructure requirements, enabling a streamlined migration path from their legacy Spark-based systems to a modern, AI-ready data infrastructure.
3. Singdata's Solutions
3.1 Evolutionary path
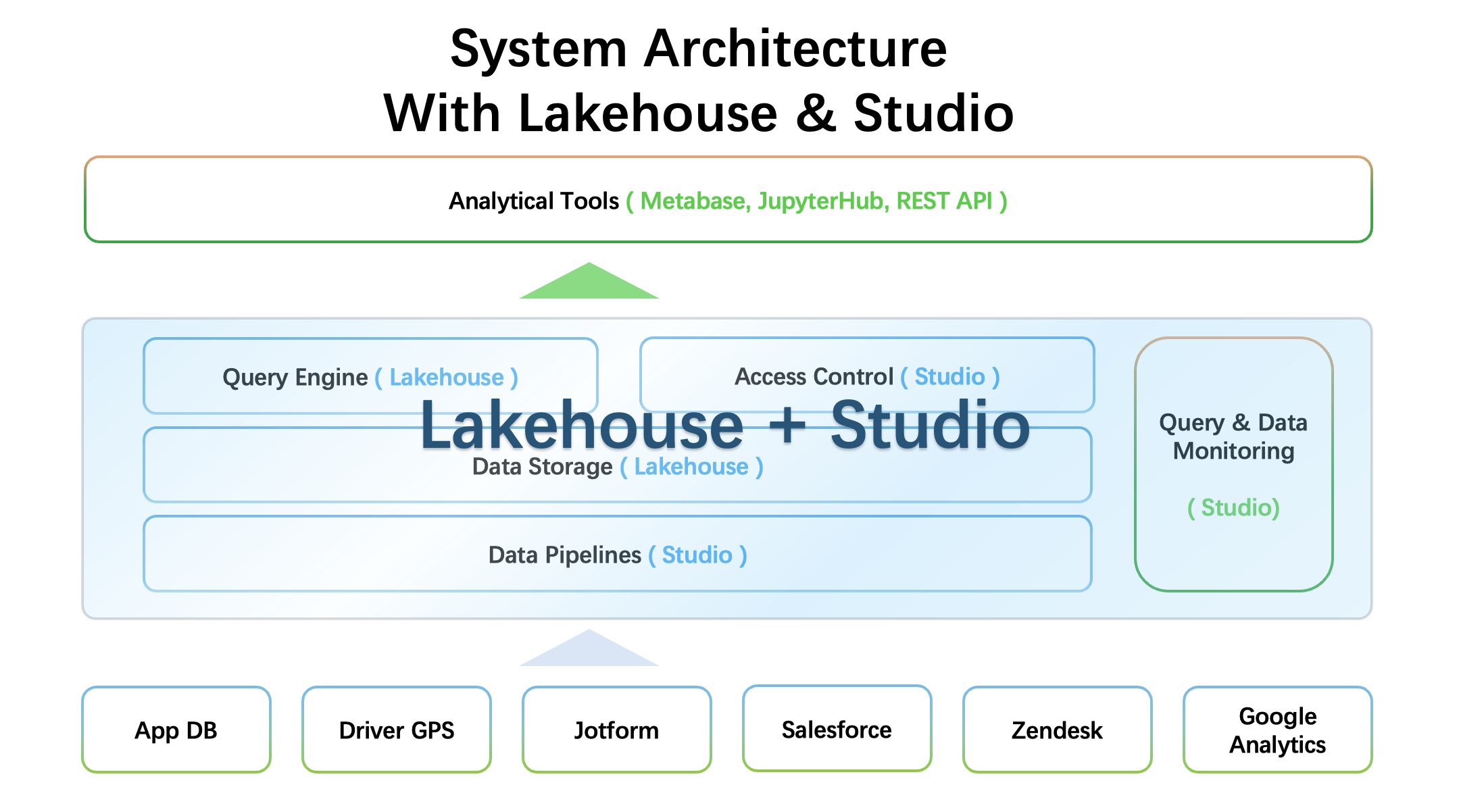
After NinjaVan upgraded its data platform based on Singdata products, it adopts an integrated architecture of lake and warehouse. With strong data lake compatibility and excellent on-lake query acceleration, combined with multiple technical optimizations, NinjaVan can handle large-scale offline computing and online BI analysis at a lower cost with a single engine. The Singdata engine is embedded in the data architecture upgrade plan of Data Lake. Specifically, the new data platform has made significant technological innovations in the following aspects to achieve this goal. This is mainly based on the following considerations.
It is necessary to use the design of the lake-warehouse integrated storage and calculation separation architecture, so that the Singdata engine can be directly embedded in the customer's existing Data lake, eliminating the need for data transfer and directly accessing metadata to form a unified metadata foundation level
Directly compatible with existing workloads, whether it is Spark tasks or SQL, compatibility and progressive migration can be achieved
Excellent engine performance is required to enable the customer's BI team to enjoy real-time data analysis results in seconds, enhancing business real-time
The new platform needs to have the ability to dynamically change the elastic cluster scaling according to the load, support the exploration demand of dynamic business peaks, use on demand, and respond in milliseconds
3.1.1 Preserving Data Lake Investments While Adopting Advanced Engine Technologies
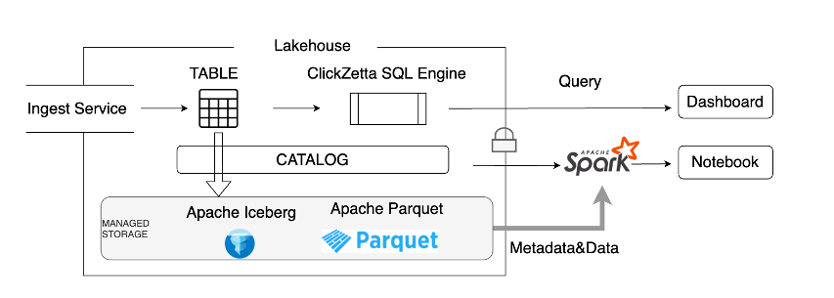
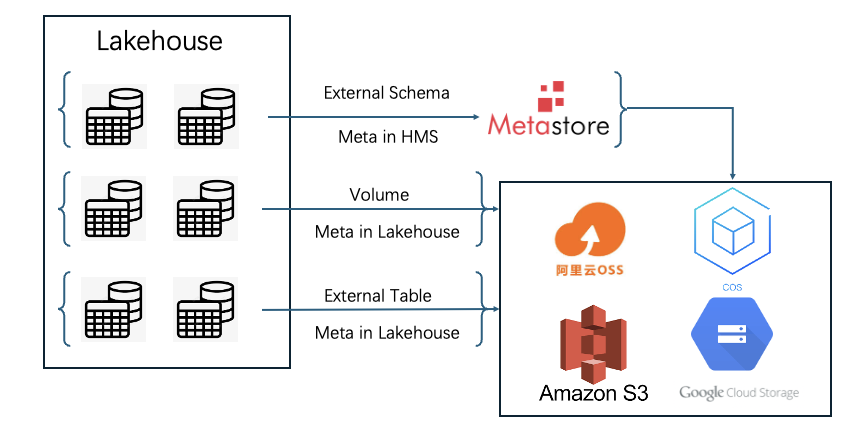
NinjaVan stores massive stock data for nearly 10 years. The cost of relocating data is extremely high. Similarly, online business cannot be interrupted due to relocation, which leads to two key decision points. ETL's stock DeltaLake data requires a low-cost compatibility solution, and BI online translation also requires a low-cost query acceleration solution directly based on the lake. Both hope to minimize migration costs. Singdata provides powerful data lake compatibility and openness, multiple data lake embedding solutions for query acceleration, and embedding based on data lake does not require relocating stock data. Similarly, it can be smoothly extended to Lakehouse's internal table data (also based on lake-warehouse integrated storage) to obtain better query performance.
External Schema : Data lake file + Meta library Lakehouse embedding scheme (Parquet File on DataLake + HMS)
Volume : Data lake file Lakehouse embedding solution (Parquet File on DataLake)
External Table : Data lake file + Meta file Lakehouse embedding solution (Delta File on DataLake)
Singdata's Data lake compatibility enables the Lakehouse engine to directly embed the customer's existing Data lake, eliminating the need to migrate massive stock data and directly accessing metadata to form a unified metadata management
3.1.2 Directly compatible with existing workloads, requires Zettapark compatibility + sqlglot compatibility
NinjaVan's original Airflow solution had thousands of ETL tasks and thousands of stock reports on Metabase, making migration very difficult. Singdata greatly reduces the migration cost of ETL offline computing tasks and BI online analysis reports while being compatible with most workloads through the compatibility of Zettapark and sqlglot.
3.1.2.1 Zettapark
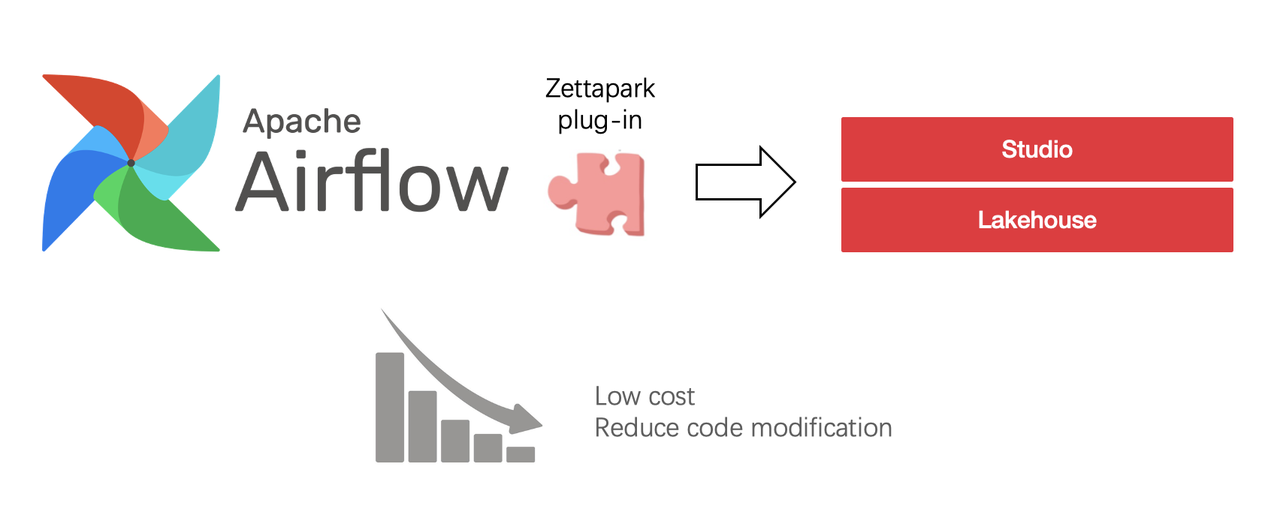
Zettapark is a Python library for processing Singdata Lakehouse data. It provides an advanced Python API for executing SQL queries, manipulating data, and processing results in Singdata Lakehouse. Zettapark makes it easier and more efficient to use Singdata Lakehouse in Python. Users can use Zettapark to perform SQL queries, manipulate data, and process results, just like using pandas in Python.
Executing pandas operations in Zettapark will be translated into SQL and executed in Singdata Lakehouse, achieving distributed computing.
df_filtered = df.filter((F.col("a") + F.col("b")) < 10)SELECT a, b
FROM (
SELECT col1 AS a, col2 AS b
FROM VALUES (CAST(1 AS INT), CAST(3 AS INT)), (CAST(2 AS INT), CAST(10 AS INT)))
WHERE ((a + b) < CAST(10 AS INT)) LIMIT 10;Zettapark supports business migration at a very low cost (less than 1% code change).
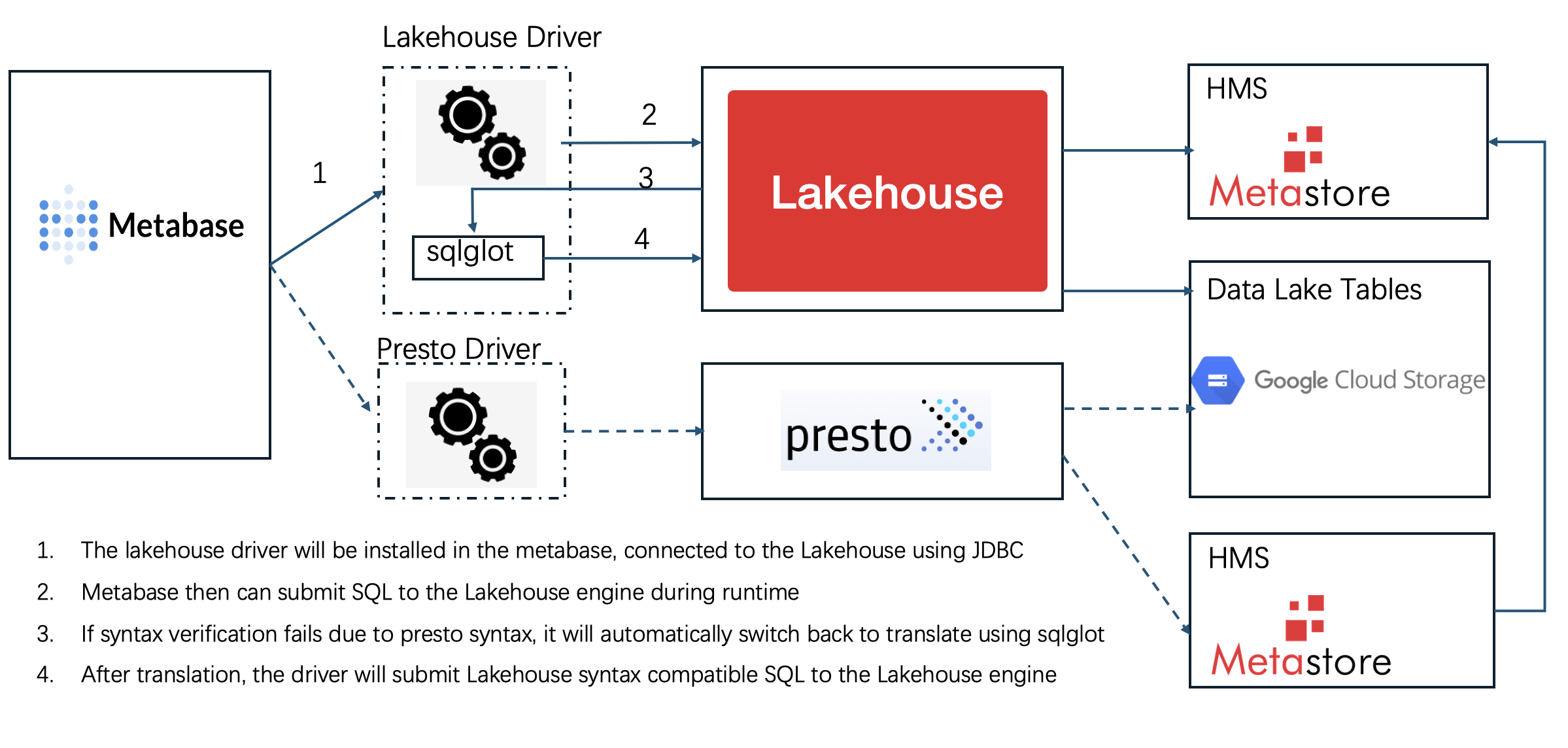
3.1.2.2 sqlglot
Based on this solution, users only need to replace PrestoDriver with Singdata Driver without modifying the stock report on Metabase
3.1.3 Demand extreme performance and elasticity to complete BI-oriented stability and query latency optimization
In order to further improve the response efficiency of ad hoc queries, Singdata has also made a lot of optimizations for query performance, such as query plan optimization, using Share-everthing architecture to improve read and write performance, operator optimization, vector execution, etc., thus achieving a significant improvement in query performance. Excellent engine performance allows NinjaVan's BI team to enjoy the analysis results of significant performance improvement and enhance business real-time
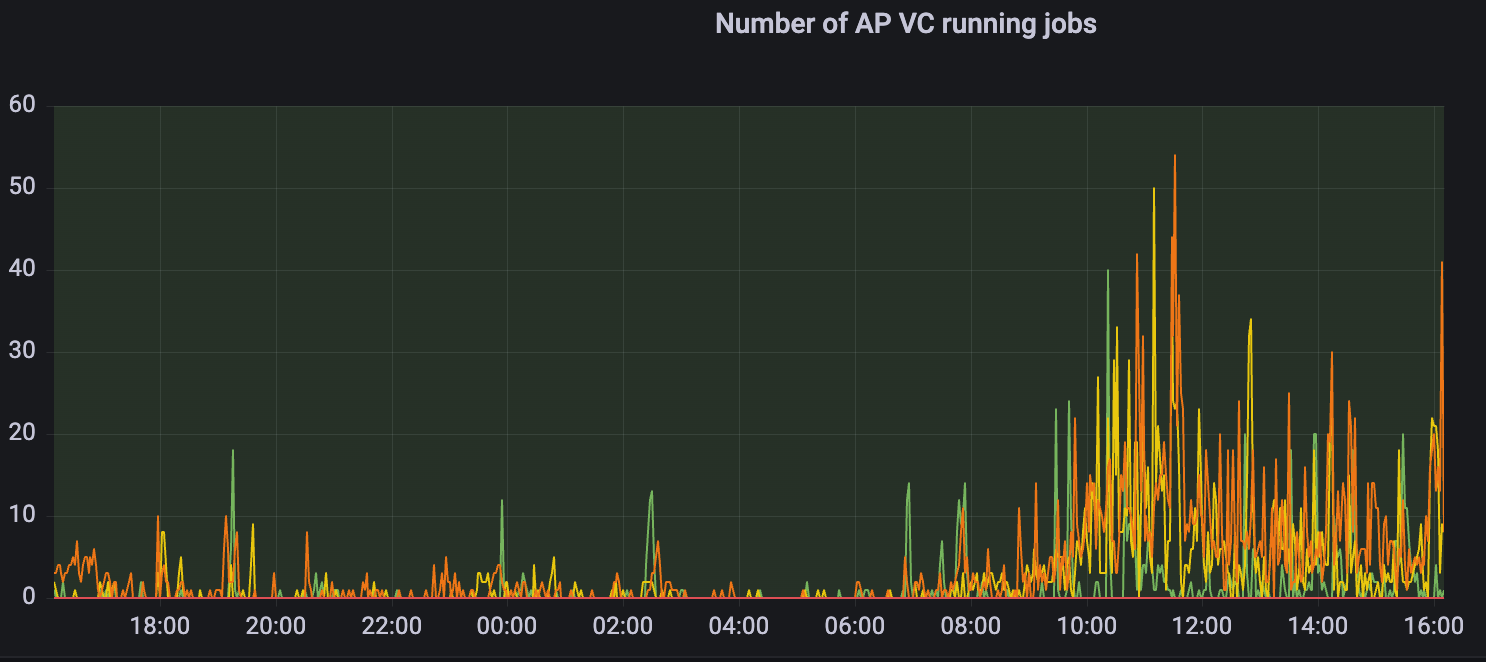
3.1.4 Establish a new resource usage model for load elasticity through inventory management capabilities and elastic volume expansion and contraction capabilities
3.1.4.1 Inventory management capabilities
Lakehouse's inventory management capability supports dynamically identifying inventory occupancy based on inventory levels, maintaining an appropriate proportion of actual inventory slightly higher than the proportion of resources actually used. Based on this capability, Lakehouse can dynamically and automatically expand corresponding resources during business peaks when inventory is sufficient, while also maintaining a low resource inventory after business downturns to reduce unnecessary cost expenditures.

Green represents the purchased cloud resources (i.e. inventory), and orange represents the resources actually used by the virtual computing cluster
3.1.4.2 Compute resources (Virtual Cluster) elastic volume expansion and contraction
Virtual Cluster (VC or cluster for short) is a computing resource object provided by Singdata Lakehouse for data processing and analysis. Virtual Cluster provides CPU, memory, local temporary storage (SSD media) and other resources required to execute SQL jobs in Lakehouse. Cluster has the characteristics of fast creation/destruction, expansion/contraction, pause/recovery, etc.
Lakehouse supports multi-concurrent queries through horizontal elastic scaling. On the premise of sufficient inventory, Lakehouse supports second-level scaling of VC for multiple replicas to adapt to scenarios of sudden increase in BI concurrency during business peaks (such as NinjaVan's early and early weeks)

In addition to the above points, the new data platform uses a set of engines to unify the three computing forms of offline, real-time, and interactive analysis, unify data storage and management, unify data development, and unify data services. Therefore, NinjaVan can develop offline and online analysis tasks simultaneously with a set of SQL in an integrated data warehouse architecture, reducing development difficulty and operation and maintenance costs, as well as data redundancy and inconsistency. It also paves the way for future performance improvement and cost optimization of real-time integration and migration transformation.
4. Effect and value of data platform upgrade
NinjaVan actively explores new data platform solutions to support 10 years of rapid growth at low cost, thus meeting the optimal solution for Business Intelligence to obtain data processing timeliness, performance, cost, and ease of use. By adopting Singdata's Lakehouse integrated data platform product, NinjaVan has achieved the following main effects and values.
4.1 Technical value
4.1.1 Query acceleration
In the ETL scenario, Lakehouse accelerates offline computing on the lake based on the Delta file of Data Lake, which improves performance by 6X times compared to Spark. It can also be extended to Lakehouse's internal table data at a low cost, based on cloud object storage and Lakehouse's self-developed compaction and meta stats to obtain better query performance.
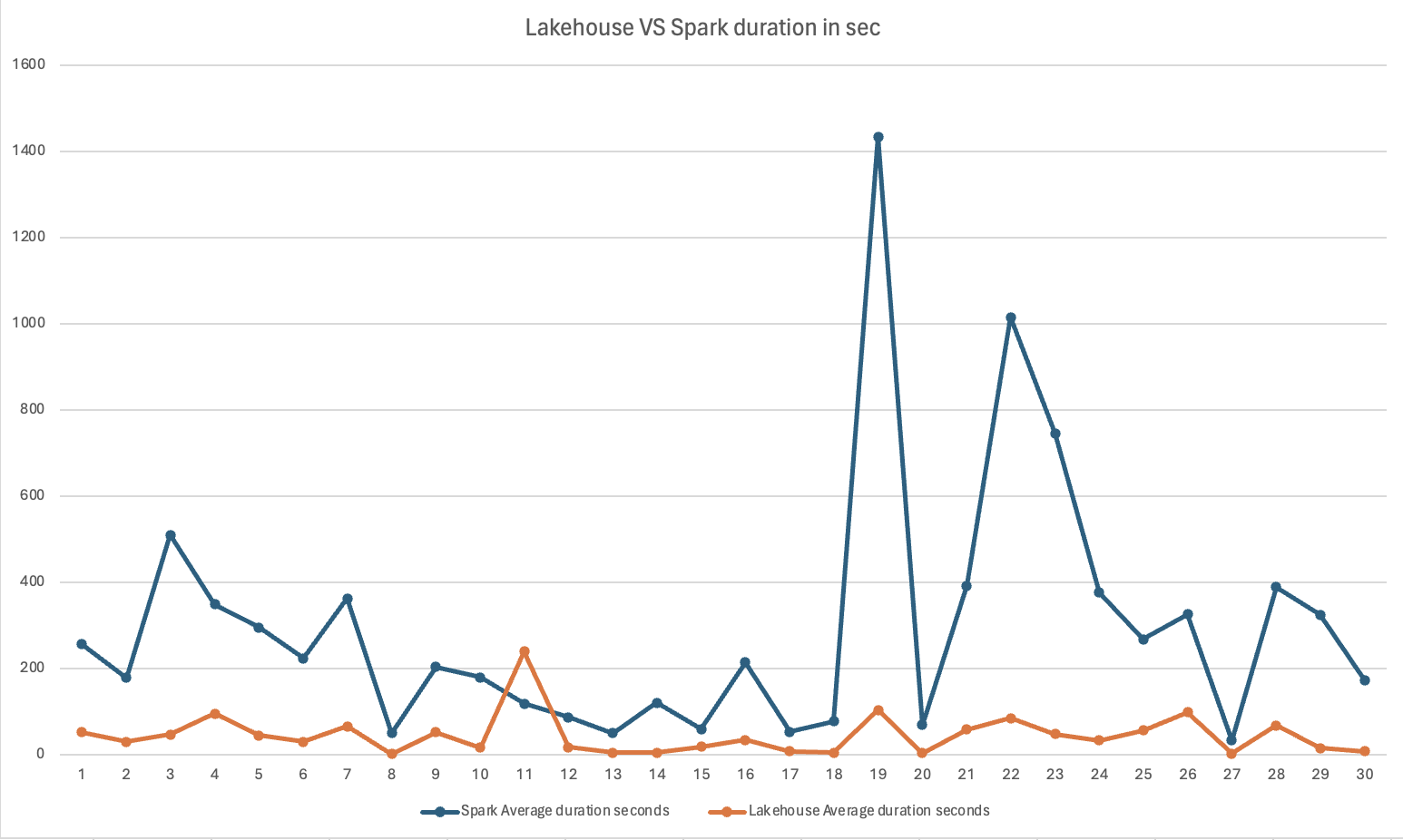
Spark Sum duration seconds | Lakehouse Sum duration seconds | Singdata Improvement |
8,938.80 | 1,347.00 | 564% |
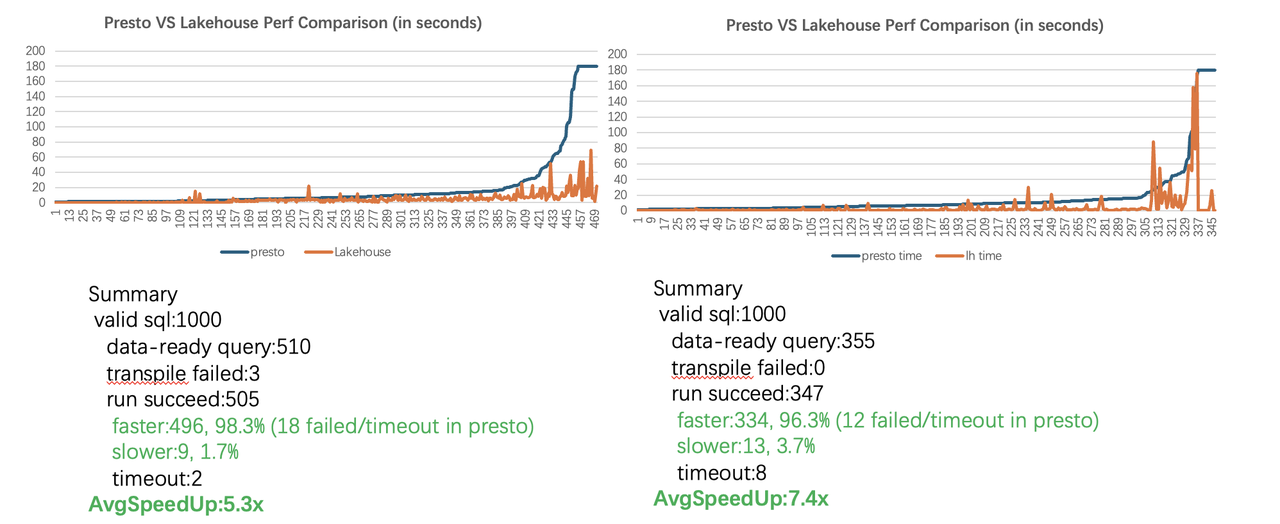
In the BI scenario, Singdata accelerated the lake BI online analysis query through ExternalSchema, achieving an average performance improvement of 5.3X times and 7.4X times respectively in randomly sampled 1000 query torture testing and 1000 query torture testing scenarios with similar patterns. The overall performance is improved by 2-10X times compared with the original Presto query scheme
4.1.2 Cost reduction
Dynamic inventory management greatly solves the peak and valley situation of NinjaVan (night ETL, daytime BI query). Taking BI with obvious peak and valley fluctuations as an example, inventory management can support purchasing ECS to pull up Lakehouse computing resources within 2 minutes . When the inventory is sufficient, the expansion of different VCs can support pulling up resources within 1 second . Lakehouse reduces the total cost to one-third through better performance and better resource control.
4.1.3 Progressive migration
Through Lakehouse, NinjaVan smoothly accesses existing workloads without the need to relocate data . Based on Lakehouse's Data Lake compatibility and ecological compatibility solution, the original solution of NinjaVan has a code change of less than 1% for thousands of ETL tasks, and thousands of existing reports on Metabase do not need to be modified and can be used directly through replacement LakehouseDriver+sqlglot. It also provides space for further performance and cost optimization in the future.
4.2 Business value
4.2.1 Stable and fast BI reports provide stronger support for business peak periods
The performance improvement of Lakehouse and the rapid elastic expansion ability of business peaks greatly enhance the experience of NinjaVan's centralized analysis of large amounts of business data at the beginning of the month and week, significantly reducing the opinions and complaints of BI business personnel and NinjaVan partners about slow and delayed data analysis during peak periods.

4.2.2 Improve development efficiency and simplify usage threshold
The integrated architecture of the platform eliminates the need for NinjaVan to maintain complex Big data components. In the new platform, users can use a set of SQL for data development, as well as LakehouseStudio's business observation and alarm functions, making the entire data development work simpler, business collaboration more efficient, and allowing NinjaVan's BI department to focus more on the analysis and mining of data value itself.
5. Summary and Outlook
NinjaVan's Big data platform construction has gone through 10 years with the development of the enterprise, forming the current architecture based on open source self-built Spark+Flink+Presto+DataLake, which has problems of low performance, complex architecture, and high maintenance costs. When NinjaVan was thinking about the evolution of the next generation data platform, it considered exploring with Singdata. After PoC and partial production verification, a new generation architecture based on lake-warehouse integration, high performance, offline real-time integration was formed, and finally achieved a business effect of 6 times ETL performance improvement and 2x-10x BI performance improvement. The upgrade process fully considered the protection of original investment and low business risk, achieving compatibility mode introduction of new engines and seamless business switching.
At the same time, after careful consideration, we abandoned the fully self-built model and adopted a mainly managed and self-built supplementary approach to improve SLA and release manpower, focusing more on business and innovation.
NinjaVan has achieved significant results in terms of user experience and cost in current business scenarios through Lakehouse. In the future, based on the new generation of open Data + AI architecture, NinjaVan will continue to explore and apply new technologies and tools, continuously improve the real-time and global insights of data, and utilize LH's AI capabilities to mine and explore the value of non-Structured Data, providing more powerful support for enterprise decision-making.
